
文章圖片
文章圖片
【導讀】DeepMind新研究揭示了當與推理無關的想法 , 被直接注入到模型的推理過程中時 , 它們卻難以恢復 , 而且越大的模型越難恢復 。 一旦被無關或錯誤信息干擾 , 大模型可能變成固執杠精 , 連糾正提示都救不回!
20世紀初 , 據說存在一匹會算數的馬 , 被稱為「聰明的漢斯」 , 但經過心理學家馮斯特的研究 , 最終發現這匹馬其實是通過觀察提問者無意識的肢體語言(如呼吸變化)來停止踩蹄 , 并非真正理解數學 。
如今 , 我們發現 , 大模型會呈現出推理行為 , 甚至還存在Aha時刻這樣的「頓悟現象」 。
這會不會是大模型表現的如同「聰明的漢斯」那樣 , 依賴提示詞中的表面模式 , 而非真正具有了推理能力 , DeepMind的最新研究揭示了大模型推理能力令人擔憂的一面 。
論文鏈接:https://arxiv.org/abs/2506.10979
大模型無法識別推理中犯的錯首先將大模型的的無效思考進行了分類 , 第一類稱為無信息內容 , 例如當我們使用推理大模型時 , 偶然會發現大模型的思路跑偏 。
【推理AI致命弱點,大模型變「杠精」,被帶偏后死不悔改】例如大模型化身廢話文學大師 , 在推理過程中輸出正確但與實質解題無關的信息 , 例如問大模型如何計算地球到月球的距離?
模型在推理過程中顯示:嗯 , 這個問題很有意思 。 首先我要認真思考 , 分步驟解決 。 回憶下相關知識 , 可能需要某些公式 。 仔細想想 , 答案應該藏在某個地方 。
第二類被稱為無關內容 , 即思考過程完全偏離原問題 , 回答與當前無關的問題 。
第三類是誤導內容 , 即問題被微妙篡改 , 導致要解決的問題不是提示詞給出的那個 , 第四類可稱為錯誤內容 , 即推理過程中存在事實錯誤或邏輯錯誤 , 導致回答出錯 。
該研究首先考察了不同大模型分辨這四種無效思考的準確性 。
圖1 用不同參數大小的蒸餾Deepseek R1模型 , 對無效思考內容進行分類的準確性
結果出乎意料 , 圖1的左邊顯示的是模型識別無效思考的準確性 , 結果顯示對于錯誤內容類型的無效思考 , 不管是7B還是70B的大模型 , 其識別準確性都不到三成 , 這意味著推理大模型目前無法處理自身推理中的錯誤 , 也無法獨立驗證其推理過程是否正確 。
而不同參數大小的推理大模型對無關內容 , 無信息內容的識別程度都很高 。
越大的模型越難恢復圖1右邊顯示的結果 , 則顛覆了大模型越大效果越好的常規 。
當研究人員向大模型強行注入無效思考后 , 大模型在從注入的無效思考恢復時 , 并非參數量越大的大模型恢復概率越高 , 尤其在短無關內容(Irrelevant 10%)上 。
即大模型反而比小模型更容易被帶偏 , 仿佛大模型也會如人類一樣「走神」 。
對比大模型面對注入不同類型的無效思考后的恢復表現 , 模型性能斷崖下跌(最大跌幅92%) , 尤以無關內容(Irrelevant)和誤導內容(Misdirecting 100%)最甚 。
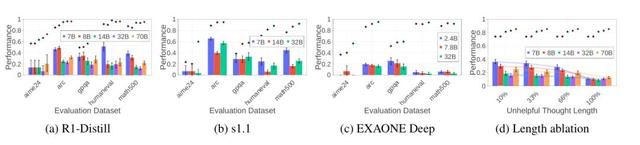
具體到數學 , 科學及編程三類常見的大模型基準測試中 , 當研究人員向大模型推理過程中插入了10%的無關內容后 , Deepseek R1 , S1及EXAONE這三種大模型都出現了上述的反規模效應(Inverse-scaling) 。
圖2d對比了不同插入無效思考的長度差異會對模型恢復能力帶來的影響 , 結果顯示干擾文本越短(10%長度) , 小模型恢復優勢越顯著;干擾越長(100%) , 規模效應趨于平緩 。
圖2 不同的大模型在數學 , 科學即編程基準數據集上面對推理過程中插入的無效思考的恢復能力
當研究人員在大模型的思考過程中施加外部干預 , 即增加提示詞:但等等 , 我再想想(But wait let me think again)后 , 模型果然表現出了一定程度的啊哈時刻 。
模型有100%的概率從誤導信息類的無效思考中恢復 , 對于其它幾類也有所幫助(圖3a) , 然而相比在沒有注入錯誤思考的時的模型性能 , 還是存在限制下降的 , 尤其是對于誤導信息和錯誤內容兩種無效思考(圖3b) 。
圖3 通過引入阿哈時刻 , 衡量大模型面對各類無效的恢復能力
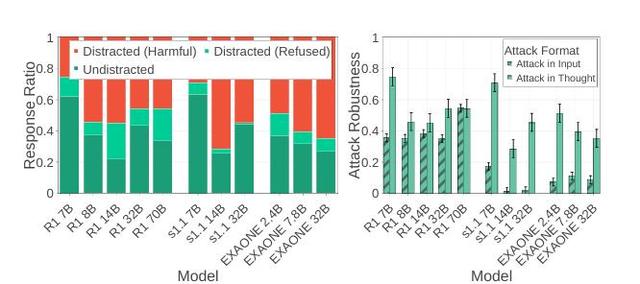
推理大模型的上述缺陷 , 為黑客攻擊大模型提供了新的軟肋 , 黑客可以通過污染AI的\"思考過程\"(而不是直接改問題)來操控答案 。 面對這種攻擊 , 小模型反而比大模型有更強的抵抗力 。
當攻擊者將將有害請求偽裝成模型的思考片段(如虛構故事設定)后 , 如圖4a所示 , 小模型(7B)攻擊成功率最低(深綠「未分心」占比30%) , 而大模型(32B+)更易輸出有害回答(紅色「有害回答」占比60%) 。
圖4b對比了傳統的在輸入過程中攻擊大模型與在思考過程中攻擊 , 結果與之前的觀點一致 , 即傳統輸入攻擊(Attack-in-Input):大模型防御更強 , 而面對思考注入攻擊(Attack-in-Thought):大模型更脆弱 , 呈現反規模效應 , 這意味著對于思考過程 , 推理大模型需要設立單獨的防御機制 , 不能依靠參數量來確保模型的安全性 。
圖4 推理大模型面對不同類型的攻擊時的表現
該文的開篇 , 筆者提到「聰明的漢斯」 , 如今當我們看到大模型展現出比肩甚至超越人類的推理能力時 , 這項來自DeepMind的研究卻提醒我們 , 大模型或許如果硅基版的會算數的馬 , 其推理能力部分來自對與人類互動的提示詞的細節根據模板進行匹配 。
其是否真的具有如人類的推理能力 , 還存在疑問 , 畢竟大多數人不會如大模型一樣 , 被無關的 , 誤導的甚至錯誤的思考過程影響而不可自拔 。
當不懷好意者在思考過程中加入無關內容后 , 即使大模型能夠識別出問題 , 也會被帶偏 , 而越大的模型有更多的模版庫 , 因此更有可能在思考過程跑偏(走神)后成為犯錯卻死不回頭的杠精 。
這些發現突顯了當前推理模型在「元認知」和從誤導性推理路徑中恢復方面存在很大的改進空間 , 這是開發更安全和更可靠的大規模推理模型時的一個關鍵考慮因素 。
參考資料:
https://arxiv.org/abs/2506.10979
推薦閱讀












- 華為AI推理設備集采,32.8億大單敲定!
- 中國電信智算網絡突破:跨數據中心無損推理,為企業算力部署開新篇
- 華為又開源了個大的:超大規模MoE推理秘籍
- 只用2700萬參數,這個推理模型超越了DeepSeek和Claude
- 騰訊開源推理模型!13B參數比肩OpenAI o1,1張GPU就能跑
- 推理越多,幻覺越重?多模態推理模型的“幻覺悖論”
- 同一天開源新模型,一推理一編程,MiniMax和月之暗面開卷了
- 3D高斯潑濺,可輸入視圖量高達500,推理速度提升3倍,內存少80%
- 沉迷貪吃蛇,7B小模型竟變身「數學天才」,幾何推理碾壓GPT-4o
- LeCun世界模型出2代了,62小時搞定機器人訓練,開啟物理推理新時代