
文章圖片
文章圖片
文章圖片
近期 , 隨著OpenAI-o1/o3和Deepseek-R1的成功 , 基于強化學習的微調方法(R1-Style)在AI領域引起廣泛關注 。 這些方法在數學推理和代碼智能方面展現出色表現 , 但在通用多模態數據上的應用研究仍有待深入 。
DocTron團隊提出的Chart-R1模型在這一背景下應運而生 , 針對圖表這一信息密集型多模態數據類型 , 開發出一套思維鏈監督和強化的圖表推理方法 , 通過逐步驟的思維鏈監督和數值敏感的強化學習微調實現復雜圖表推理能力 。 圖表分析不僅需要視覺理解 , 還需要進行多步驟的數值推理和關系分析 , 因此這項工作的重要性不言而喻 。
DocTron是一個在通用視覺語言模型架構上實現結構化內容解析和理解的開源項目 , 而無需定制化的模塊開發 , 覆蓋通用文檔、學科公式、圖表代碼等場景 。
論文標題:Chart-R1: Chain-of-Thought Supervision and Reinforcement for Advanced Chart Reasoner 論文鏈接:https://arxiv.org/pdf/2507.15509 Github鏈接:https://github.com/DocTron-hub/Chart-R1 項目開源地址:https://huggingface.co/DocTron 創新點與技術突破
Chart-R1 的核心創新在于其兩階段訓練策略和高質量數據合成方法:
1. 程序化數據合成技術:
研究團隊開發了一種新穎的程序化數據合成技術 , 利用 LLM 生成圖表繪制代碼 , 并基于這些代碼構建復雜問題、多步驟思維鏈推理過程和最終答案 。
這種方法生成了覆蓋單圖表和多子圖表的高質量推理數據 , 構建了包含 258k 多步推理樣本的 ChartRQA 數據集 。 與現有方法相比 , 該技術避免了有損解析過程 , 確保了數據的多樣性和真實性 。
【思維鏈監督和強化的圖表推理,7B模型媲美閉源大尺寸模型】2. 兩階段訓練策略:
Chart-COT 階段:通過思維鏈監督 , 訓練模型將復雜圖表推理任務分解為細粒度、可理解的子任務; Chart-RFT 階段:采用數值敏感的強化學習微調 , 使用群組相對策略優化 (GRPO) , 獎勵信號結合軟匹配和編輯距離 , 專門針對數值和字符串答案提高準確性 。這種兩階段策略的獨特之處在于為兩個階段使用不同的數據集 , 避免了在強化學習過程中模型探索能力的受損 。
實驗結果與性能表現
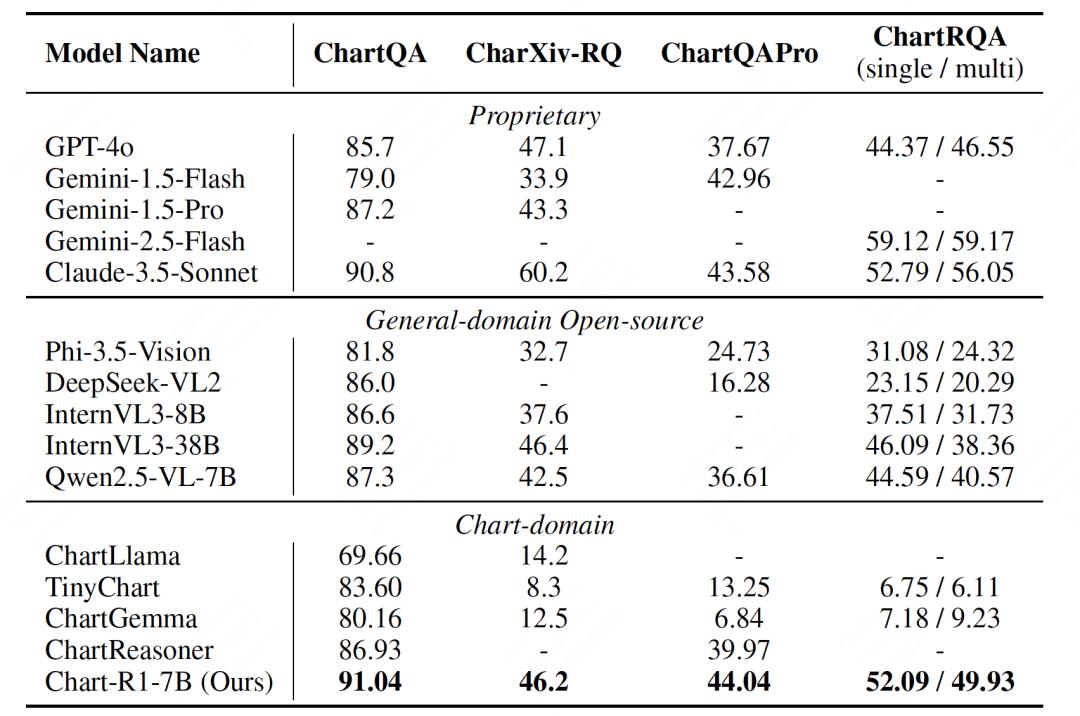
實驗結果令人矚目:Chart-R1 在各種公開基準測試和自建的 ChartRQA 數據集上表現卓越 , 不僅超越了現有的圖表領域方法 , 甚至在多個任務上媲美 GPT-4o 和 Claude-3.5 等閉源大型模型 。
在復雜圖表推理任務上 , 現有視覺語言模型的性能大幅下降 , 而 Chart-R1 依然保持穩定的高水平表現 , 這充分證明了該方法在復雜推理任務上的優越性 。
研究意義與應用前景
該研究不僅在技術上取得了突破 , 也為圖表理解和推理領域提供了新的研究方向:
證明了強化學習在視覺多模態推理任務中的有效性 , 特別是針對需要精確數值推理的場景; 提出的程序化數據合成方法為解決多模態數據稀缺問題提供了新思路; 兩階段訓練策略為構建高效推理模型提供了實用框架 。在實際應用方面 , Chart-R1 可廣泛應用于商業智能分析、科學研究數據解讀、金融報告分析等需要深度圖表理解的場景 , 大幅提升自動化分析效率 。
結論
Chart-R1 的成功表明 , 通過精心設計的訓練策略和高質量數據 , 即使是參數規模相對較小的模型也能在特定領域達到與大型閉源模型相媲美的性能 。 這一研究為構建高效、專業的領域特定 AI 模型提供了寶貴經驗 , 也為未來多模態推理研究指明了方向 。
該工作不僅是對 R1-Style 方法在多模態領域有效性的驗證 , 更是對如何構建高效專業領域模型的重要探索 , 值得學術界和產業界的高度關注 。
推薦閱讀













- 全球手機供應鏈大洗牌!中國從61%跌至25%排名第三,輸給印度、越南
- 深度理解信創:核心概念及產業鏈構成
- 星鏈翻車了,全球化事故,馬賽克致歉!
- OpenAI資金鏈告急,緊急啟動300億美金融資,星際之門現在岌岌可危
- 華為擎云以“全鏈路健康管理”破局傳統醫療割裂難題
- 中國芯“殺”瘋!日媒破防哀嚎:中國芯片產業鏈只差最后一塊拼圖
- 什么是真的AI思維?
- 【2025鏈博會】蘭劍智能高迪:以智能倉儲技術助力供應鏈提質增效
- 思維鏈之父跳槽Meta,不只因為1億美元,離開OpenAI前泄天機
- 我們逛了鏈博會1.4萬平數科館,深扒黃仁勛盛贊的“中國供應鏈奇跡”