文章圖片

文章圖片

文章圖片

文章圖片
文章圖片
機器之心報道
機器之心編輯部
Mistral AI只是想做歐洲版的OpenAI?最近幾個月 , 由谷歌和 Meta 前研究人員建立的歐洲的 AI 初創公司 Mistral AI 有些躁動不安 。
他們接連發布了好些個開源模型 , 覆蓋不同的領域 , 包含號稱「世界上最優秀」的 OCR 模型、「對標 Claude」的多模態模型、首個推理大模型 Magistral 以及兩天前發布的「全球最佳」的開源語音模型 Voxtral 。
這樣似乎也很難讓這位歐洲 AI「新貴」感到滿意 , 他們還想在應用層面好好地卷一卷 OpenAI 。
他們將 Le Chat 再一次升級 , 引入了一些強大的新功能 , 使其更強大、更直觀 , 也更有趣 , 在功能上幾乎全方位對標 ChatGPT 。
Le Chat 的新功能
- 深度研究模式:即使是復雜主題 , 也能快速生成結構化的研究報告 。
- 語音模式:使用我們的新 Voxtral 模型與 Le Chat 對話 , 而不是用鍵盤輸入 。
- 原生多語言推理:借助我們的推理模型 ——Magistral , 獲取深思熟慮的答案 。
- 項目管理:將您的對話組織到內容豐富的文件夾中 。
- 高級圖像編輯 , 在 Le Chat 中直接進行 , 與 Black Forest Labs 合作 。
研究模式可將 Le Chat 轉變為一個協調的研究助手 , 能夠規劃、明確需求、搜索和綜合信息 。 提出一個有深度的問題 , 它會將其分解 , 收集可靠的資料 , 并構建一個結構清晰、有參考文獻支持且易于理解的報告 。
它由工具增強型深度研究 Agent 驅動 , 但設計得簡單、透明且真正有幫助 , 仿佛與一個組織良好的研究伙伴合作 。
Mistral AI 也在官網展示了一些用例 。 深度研究模式能夠追蹤市場趨勢、撰寫商業策略書、做個人計劃以及最重要的、進行學術研究 。
【Le Chat全方面對標ChatGPT,歐洲AI新貴窮追不舍】語音模式可以像和人聊天一樣與 Le Chat 交流 —— 無需打字 。 你可以在散步時頭腦風暴、在處理雜事時快速獲取答案或轉錄會議內容 。 它由 Mistral 新的語音輸入模型 Voxtral 驅動 , 專為自然、低延遲的語音識別而構建 , 能跟上用戶的工作速度 。
但目前 Le Chat 僅支持語音轉文字的輸入 , 該功能并非實時語音對話 。
所以 , 跟電子助手聊天的功能依舊沒有實現 , 更別提 Grok 4 Ani 那樣的數字伴侶了 。
在圖像編輯功能方面 , 可以通過「移除物體」或「將我放置在另一個城市」等簡單提示來創建并編輯圖像 。 模型支持轉換場景 , 同時保留角色和細節 。 這有助于保證編輯的一致性:可以保持人物、物體和設計元素在圖像之間的不會變得認不出來 。
圖像編輯這塊 , Le Chat 似乎做得出人意料的好 。 網友在論壇分享了使用體驗 , 認為 Le Chat 做得比 OpenAI 更好 。
「OpenAI 的模型在編輯時會改變整個圖像 , 導致無關區域出現細節錯誤 。 (Le Chat)似乎完美地保留了與查詢無關的圖像部分 , 并選擇性地應用編輯 , 這令人印象深刻!」
網友上傳了一張家庭辦公室的照片 , 并提出了以下提示:「修復照片底部略微撕裂的灰色面板 , 讓它們看起來像全新的」 , 編輯結果非常令人滿意 。
上圖為原始圖像 , 下圖為編輯后圖像
對于這些新功能 , 我們的讀者想必已經非常熟悉 。 在這一次的大更新之后 , Le Chat 在功能上基本實現了與 ChatGPT 等行業領先的產品保持一致 。
最近 Mistral AI 的動作確實讓人看到了歐洲在大模型領域保持追趕的勢頭 。 對此 , 網友們表達了對 Mistral 快速追趕的興奮 。
值得分享的是 , Le Chat 在法語中意為「貓」 , 而 Mistral AI 的主頁底部就有一只像素貓咪 , Mistral AI 圖標也形似一只貓貓頭 , 非常可愛 。
Mistral AI 的語音識別模型
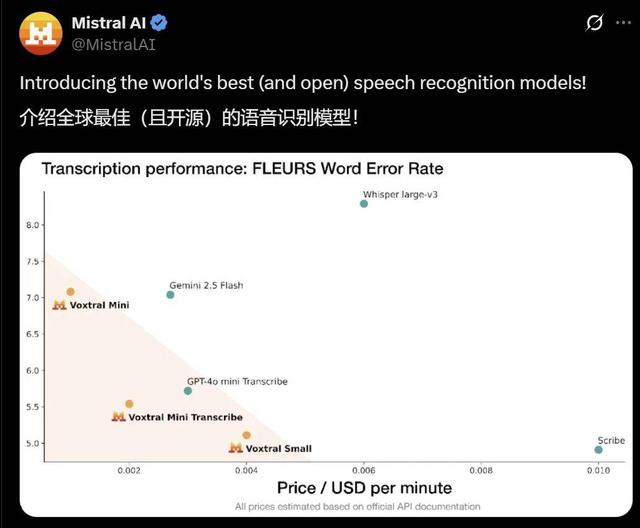
7 月 15 日 , Mistral AI 發布了全新的語音識別模型 Voxtral , 號稱是「全球最佳(且開源)」的語音識別模型 。
Voxtral 在語音轉寫方面全面超越了 Whisper large-v3 , 當前領先的開放源代碼語音轉寫模型 。 它在所有任務中都擊敗了 GPT-4o mini Transcribe 和 Gemini 2.5 Flash , 并在英語短形式和 Mozilla Common Voice 上取得了最先進的結果 , 超越了 ElevenLabs Scribe , 展示了其強大的多語言能力 。
Voxtral 3B 和 Voxtral 24B 模型不僅僅具備語音轉錄功能 , 還具備以下能力:
- 超長上下文理解:支持最長 32k token 的上下文 , 轉錄最長達 30 分鐘音頻 , 理解可達 40 分鐘;
- 內置問答與摘要功能:無需將語音識別與語言模型串聯 , 即可直接針對音頻內容提問或生成結構化摘要;
- 原生多語種支持:具備自動語言識別功能 , 在全球主流語言(如英語、西班牙語、法語、葡萄牙語、印地語、德語、荷蘭語、意大利語等)中均達到業內領先表現 , 助力團隊以單一系統服務全球用戶;
- 從語音直接觸發函數調用:可根據用戶的語音意圖直接觸發后端函數、工作流或 API 調用 , 無需中間解析步驟 , 實現語音到系統指令的無縫轉換;
- 強大的文本理解能力:延續其語言模型基?。 ∕istral Small 3.1)在文本處理方面的高性能表現 。
推薦閱讀













- 剛剛,OpenAI通用智能體ChatGPT Agent正式登場
- 剛剛,OpenAI 發布 ChatGPT 版 Manus!奧特曼:感受 AGI 時刻
- ChatGPT還沒學會打電話,谷歌搜索AI已經替你電話約服務,還會談價砍單
- OpenAI正式引入谷歌云作為戰略供應商,強化ChatGPT全球算力部署
- 倒反天罡:ChatGPT教人說話?36萬視頻+77萬播客已證實
- 小米16外觀曝光:兩款小屏+兩款大屏,全面對標iPhone17系列
- “谷歌搜索”過時了,10秒KO,ChatGPT秒解五年醫學謎團
- WAIC特別企劃視頻欄目《AI面對面》,講出你的「熱AI」故事
- 便宜當真無好貨?面對性能過剩的時代,懂取舍才是關鍵
- 小米16曝光:驍龍8E2+四款機型+橫向大矩陣,全面對標iPhone17