
文章圖片

文章圖片
文章圖片
離開OpenAI , 只是為了Meta天價薪資?Jason Wei離職博客 , 泄露天機:未來AI更令人向往!
硅谷人才爭奪戰 , 火熱升級!
過去 , 是OpenAI從谷歌等公司吸引人才;現在 , Meta直接砸錢搶人 。
頂尖AI人才的薪酬包可謂天價 , 1億美元還是扎克伯格給的起步價!
思維鏈之父、華人AI科學家Jason Wei , 就是從谷歌跳槽到OpenAI , 剛剛又跳槽到Meta 。
在AI領域 , Jason Wei非常高產 。
根據谷歌學術統計 , 他有13篇被引次數超過1000的論文 , 合作者包括Jeff Dean、Quoc V. Le等知名AI研究員 , 參與了OpenAI的GPT-4、GPT-4o、o1、深度研究等項目 。
離職消息被媒體爆出之前 , 他發表了兩篇博客 , 或許能讓我們看出他為何選擇離開
意外的是 , 這些靈感都來自強化學習!
RL之人生啟示 , 天生我材必有用過去一年 , 他開始瘋狂學習強化學習 , 幾乎每時每刻都在思考強化學習 。
RL里有個核心概念:永遠盡量「on-policy」(同策略):與其模仿他人的成功路徑 , 不如采取行動 , 自己從環境中獲取反饋 , 并不斷學習 。
當然 , 在一開始 , 模仿學習(imitation learning)非常必要 , 就像我們剛開始訓練模型時 , 必須靠人類示范來獲得基本的表現 。 但一旦模型能產生合理的行為 , 大家更傾向于放棄模仿 , 因為要最大化模型獨特的優勢 , 就只能依靠它自己的經驗進行學習 。
一個很典型的例子是:相比用人類寫的思維鏈做監督微調 , 用RL訓練語言模型解數學題效果更好 。
人生也一樣 。
我們一開始靠「模仿」來成長 , 學校就是這個階段 , 合情合理 。
研究別人的成功之道 , 然后照抄 。 有時候確實有效 , 但時間一長就能意識到 , 模仿永遠無法超越原版 , 因為每個人都有自己獨特的優勢 。
強化學習告訴我們 , 如果想超越前人 , 必須走出自己的路 , 接受外部風險 , 也擁抱它可能給予的獎勵 。
他舉兩個他自己更享受、卻相對小眾的習慣:
讀大量原始數據 。做消融實驗 , 把系統拆開看每個部件的獨立作用 。有一次收集數據集時 , 他花了幾天把每條數據讀一遍 , 然后給每個標注員寫個性化反?。 皇葜柿克婧簞?, 他也對任務有了獨到見解 。
【思維鏈之父跳槽Meta,不只因為1億美元,離開OpenAI前泄天機】今年年初 , 他還專門花了一個月 , 把過去研究中「瞎搞」的決策逐條消融 。 雖然費了不少時間 , 但因此弄清了哪種RL真正好用 , 也收獲了很多別人教不會的獨特經驗 。
更重要的是 , 順著自己的興趣去做研究不僅更快樂 , 我也感覺自己正在打造一個更有特色、更屬于自己的研究方向 。
所以總結一下:模仿確實重要 , 而且是起步的必經之路 。 但一旦你站穩腳跟 , 想要超越別人 , 就得像強化學習那樣on-policy , 走自己的節奏 , 發揮你獨有的優勢與短板\uD83D\uDE04
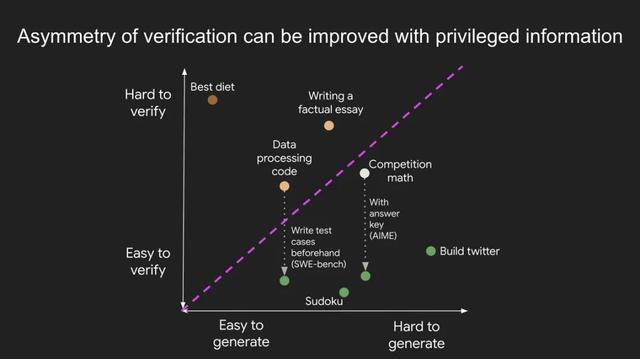
AI的未來驗證非對稱性 , 意指某些任務的驗證遠比求解更為簡單 。
隨著強化學習(RL)的突破 , 這一概念正成為AI領域最重要的思想之一 。
細察之下 , 驗證非對稱性無處不在:
數獨和填字游戲:解決數獨或填字游戲非常耗時 , 要嘗試各種可能性去滿足約束條件 。 但驗證一個答案是否正確卻非常簡單 , 只需檢查是否符合規則即可 。開發網站:比如開發一個像Instagram這樣的網站 , 需要工程師團隊數年之功 。 但驗證網站是否正常運行 , 普通人只需幾分鐘就能完成 , 比如瀏覽頁面、檢查功能是否可用 。BrowseComp問題:要解決這類問題 , 通常需要瀏覽數百個網站 , 但驗證給定答案卻要快得多 , 因為可以直接搜索答案是否符合約束條件 。有些任務的驗證耗時與求解相當 。 例如:
驗證兩個900位數字相加的結果 , 和自己計算的時間幾乎一樣 。驗證某些數據處理程序的代碼是否正確 , 可能和自己編寫代碼的耗時相當 。有些任務驗證比解決還費時 。 例如:
核查一篇文章中的所有事實 , 可能比寫文章本身更耗時(引用Brandolini定律:「辟謠所需的精力比制造謠言大一個數量級」) 。提出一個新的飲食療法只需一句話:「只吃野牛肉和西蘭花」 , 但要驗證它對普通人群是否健康 , 卻得做多年大規模實驗 。通過前置研究 , 可以讓驗證變得更簡單 。 例如:
數學競賽問題:如果有解答要點 , 驗證答案是否正確非常簡單 。編程問題:閱讀代碼去驗證正確性 , 這很麻煩 。 如果你有覆蓋充分的測試用例 , 就可以快速檢查任何給定的解決方案;實際上 , Leetcode就是這樣做的 。 在某些任務中 , 可以改善驗證但不足以使其變得簡單 。部分改進:比如「說出荷蘭足球運動員的名字」 , 提前備好名單能大幅加速驗證 , 但仍需人工核對某些冷門名字 。為什么驗證非對稱性如此重要?
深度學習史證明:凡是能被測量的 , 都能被優化 。
在RL框架下 , 驗證能力等同于構建訓練環境的能力 。 由此誕生驗證者定律:
AI解決任務的訓練難度 , 與任務可驗證性成正比 。 所有可解且易驗證的任務 , 終將被AI攻克 。
具體來說 , AI訓練的難易程度取決于任務是否滿足以下條件:
客觀真相:所有人對什么是“好答案”有共識 。
快速驗證:驗證一個答案只需幾秒鐘 。
可擴展驗證:可以同時驗證多個答案 。
低噪聲:驗證結果與答案質量高度相關 。
連續獎勵:可以對多個答案的質量進行排序 。
過去十年 , 主流AI基準測試均滿足前四項——這正是它們被率先攻克的原因 。 盡管多數測試不滿足第五項(非黑即白式判斷) , 但通過樣本平均仍可構造連續獎勵信號 。
為什么可驗證性重要?
根本原因是:當上述條件滿足時 , 神經網絡每一步梯度都攜帶高信息量 , 迭代飛輪得以高速旋轉——這也是數字世界進步遠快于物理世界的秘訣 。
AlphaEvolve的案例谷歌開發的AlphaEvolve堪稱「猜想-驗證」范式的終極形態 。
以「求容納11個單位六邊形的最小外接六邊形」為例:
完美契合驗證者法則五項特性 雖看似對單一問題的「過擬合」 , 但科學創新恰恰追求這種訓練集=測試集的極致優化——因為每個待解問題都可能蘊含巨大價值悟透此理后 , 方覺驗證之不對稱 , 宛如空氣無孔不入 。
試想這樣一個世界:凡能衡量的問題 , 終將告破 。
智能的邊界必將犬牙交錯:在可驗證任務中 , AI所向披靡 , 只因這些領域更易被馴服 。
這般未來圖景 , 怎不令人心馳神往?
參考資料https://www.jasonwei.net/blog/asymmetry-of-verification-and-verifiers-law
https://www.jasonwei.net/blog/life-lessons-from-reinforcement-learning
推薦閱讀










- 我們逛了鏈博會1.4萬平數科館,深扒黃仁勛盛贊的“中國供應鏈奇跡”
- 蘋果投資5億美元加強美國稀土供應鏈
- 九號電動兩輪車鏈博會再亮相 智能與安全成核心標簽
- 浪潮通軟隋志超:以數智技術帶動供應鏈升級,讓AI釋放創新動能
- 人才、創新、綠色:第三屆鏈博會蘋果透露與中國供應鏈的共贏密碼
- 在鏈博會上,我們破解了九號公司的千萬銷量密碼
- 黃仁勛著唐裝亮相鏈博會,將首次公開發表中文演講
- 英特爾參加第三屆鏈博會,鏈動生態共贏智慧未來
- 七彩虹iGame Origo系列游戲本亮相鏈博會:外觀驚艷+性能強悍
- 高通侯明娟鏈博會發聲:深化產業協作以技術創新共筑智能互聯未來