
文章圖片

文章圖片
文章圖片

文章圖片

文章圖片
本文的作者團隊來自北京大學和銀河通用機器人公司 。 第一作者為北京大學計算機學院前沿計算研究中心博士生呂江燃 , 主要研究方向為具身智能 , 聚焦于世界模型和機器人的靈巧操作 , 論文發表于 ICCV , TPAMI , RSS , CoRL , RAL 等機器人頂會頂刊 。 本文的通訊作者為北京大學計算機學院教授王亦洲和北京大學助理教授、銀河通用創始人及CTO 王鶴 。
盡管當前的機器人視覺語言操作模型(VLA)展現出一定的泛化能力 , 但其操作模式仍以準靜態的抓取與放置(pick-and-place)為主 。 相比之下 , 人類在操作物體時常常采用推動、翻轉等更加靈活的方式 。 若機器人僅掌握抓取 , 將難以應對現實環境中的復雜任務 。 例如 , 抓起一張薄薄的銀行卡 , 通常需要先將其推到桌邊;而抓取一個寬大的盒子 , 則往往需要先將其翻轉立起(如圖 1 所示):
這些技能都屬于一個重要的領域:非抓握操作(Non-prehensile Manipulation) 。 非抓握操作泛指不通過夾取、抓握等方式進行物體操控的行為 , 廣泛應用于處理薄片、大型物體、復雜幾何或密集場景下的操作任務 。 然而現實環境的物理屬性比較復雜 , 操作對象的幾何形狀 , 質量 , 桌面的摩擦力等都會成為制約非抓握操作的因素 。 為了實現對上述環境因素全面泛化的非抓握操作技能 , 北京大學與銀河通用提出了自適應性【世界 - 動作】模型 Dynamics-adaptive World Action Model (DyWA)(/di?.v?/) , 協同學習系統的動力學和機器人的精細操作策略 。 該項研究已被 ICCV 2025 接收 。
論文鏈接:https://arxiv.org/abs/2503.16806 論文標題:DyWA: Dynamics-adaptive World Action Model for Generalizable Non-prehensile Manipulation 項目主頁:https://pku-epic.github.io/DyWA/ 代碼倉庫: https://github.com/jiangranlv/DyWA非抓握操作的兩大難點
復雜的接觸建模
【北京大學X銀河通用「世界-動作模型」賦能全面泛化的非抓握技能】與抓取相比 , 非抓握操作涉及連續接觸、多變的摩擦力等復雜物理交互 。機器人推一個物體時 , 摩擦力的微小變化可能導致運動軌跡完全不同:換一塊桌布 , 物體就變得 “推不動” 或 “滑太快”;同一個杯子 , 空的和裝滿水時 , 移動行為完全不同;對于質量分布不均的物體 , 會出現 “旋轉 - 滑動” 的非線性行為 。
傳統的物理建模或優化方法(如 Trajectory Optimization)雖然可以部分求解這些問題 , 但依賴精確的物體質量、摩擦系數、幾何模型 , 這些屬性難以在真實世界獲得 。 目前的學習方法如 CORN、HACMan 等 , 主要側重于僅根據幾何信息推理動作 , 例如 “向左推物體會往左移動” , 但它們缺乏對環境中潛在動力學屬性(如摩擦、質量、彈性等)的建模與適應能力 , 導致在面對真實物理擾動時表現急劇下降 。
現實感知受限:信息缺失 + 噪聲干擾
要實現高質量的非抓取操作 , 機器人必須知道物體在哪里、姿態如何、表面幾何如何接觸 。 這對感知系統提出了極高的要求 。
但在現實中 , 常見傳感器面臨單視角點云嚴重遮擋 , 多視角設置昂貴且繁瑣 , 不適合部署在真實環境或移動平臺上;而已有方法常常假設多視角輸入、額外的位姿追蹤模塊 , 但在現實中難以部署 。
DyWA 的核心方法
1. 世界 - 動作模型:聯合建模動作與未來狀態 , 讓策略具備 “想象力”
DyWA 采用標準的 teacher-student 框架 , 將利用全知信息訓練的強化學習教師策略在線蒸餾給一個僅接收點云輸入的學生模型 。 與傳統方法僅學習動作輸出不同 , DyWA 同時預測動作將帶來的未來狀態 , 相當于讓機器人 “想象” 動作執行后的效果 。 在訓練過程中 , 模型因此能夠隱式建模物理世界的動力學過程 , 從而顯著提升學習效率與泛化能力 。 該模型被稱為 “World Action Model” 。 實驗結果表明 , 這種聯合建模方式可帶來更優的策略優化效果和更強的魯棒性 。
2. 動力學自適應機制:從歷史中 “讀懂” 摩擦、質量等隱含因素
在真實環境中 , 機器人往往無法直接獲知桌面的摩擦系數或物體的質量分布 。 DyWA 引入了一種類似 RMA(Rapid Motor Adaptation)思想的動態適應模塊 , 通過分析歷史觀測和動作序列 , 推理出環境中隱含的物理屬性 , 例如表面是否光滑、物體是否沉重或質量分布是否均勻 。 同時 , 歷史信息還包含更完整的幾何線索 , 彌補了單幀觀測中的缺失 。
該動力學表示通過 FiLM 機制調控世界模型的中間特征 , 使策略在執行過程中能夠動態調整 “用力” 或 “穩住” 的程度 , 實現自適應的物理交互 。
3. 單視角輸入 + 大規模域隨機化仿真訓練 + 零樣本遷移
考慮到現實部署的可行性 , DyWA 設計上僅依賴單個深度相機獲取的點云作為輸入 , 不依賴多攝像頭系統 , 也無需外部位姿追蹤模塊 。 經過對物理參數(摩擦系數 , 物體質心分布等)規模域隨機化訓練后 , 模型能夠實現從仿真到真實機器人的零樣本遷移 , 達成端到端的泛化操控能力 。
DyWA 的全面泛化能力
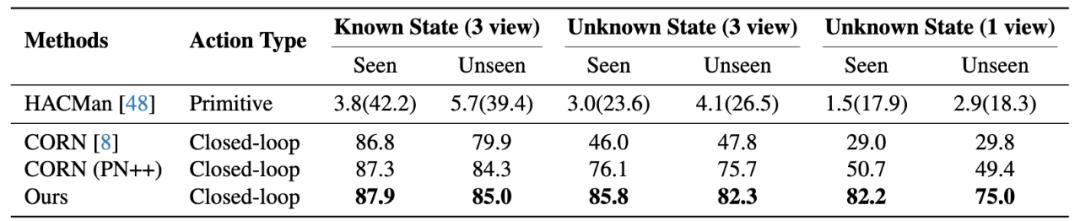
在仿真中 , 本文搭建了一個全面的 benchmark 用以評估目前 learning-based 方法的表現 。 可以看到 , 在已知物體狀態(三視角點云) , 未知物體狀態(三視角點云)和未知物體狀態(單視角點云)三種設置下 , DyWA 都顯著優于基線方法 , 實現了 80 + 成功率的精準操作 。
仿真實驗結果
真機實驗結果
DyWA 可以零樣本遷移到真實世界并展現全面泛化性:
1. 不僅對物體幾何形狀泛化 , 更對物體質量分布泛化: DyWA 能將桌面上任意形狀的未在訓練中見到的物體推到目標 6D 位姿 , 成功率接近 70 。 無論是底重頭輕的咖啡壺 , 或是搖晃著的半滿水瓶 , DyWA 都能實現穩健操作
6 倍速播放
原速播放
2. 適應各種摩擦面:無論是高摩擦的瑜伽墊 , 還是低摩擦易打滑的塑料板 , DyWA 都能自適應控制力度 , 維持操作的魯棒性 。
6 倍速播放
3. 強大的閉環自適應能力:面對光滑的瓶子 , DyWA 能在失敗幾次后適應并成功翻轉瓶子
6 倍速播放
另外 , DyWA 可與抓取策略及視覺語言大模型(VLM)協同工作 。 如圖 1 所示的例子 , 在用戶通過自然語言指定目標位置后 , DyWA 首先將物體推至便于抓取的姿態 , 再由抓取策略完成任務 , 從而顯著提升復雜場景下的整體成功率 。
推薦閱讀













- 卡內基梅隆大學開發出通用音頻理解神器OpenBEATs
- 百度聚焦,心響失寵
- 銀河邊緣:“智能控制場景芯片”供應商,賦能家電、工業互聯網
- 80億預算!中國聯通啟動通用服務器集采,國產算力占比超90%
- 國補價1530元,極窄直屏+240萬分+7000mAh,適合普通用戶入手了
- 從10萬邀請碼到裁員66%:Manus潰敗揭示通用AI Agent的狂歡與泡沫
- 剛剛,OpenAI通用智能體ChatGPT Agent正式登場
- 從“專用”到“通用”—華為 AI 芯片架構大轉向背后的信號
- 智元機器人完成全球首次通用具身機器人工業現場常態化作業直播
- 降幅3100元旗艦!驍龍8Gen3+一英寸主攝,普通用戶五年不用換手機