
文章圖片
文章圖片
文章圖片
文章圖片

文章圖片
文章圖片
【深夜開源首個萬億模型K2,壓力給到OpenAI,Kimi時刻要來了?】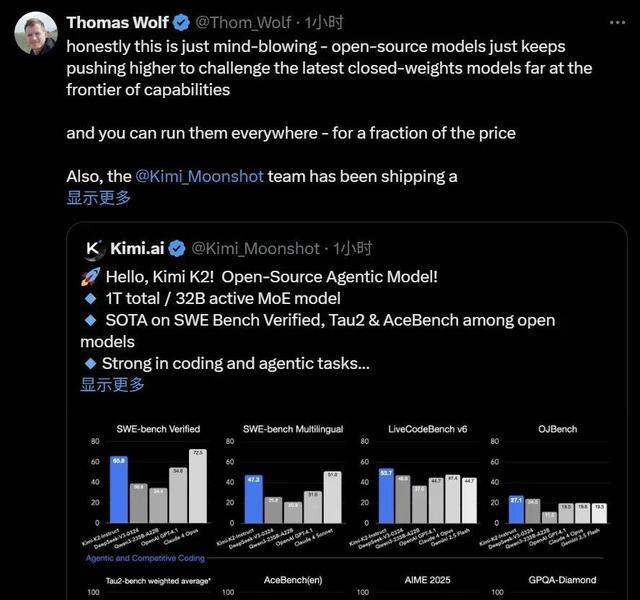
文章圖片
文章圖片
機器之心報道
編輯:澤南、杜偉
沒想到 , Kimi 的首個基礎大模型開源這么快就來了 。
昨晚 , 月之暗面正式發布了 Kimi K2 大模型并開源 , 新模型同步上線并更新了 API , 價格是 16 元人民幣 / 百萬 token 輸出 。
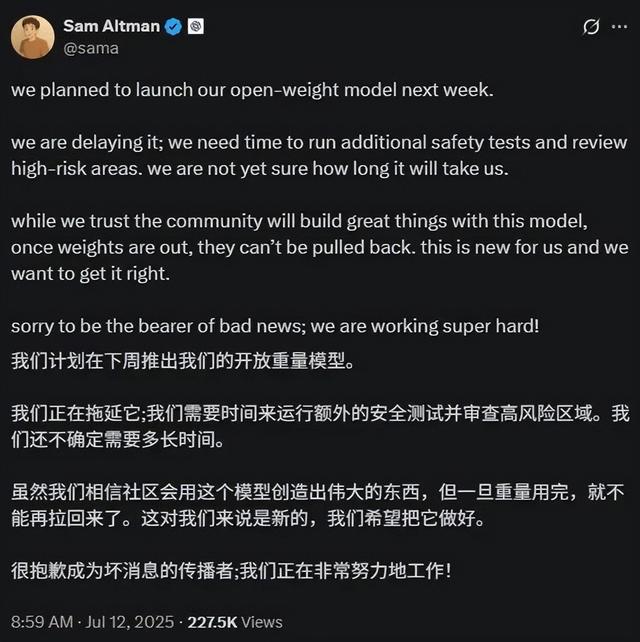
這次發布趕在了最近全球大模型集中發布的風口浪尖 , 前有 xAI 的 Grok 4 , 下周可能還有谷歌新 Gemini 和 OpenAI 開源模型 , 看起來大模型來到了一個新的技術節點 。 或許是感受到了 Kimi K2 的壓力 , 就在剛剛 , 奧特曼發推預告了自家的開源模型 。 不過 , 網友似乎并不看好 。
本次開源的共有兩款模型 , 分別是基礎模型 Kimi-K2-Base 與微調后模型 Kimi-K2-Instruct , 均可商用 。
- 博客鏈接:https://moonshotai.github.io/Kimi-K2/
- GitHub 鏈接:https://github.com/MoonshotAI/Kimi-K2
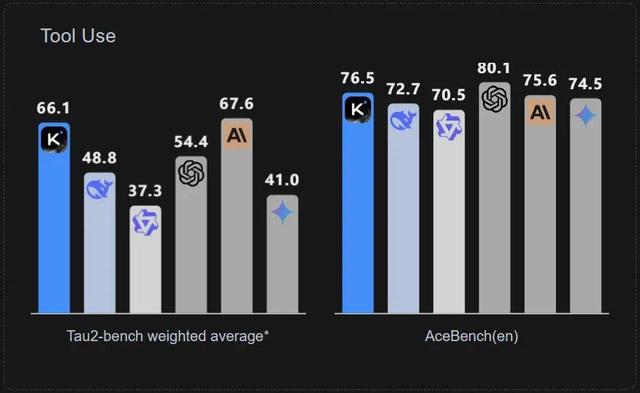
從 LiveCode Bench、AIME2025 和 GPQA-Diamond 等多個基準測試成績來看 , 此次 Kimi K2 超過了 DeepSeek-V3-0324、Qwen3-235B-A22B 等開源模型 , 成為開源模型新 SOTA;同時在多項性能指標上也能趕超 GPT-4.1、Claude 4 Opus 等閉源模型 , 顯示出其領先的知識、數學推理與代碼能力 。
Kimi 展示了 K2 的一些實際應用案例 , 看起來它能自動理解如何使用工具來完成任務 。 它可以自動地理解所在的任務環境 , 決定如何行動 , 在下達任務指令時 , 你也不需要像以往那樣為智能體列出詳細的工作流程 。
在完成復雜任務工作時 , Kimi K2 會自動調用多種工具實現能力邊界的擴展 。 昨天上線后 , 網友們第一時間嘗試 , 發現可以實現不錯的效果:
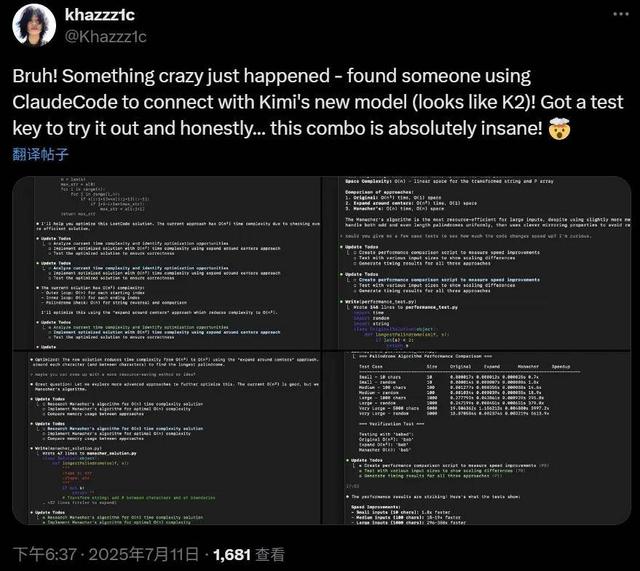
值得關注的是 , 就在昨天 Grok 4 發布后 , 人們第一時間測試發現其代碼能力飄忽不定 , 但看起來 Kimi K2 的代碼能力經住了初步檢驗 。
網友使用 Claude Code 鏈接 Kimi K2 , 發現效果不錯 。
從網友第一時間的測試來看 , K2 代碼能力是個亮點 , 因為價格很低 , 大家發現它可能是 Claude 4 Sonnet 的有力開源平替 。 有網友直接說 K2 是代碼模型的 DeepSeek 時刻:
HuggingFace 聯合創始人 Thomas Wolf 也表示 , K2 令人難以置信 , 開源模型正在挑戰最新的閉源權重模型 。
在技術博客中 , Kimi 也介紹了 K2 訓練中的一些關鍵技術 。
預訓練數據 15.5T tokens
沒用傳統 Adam 優化器
首先 , 為了解決萬億參數模型訓練中穩定性不足的問題 , Kimi K2 引入了 MuonClip 優化器 。
Muon 優化器作為一種優化算法 , 可以幫助神經網絡在訓練過程中更好地收斂 , 提升模型準確性和性能 。 今年 2 月 , 月之暗面推出了基于 Muon 優化器的高效大模型 Moonlight , 證明這類優化器在 LLM 訓練中顯著優于當前廣泛使用的 AdamW 優化器 。
此次 , Kimi K2 在開發過程中進一步擴展 Moonlight 架構 。 其中基于 Scaling Laws 分析 , 月之暗面通過減少 Attention Heads 數量來提升長上下文效率 , 同時增加 MoE 稀疏性來提高 token 利用效率 。 然而在擴展中遇到了一個持續存在的挑戰:Attention logits 爆炸會導致訓練不穩定 , 而 logit 軟上限控制和 query-key 歸一化等現有方案對此的效果有限 。
針對這一挑戰 , 月之暗面在全新的 MuonClip 中融入了自己提出的 qk-clip 技術 , 在 Muon 更新后直接重新縮放 query 和 key 投影組成的權重矩陣 , 從源頭上控制 Attention logits 的規模 , 實現穩定的訓練過程 。
改進后的 MuonClip 優化器不僅可以擴展到 Kimi K2 這樣萬億參數級別的 LLM 訓練 , 還將大幅度提升 token 效率 。 一個更具 token 效率的優化器更能提升模型智能水平 , 這正是當前業界(如 Ilya Sutskever)看重的延續 Scaling Laws 的另一關鍵系數 。
Kimi K2 的實驗結果證實了這一點:MuonClip 能夠有效防止 logit 爆炸 , 同時保持下游任務的性能 。 官方稱 , Kimi K2 順利完成 15.5T tokens 的預訓練 , 過程中沒有出現任何訓練尖峰 , 形成了 LLM 訓練的一套新方法 。
token 損失曲線
因此 , 相較于原始 Muon , MuonClip 取長補短 , 進一步放大其在預訓練過程中的優勢 。 自大模型技術爆發以來 , 優化器的探索方向不再是熱門 , 人們習慣于使用 Adam , 而如果想要進行替換 , 則需要大量的驗證成本 。 Kimi 的全新探索 , 不知是否會成為新的潮流 。
其次 , 為了解決真實工具交互數據稀缺的難題 , Kimi K2 采用大規模 Agentic 數據合成策略 , 并讓模型學習復雜工具調用(Tool Use)能力 。
本周四 , 我們看到 xAI 的工程師們在發布 Grok 4 時也強調了新一代大模型的多智能體和工具調用能力 , 可見該方向正在成為各家公司探索的焦點 。
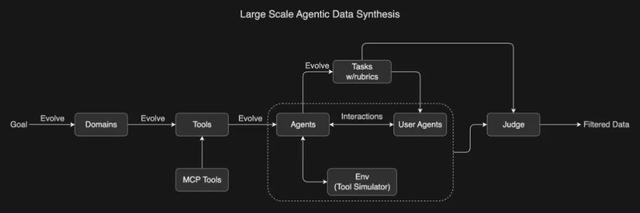
Kimi 開發了一個受 ACEBench 啟發的綜合 pipeline , 能夠大規模模擬真實世界的工具使用場景 。 具體來講 , 該流程系統性地演化出涵蓋數百個領域的數千種工具 , 包括真實的 MCP 工具和合成工具 , 然后生成數百個具有多樣化工具集的智能體 。
大規模 Agentic 數據合成概覽
接下來 , 這些智能體與模擬環境、用戶智能體進行交互 , 創造出逼真的多輪工具使用情景 。 最后 , 由一個大語言模型(LLM)充當評判員 , 根據任務評分標準(rubrics)評估模擬結果 , 篩選出高質量的訓練數據 。
一整套流程走下來 , 這種可擴展的 pipeline 生成了多樣化、高質量的數據 , 有效填補特定領域或稀缺場景真實數據的空白 。 并且 , LLM 對數據的評估與篩選有效減少低質量數據對訓練結果的負面影響 。 這些數據層面的增強為大規模拒絕采樣和強化學習鋪平了道路 。
最后 , Kimi K2 引入了通用強化學習(General RL) , 通過結合 RL 與自我評價(self-judging)機制 , 在可驗證任務與不可驗證任務之間架起了一座橋梁 。
在數學、編程等可驗證任務上 , 我們可以根據正確答案、任務完成情況等可驗證的獎勵信號持續更新并改進對模型能力的評估 。 但是 , 傳統強化學習由于依賴明確的反饋信號 , 因而在生成文本、撰寫報告等不可驗證任務中很難給出客觀、即時的獎勵 。
針對這一局限 , 通用強化學習通過采用自我評價機制 , 讓模型充當自己的評判員(critic) , 提供可擴展、基于 rubrics 的反饋 。 這種反饋替代了外部獎勵 , 解決了不可驗證任務中獎勵稀缺的問題 。與此同時 , 基于可驗證獎勵的策略回滾(on-policy rollouts) , 持續對評判員進行更新 , 使其不斷提升對最新策略的評估準確性 。
這種利用可驗證獎勵來改進不可驗證獎勵估計的方式 , 使得 Kimi K2 既能高效地處理傳統可驗證任務 , 又能在主觀的不可驗證任務中自我評估 , 從而推動強化學習技術向更廣泛的應用場景擴展 。
從長遠來看 , Kimi K2 的這些新實踐讓大模型具備了在各種復雜環境中持續優化的能力 , 可能是未來模型智能水平繼續進化的關鍵 。
接下來 , 基模卷什么
Kimi 的發布 , 讓我們想起前天 xAI 的 Grok-4 發布會 , 馬斯克他們宣傳自己大模型推理能力時 , 列出了基于通用 AI 難度最高的測試「人類最后的考試」Humanities Last Exam(HLE)上幾個重要突破節點 。
其中 OpenAI 的深度研究、Gemin 2.5 Pro 和 Kimi-Reseracher 都被列為了重要的突破:
Kimi-Researcher 在上個月剛剛發布 , 其采用端到端自主強化學習 , 用結果驅動的算法進行訓練 , 擺脫了傳統的監督微調和基于規則制或工作流的方式 。 結果就是 , 探索規劃的步驟越多 , 模型性能就越強 。
而在 Kimi K2 上 , 月之暗面采用了與 Grok 4 類似的大規模工具調用方式 。
另外 , 我們可以看到 , 由于國內算力資源的緊缺局面 , 新一波大模型技術競爭已經逐漸放棄單純的堆參數、算力規模擴大的方式 , 在推動模型 SOTA 的過程中 , 通過算法上的創新來卷成本和效率成為趨勢 。
推薦閱讀













- 北大、北郵、華為開源純卷積DiC:3x3卷積實現SOTA性能比DiT快5倍
- 首個旅游行業超級智能體馬蜂窩“AI路書”全面開放,玩轉出境自由行
- 新增14種語言 高德地圖推出國內首個面向海外用戶的多語言地圖
- 北京首個6G專項政策,2030年突破核心技術50項
- 四款免費開源音樂播放軟件推薦:暢享自由音樂之旅
- 500萬視頻數據集+全新評測框架!北大開源OpenS2V-Nexus
- 阿里開源智能體WebSailor,又刷新了多項紀錄
- 野生DeepSeek火了,速度碾壓官方版,權重開源
- 通義靈碼軟件工程大模型獲國際頂會杰出論文獎,復雜問題解決率刷新開源紀錄
- 瑞金醫院與華為開源RuiPath病理模型 為醫療AI發展按下“加速鍵”