
文章圖片
文章圖片

文章圖片
文章圖片
PresentAgent可以把論文、報告等長文檔一鍵變成帶真人語音和同步幻燈片的演示視頻 , 流程像人寫提綱、做PPT、錄音并合成 。 實驗使用30份文檔與人工視頻對比測試 , PresentAgent在內容準確、視覺清晰和觀眾理解上都接近人類水準 , 可幫老師、商務人士省去大量做PPT和錄音的時間 。
演示是一種廣泛使用且行之有效的信息傳達方式 。 通過結合視覺元素、結構化的講解和口頭解釋 , 它能夠使信息逐步展開 , 從而讓不同受眾更容易理解 。
盡管效果顯著 , 但將長篇文檔(如商業報告、技術手冊、政策簡報或學術論文)制作成高質量演示視頻通常需要耗費大量人工精力 。
這個過程涉及內容篩選、幻燈片設計、講稿撰寫、語音錄制 , 以及將所有內容整合成一個連貫的多模態輸出 。
盡管近年來AI在文檔轉幻燈片和文本轉視頻等領域取得進展 , 但仍存在一個關鍵問題:這些方法要么只能生成靜態的視覺摘要 , 要么僅能輸出無結構的通用視頻片段 , 難以勝任需要結構化講述的演示任務 。
為彌補這一空白 , 澳大利亞人工智能研究所、英國利物浦大學的研究人員提出了一個新任務:文檔到演示視頻生成(Document-to-Presentation Video Generation) , 旨在自動將結構化或非結構化文檔轉化為配有語音講解和同步幻燈片的視頻演示 。
論文鏈接:https://arxiv.org/pdf/2507.04036 , 代碼鏈接:https://github.com/AIGeeksGroup/PresentAgent
該任務的挑戰遠超傳統的摘要或文本轉語音系統 , 因為它需要選擇性內容抽象、基于布局的視覺規劃 , 以及視覺與語音的精確多模態對齊 。
圖1:PresentAgent 概覽 。
圖2:評估基準中的文檔多樣性
【一鍵實現PPT演講自由,「解說音頻+視頻」同步生成,效果逼近真人】與以往只關注靜態幻燈片/圖像生成或單一語音摘要的方法不同 , 研究人員的目標是構建一個完整集成的視頻體驗 , 模擬現實中人類演講者的信息傳遞方式 。
圖3:方法框架概覽
上圖左側給定多樣的輸入文檔(如論文、網站、博客、幻燈片或 PDF) , PresentAgent 能生成帶講解的演示視頻 , 輸出為同步的幻燈片和音頻 。
右側設計了PresentEval , 一個雙路徑的評估框架:
(1)客觀測驗評估(上) , 通過 Qwen-VL 進行事實理解檢測;
(2)主觀打分評估(下) , 借助視覺-語言模型從內容質量、視覺設計與語音理解等維度進行評分 。
為應對上述挑戰 , 研究人員提出了一個模塊化生成框架——PresentAgent , 如圖1所示 。
其流程包括:
將輸入文檔語義分塊(通過大綱規劃);
為每個語義塊生成具有布局指導的幻燈片視覺內容;
將關鍵信息重寫為口語化解說文本;
語音合成后 , 與幻燈片進行時間同步 , 最終生成一個結構良好、講解清晰的視頻演示 。
值得一提的是 , 整個流程具有可控性和領域適應性 , 適用于多種文檔類型和演示風格 。
為有效評估此類復雜多模態系統 , 研究人員整理了一個涵蓋教育、金融、政策與科研等多個領域的30組人工制作的文檔-演示視頻對的測試集 。
同時 , 研究人員設計了一個雙路徑評估策略:
一方面使用固定選擇題測試內容理解; 另一方面通過視覺語言模型打分 , 評估視頻的內容質量、視覺呈現與觀眾理解程度 。實驗結果表明 , 該方法生成的視頻流暢、結構合理、信息充分 , 在內容傳達和觀眾理解方面接近人類表現 。
這表明將語言模型、視覺布局生成與多模態合成結合 , 能夠實現可解釋、可擴展的自動演示生成系統 。
主要貢獻如下:
提出新任務:首次提出“文檔到演示視頻生成”這一新任務 , 旨在從各類長文本自動生成結構化的幻燈片視頻 , 并配有語音解說 。設計PresentAgent系統:提出一個模塊化生成框架 , 涵蓋文檔解析、布局感知幻燈片構建、講稿生成及音視同步 , 實現可控、可解釋的視頻生成過程 。提出PresentEval評估框架:構建一個由視覺語言模型驅動的多維度評估機制 , 從內容、視覺與理解等維度對視頻進行提示式評分 。構建高質量評測數據集:制作了一個包含30對真實文檔與對應演示視頻的數據集 。 實驗和消融研究顯示 , PresentAgent不僅接近人類表現 , 且顯著優于現有方案 。
演示視頻評估基準該基準不僅評估視頻的流暢性與信息準確性 , 還支持對觀眾理解程度的評估 。
借鑒Paper2Poster的方法 , 研究人員設計了一個測驗式評估 , 即通過視覺語言模型僅根據生成視頻(幻燈片+講解)回答內容問題 , 以模擬觀眾的理解水平 。
研究人員還引入人工制作的視頻作為參考標準 , 既用于評分校準 , 也作為性能上限對比 。
如圖2所示 , 基準涵蓋四種代表性文檔類型(學術論文、網頁、技術博客和幻燈片) , 均配有真實人工講解視頻 , 覆蓋教育、科研、商業報告等多種真實領域 。
示例:客觀測驗評估(Objective Quiz Evaluation)客觀測驗評估中的提示樣例 , 每組選擇題均基于源文檔真實內容手動設計 , 重點考查主題識別、結構理解與核心觀點提取能力 , 用于評估生成視頻是否有效傳達原始信息 。
示例:主觀評分維度(Subjective Scoring Prompts)主觀評分提示示例 , 其中每項提示關注一個特定維度 , 旨在指導視覺語言模型以“人類視角”對視頻進行評分 。 縮寫說明:Narr. Coh. = 講解連貫性;Comp. Diff. = 理解難度 。
研究人員采用一個「統一的模型驅動評估框架」來對生成的演示視頻進行評分 , 所有評估均使用視覺語言模型 , 結合針對不同維度設計的提示進行引導 。
該評估框架由兩部分組成:
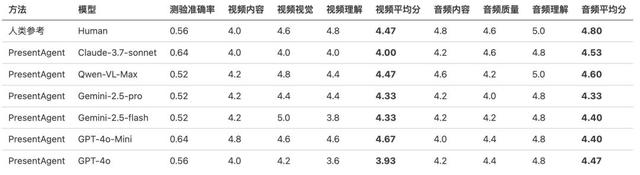
客觀測驗評估:通過選擇題測量視頻傳遞信息的準確性; 主觀評分評估:從內容質量、視覺/音頻設計與理解清晰度等維度 , 對視頻進 1–5分等級評分 。這兩類指標共同構成了對生成視頻的全面質量評估體系 。Doc2Present數據集介紹 為了支持文檔到演示視頻生成的評估 , 研究人員構建了一個多領域、多文體的真實對照數據集——Doc2Present Benchmark , 其中每對數據都包含一個文檔與一個配套的演示視頻 。不同于以往只關注摘要或幻燈片的基準 , 數據包括商業報告、產品手冊、政策簡報、教程類文檔等 , 每篇文檔均配有人工制作的視頻講解 。數據來源 研究人員從公開平臺、教育資源庫和專業演示存檔中收集了30個高質量演示視頻樣本 , 每個視頻都具有清晰結構 , 結合了幻燈片視覺呈現和同步語音講解 。研究人員手動對齊每個視頻與其源文檔 , 并確保視頻結構與文檔內容一致、幻燈片視覺信息緊湊且結構化、講解與幻燈片在時間上良好同步 。數據統計信息 文檔長度:約3000–8000字 視頻長度:1–2分鐘 幻燈片數量:5–10頁 這一設置強調了任務的核心挑戰:如何將密集、領域專屬的文檔內容轉化為簡明易懂的多模態演示內容 。PresentEval 為了評估生成的演示視頻的質量 , 研究人員采用了兩種互補的評估策略:客觀選擇題評估(Objective Quiz Evaluation)和主觀評分(Subjective Scoring) , 如圖3所示 。對于每個視頻 , 將幻燈片圖像和完整的講解文本作為統一輸入提供給視覺-語言模型 , 模擬真實觀眾的觀看體驗 。在客觀評估中 , 模型需回答一組固定的事實性問題 , 以判斷視頻是否準確傳達了原始文檔中的關鍵信息 。在主觀評分中 , 模型從三個維度對視頻進行打分:講解的連貫性、視覺設計的清晰度與美觀性 , 以及整體的易理解程度 。 所有評估都不依賴真實參考 , 而完全依靠模型對呈現內容的理解 。客觀選擇題評估 為了評估生成的視頻是否有效傳達了原始文檔的核心內容 , 采用固定問題的理解評估協議 。研究人員為每個文檔手動設計五道多項選擇題 , 側重于主題識別、結構理解和論點提取等方面 。如表1所示 , 評估時 , 視覺-語言模型接收包含幻燈片和音頻轉錄的完整視頻 , 并回答五個問題 。每題有四個選項 , 僅有一個正確答案 , 正確答案基于人工制作的視頻標注 , 最終理解得分(范圍0-5)反映模型答對了幾題 , 衡量視頻傳達原始信息的能力 。主觀評分 為評估生成視頻的質量 , 研究人員采用基于提示的視覺-語言模型評估方式 , 不同于依賴人工參考或固定指標的方法 , 要求模型從觀眾視角出發 , 用自身推理與偏好打分 。評分關注三個方面:講解連貫性、幻燈片視覺效果以及整體理解難度 。模型觀看視頻與音頻內容后 , 分別為每個維度打分(1–5分)并簡要解釋 。 具體評分提示見表2 , 針對不同模態和任務設計了不同的提示語 , 以實現精準評估 。PresentAgent 圖4:PresentAgent框架概覽 該系統以多種類型的文檔(例如論文、網頁、PDF等)為輸入 , 遵循模塊化的生成流程: 首先進行提綱生成; 接著檢索出最適合的幻燈片模板; 然后借助視覺-語言模型生成幻燈片和解說文稿; 將解說文稿通過TTS轉換為音頻 , 并合成為完整的演示視頻; 為了評估視頻質量 , 設計了多個維度的提示語; 最后將提示輸入基于視覺語言模型(VLM)的評分模塊 , 輸出各個維度的指標結果 。為了將長文本文檔轉化為帶口語化講解的演示視頻 , 設計了一個多階段的生成框架 , 模擬人類準備幻燈片與演講內容的流程 。該方法分為四步:語義分段、結構化幻燈片生成、口語化講解生成、可視與音頻組合為同步視頻 。該模塊化設計支持可控性、可解釋性和多模態對齊 , 兼顧高質量生成與細粒度評估 。 下文將分別介紹各模塊 。問題定義 傳統方法通常直接從文檔片段C生成幻燈片元素S , 如下所示: S={e1e2...en=f(C) 該方法則視整個文檔D為整體輸入 , 通過三步生成演示視頻: 基于大綱規劃生成語義段落序列{C1...CK; 對每段生成幻燈片Sk與口語講稿Tk(再轉為音頻); 合成帶時間對齊的視頻V: V=Compose({(S1T1)...(SKTK))=g(D) 該流程不依賴固定模板 , 而是從高層結構出發 , 自底向上生成幻燈片和講解內容 , 支持多模態對齊與可控生成 。幻燈片規劃與生成 幻燈片模塊借鑒了PPTAgent的結構化編輯范式 , 但目標不同——不是輸出.pptx文件 , 而是為視頻合成生成視覺一致的靜態幻燈片幀 。 流程如下: 用輕量級語言模型解析文檔 , 劃分語義段; 為每段匹配合適的幻燈片類型(如:項目符號、圖文結合、標題介紹等); 使用規則和語義信息將內容映射至HTML模板; 調用操作指令(如:replace_text insert_image)生成最終幻燈片; 使用python-pptx或HTML渲染器渲染為靜態圖像 。講解生成與語音合成 為使幻燈片更具吸引力 , 研究人員為每頁幻燈片生成講解 , 并將其合成為語音: 針對每個語義段落 , 提示語言模型生成自然、簡潔的口語化講稿; 控制長度在30–150秒之間; 使用文本轉語音(TTS)系統生成對應音頻; 將音頻與幻燈片匹配 , 形成時間對齊的素材 。視頻合成 最后一步 , 將靜態幻燈片圖像與配音音頻合成為完整的視頻: 每頁幻燈片持續顯示 , 與其音頻同步; 可添加淡入淡出過渡; 使用ffmpeg等視頻處理工具合成視頻軌; 輸出標準格式(如.mp4) , 便于分享或編輯 。實驗結果 研究人員設計實驗以驗證PresentAgent在生成高質量講解視頻方面的有效性 。 重點不在與已有基線方法比較 , 而是評估系統在接近人類表現方面的能力 , 特別是在PresentEval評估任務中的理解能力 。評估設置 研究人員構建了一個包含30個長文檔的測試集 , 每個文檔配有人類手工制作的演示視頻作為參考 , 涵蓋教育、產品說明、科研綜述與政策簡報等主題 。所有生成與人工視頻均使用PresentEval框架進行評估 。 由于當前尚無模型可完整評估超2分鐘的多模態視頻 , 采用分段評估策略: 客觀評估階段:使用Qwen-VL-2.5-3B回答固定的多項選擇題 , 評估內容理解; 主觀評分階段:提取視頻與音頻片段 , 使用Qwen-Omni-7B針對內容質量、視覺/聽覺質量和理解難度分別打分 。評分依賴維度提示語 , 覆蓋內容完整性、視覺設計與語音可理解性 。實現細節 PresentAgent采用高度模塊化的多模態生成架構 , 主要特征如下: 語言理解模塊支持GPT-4o、GPT-4o-mini、Qwen-VL-Max、Gemini-2.5 Flash/Pro、Claude-3.7-Sonnet , 并通過動態路由策略選擇最優模型; VLM評估器使用輕量級Qwen-VL-2.5-3B-Instruct , 評估布局合理性、圖表可讀性和跨模態一致性; TTS使用MegaTTS3 , 支持24kHz高保真合成與節奏/情感控制; 完整流程包括: 結構解析與重排:構建主題–子主題樹; 逐頁生成:通過LLM生成含標題、項目符號、圖像占位符和替代文本的幻燈片; 配音合成與合成輸出:支持中英文發音 , 最終通過ffmpeg腳本合成1080p視頻 , 含淡入淡出與字幕 。主實驗結果 表3:五份測試文檔的詳細評估結果 表3展示了評估結果 , 涵蓋了事實理解能力(測驗準確率)以及基于偏好的視頻和音頻輸出質量評分 。在測驗準確率方面 , 大多數PresentAgent的變體與人工基準結果(0.56)相當甚至更優 。 其中Claude-3.7-sonnet取得了最高準確率0.64 , 表明生成內容與源文檔之間具有較強的一致性 。 其他模型如Qwen-VL-Max和Gemini-2.5-flash得分略低(0.52) , 表明在事實對齊方面仍有提升空間 。在主觀質量方面 , 由人類制作的演示仍在視頻和音頻整體評分上保持領先 。 然而 , 一些PresentAgent變體表現出有競爭力的性能 。 例如 , GPT-4o-Mini在視頻內容和視覺吸引力方面獲得了最高分(均接近或達到4.8) , 而Claude-3.7-sonnet則在音頻質量方面表現最為平衡(均分為4.53) 。有趣的是 , Gemini-2.5-flash在視覺質量上取得了最高得分(5.0) , 但在理解性方面較低 , 這反映了美觀性與清晰度之間的權衡 。 這些結果突顯了模塊化生成流程的有效性 , 以及統一評估框架PresentEval在捕捉演示質量多個維度方面的實用價值 。案例分析 圖5:自動生成視頻示例 圖5展示了一個完整的PresentAgent自動生成演示視頻示例 , 其中一篇技術博客被轉化為帶解說的演示 。系統識別出結構性片段(如引言、技術解釋等) , 并為其生成了包含口語風格字幕和同步語音的幻燈片 , 涵蓋了“并行化工作流”“代理系統架構”等技術主題 , 展示了系統在保持技術準確性的同時 , 以清晰、對話式方式傳達信息的能力 。討論 研究人員合成了整合視覺幻燈片、文本解說和語音音頻的演示風格視頻 , 模擬了現實中的多模態交流場景 。 目前的評估方法主要關注各模態的獨立質量 , 例如視覺清晰度、文本相關性以及音頻可理解性 , 這些維度目前被分別對待 。然而 , 在現實應用中 , 溝通的有效性往往取決于各模態之間的語義與時間上的協同一致性 。因此 , 未來的研究應超越孤立評估 , 邁向融合感知(fusion-aware)的理解與評估 , 意味著不僅要建模圖像、音頻和文本模態之間的交互與對齊 , 還需賦予系統在多模態語義聯合下的推理能力 。現有模型如ImageBind提供了多模態的統一嵌入空間 , 但在高層推理與語義理解能力方面仍有所不足 。一個有前景的方向是:將表示對齊(representation alignment)與多模態推理能力(multimodal reasoning)結合起來 , 構建融合對齊的模態編碼器與強大的語言模型 。這將使系統具備對復雜多模態輸入的聯合感知、理解與響應能力——例如 , 基于語音解說與視覺線索解釋某個視覺概念 , 或識別模態間的不一致性 。開發此類具有推理能力的融合感知模型 , 將是推動多模態理解向真實世界應用場景邁進的關鍵 。局限性與未來工作 該工作目前面臨兩個主要限制: 由于使用商業LLM/VLM API(如 GPT-4o 和 Gemini-2.5-Pro)存在高計算成本 , 評估僅限于5篇學術論文 , 可能未能充分代表該基準數據集中展示的文檔多樣性; PresentAgent當前生成的是靜態幻燈片 , 尚未支持動態動畫或轉場效果 , 這主要受到視頻合成架構限制以及生成速度與視覺質量之間的權衡約束(正如 ChronoMagic-Bench中關于時間一致性的研究所指出的) 。未來的研究工作將集中在三個方向: 第一 , 通過引入更多種類的開源大模型作為基礎 , 包括多種架構設計、能力范圍和微調策略 , 拓展至更多類別的文檔 , 以支持更廣泛的生成與評估任務 , 覆蓋教育、政策、商業等實際場景 , 力求實現系統能力的全面評估; 第二 , 通過優化視頻合成架構 , 引入動態動畫能力 , 在保證生成效率的同時提升視覺表現 , 適配復雜的場景轉?。 ?第三 , 探索輕量級蒸餾方法與具備物理感知能力的渲染引擎 , 從而提升生成效率、寫實程度和對不同硬件環境的適應性 。結論 研究人員提出了PresentAgent , 一個用于將長篇文本文檔轉換為帶有語音講解的演示視頻的模塊化系統 。 通過系統性地處理幻燈片規劃、語音解說合成以及視音同步渲染等流程 , PresentAgent 支持對多種類型文檔的可控生成與復用的多模態輸出 。為支持嚴格評估 , 研究人員構建了文檔–視頻對齊的基準數據集 , 并提出了雙重評估策略:事實問答與基于偏好的視覺語言評分 。 實驗結果(包括消融實驗與模型對比)表明 , PresentAgent 能夠生成結構清晰、表達生動且信息密集的演示內容 , 整體效果接近人類水準 。結果展示了融合語言模型與視覺模型在可解釋且面向觀眾的內容生成方面的潛力 , 為未來在教育、商業、無障礙傳播等場景中的自動化、可控多模態生成研究奠定了基礎 。參考資料 https://arxiv.org/pdf/2507.04036 本文來自微信公眾號“新智元” , 作者:LRST, 36氪經授權發布 。
推薦閱讀













- 模仿學習新范式,Chain-of-Action:軌跡自回歸實現動作推理
- 亞馬遜云科技推出全新agentic IDE「Kiro」,三步實現從構想到交付
- 實現NAS用戶的“容量自由”,希捷酷狼Pro 30TB機械硬盤深度評測
- 熱映動畫電影一鍵直達,出行動嘴打車……鴻蒙5開啟遛娃簡單模式
- ICCV 2025滿分論文:一個模型實現空間理解與主動探索大統一
- 全球首款自毀SSD!一鍵毀滅全部數據 斷電也不怕
- “一句話秒出PPT“的榮耀YOYO,AI生產力有多強?
- 北大、北郵、華為開源純卷積DiC:3x3卷積實現SOTA性能比DiT快5倍
- 馬斯克:Grok即將登陸特斯拉汽車 最遲下周實現
- 諾基亞助力印尼電信巨頭實現綠色智能轉型