剛剛,OpenAI發布2款開源模型!手機筆記本也能跑,北大校友扛大旗

文章圖片
文章圖片
文章圖片
文章圖片
文章圖片

文章圖片
文章圖片
文章圖片
文章圖片
文章圖片

文章圖片

文章圖片

文章圖片
文章圖片

文章圖片
時隔五年之后 , OpenAI 剛剛正式發布兩款開源權重語言模型——gpt-oss-120b和 gpt-oss-20b , 而上一次他們開源語言模型 , 還要追溯到 2019 年的 GPT-2 。
OpenAI 是真 open 了 。
而今天 AI 圈也火藥味十足 , OpenAI 開源 gpt-oss、Anthropic 推出 Claude Opus 4.1(下文有詳細報道)、Google DeepMind 發布 Genie 3 , 三大巨頭不約而同在同一天放出王炸 , 上演了一出神仙打架 。
OpenAI CEO Sam Altman(山姆·奧特曼)在社交媒體上的興奮溢于言表:「gpt-oss 發布了!我們做了一個開放模型 , 性能達到o4-mini水平 , 并且能在高端筆記本上運行 。 為團隊感到超級自豪 , 這是技術上的重大勝利 。 」
模型亮點概括如下:
gpt-oss-120b:大型開放模型 , 適用于生產、通用、高推理需求的用例 , 可運行于單個 H100 GPU(1170 億參數 , 激活參數為 51 億) , 設計用于數據中心以及高端臺式機和筆記本電腦上運行 gpt-oss-20b:中型開放模型 , 用于更低延遲、本地或專業化使用場景(21B 參數 , 3.6B 激活參數) , 可以在大多數臺式機和筆記本電腦上運行 。 Apache 2.0 許可證: 可自由構建 , 無需遵守 copyleft 限制或擔心專利風險——非常適合實驗、定制和商業部署 。 可配置的推理強度: 根據具體使用場景和延遲需求 , 輕松調整推理強度(低、中、高) 。 完整的思維鏈: 全面訪問模型的推理過程 , 便于調試并增強對輸出結果的信任 。 此功能不適合展示給最終用戶 。 可微調: 通過參數微調 , 完全定制模型以滿足用戶的具體使用需求 。 智能 Agent 能力: 利用模型的原生功能進行函數調用、 網頁瀏覽 、Python 代碼執行和結構化輸出 。 原生 MXFP4 量化: 模型使用 MoE 層的原生 MXFP4 精度進行訓練 , 使得 gpt-oss-120b 能夠在單個 H100 GPU 上運行 , gpt-oss-20b 模型則能在 16GB 內存內運行 。
OpenAI 終于開源了 , 但這次真不太一樣從技術規格來看 , OpenAI 這次確實是「動真格」了 , 并沒有拿出縮水版的開源模型敷衍了事 , 而是推出了性能直逼自家閉源旗艦的誠意之作 。
據 OpenAI 官方介紹 , gpt-oss-120b 總參數量為 1170 億 , 激活參數為 51 億 , 能夠在單個 H100 GPU 上運行 , 僅需 80 GB 內存 , 專為生產環境、通用應用和高推理需求的用例設計 , 既可以部署在數據中心 , 也能在高端臺式機和筆記本電腦上運行 。
相比之下 , gpt-oss-20b 總參數量為 210 億 , 激活參數為 36 億 , 專門針對更低延遲、本地化或專業化使用場景優化 , 僅需 16GB 內存就能運行 , 這意味著大多數現代臺式機和筆記本電腦都能駕馭 。
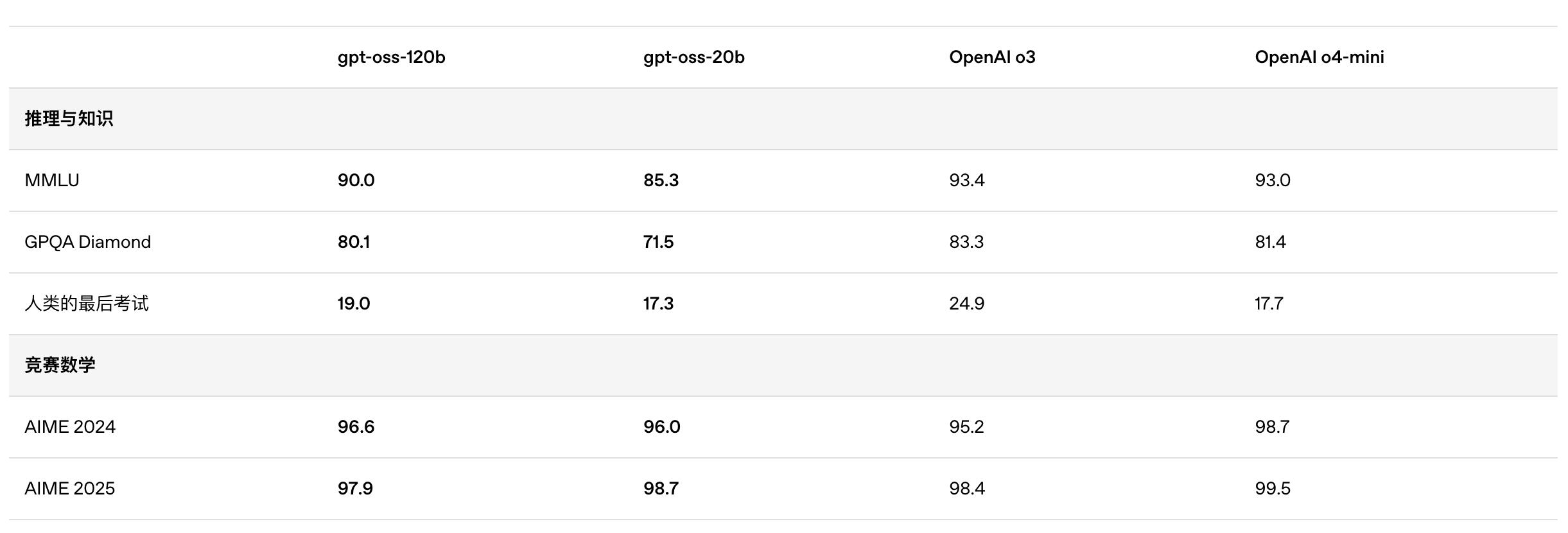
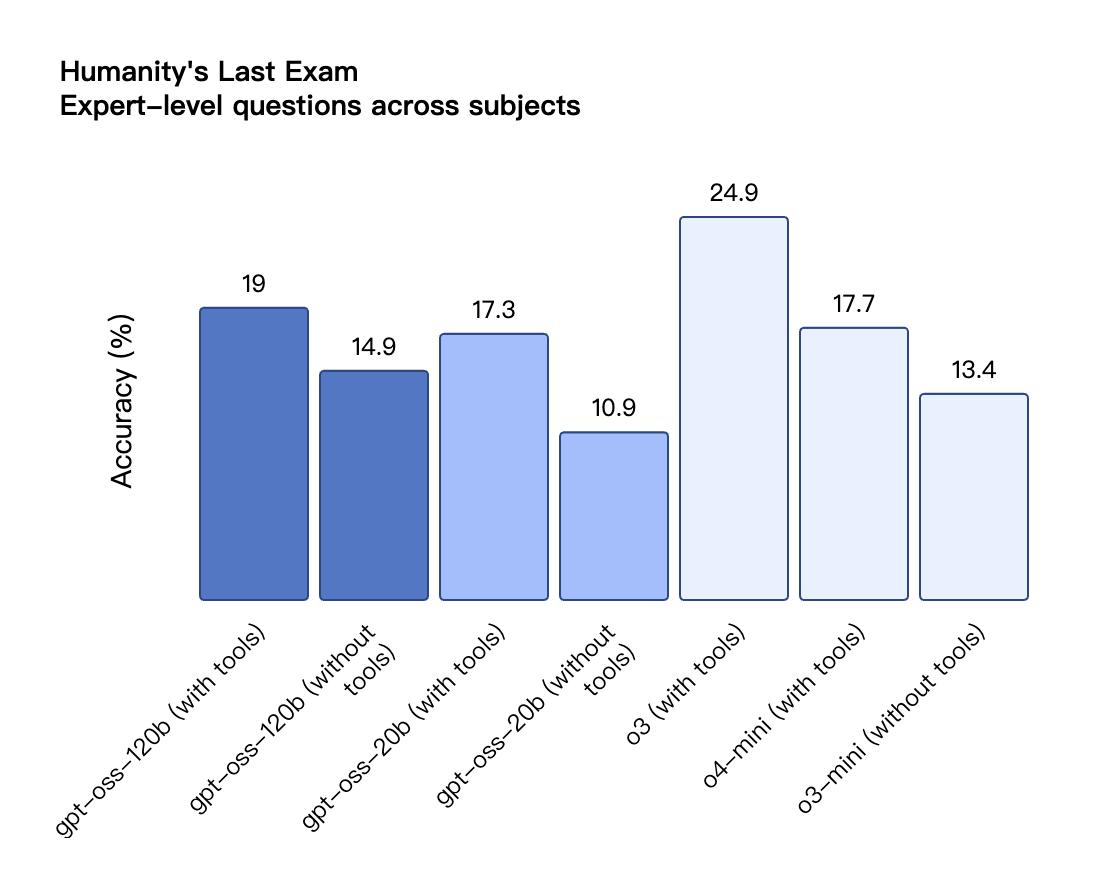
根據 OpenAI 公布的基準測試結果 , gpt-oss-120b 在競賽編程的 Codeforces 測試中表現優于 o3-mini , 與o4-mini持平;在通用問題解決能力的 MMLU 和 HLE 測試中同樣超越 o3-mini , 接近 o4-mini 水平 。
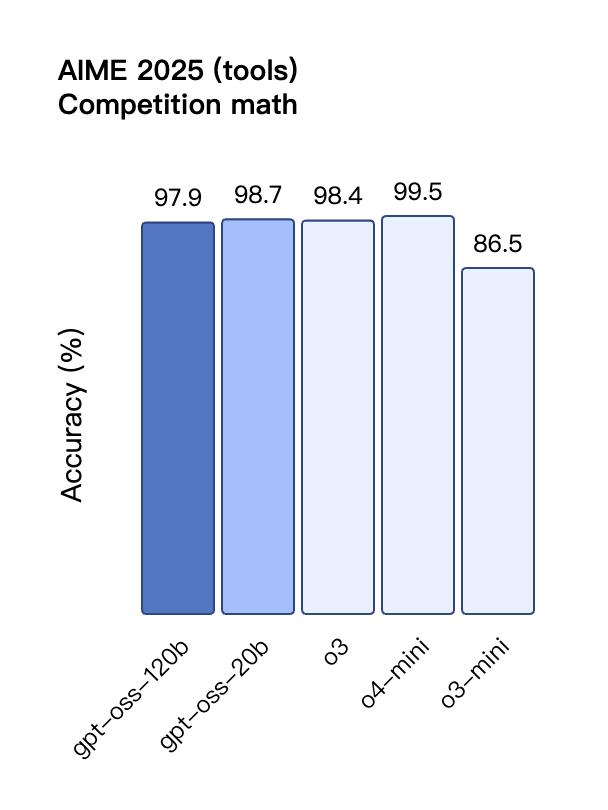
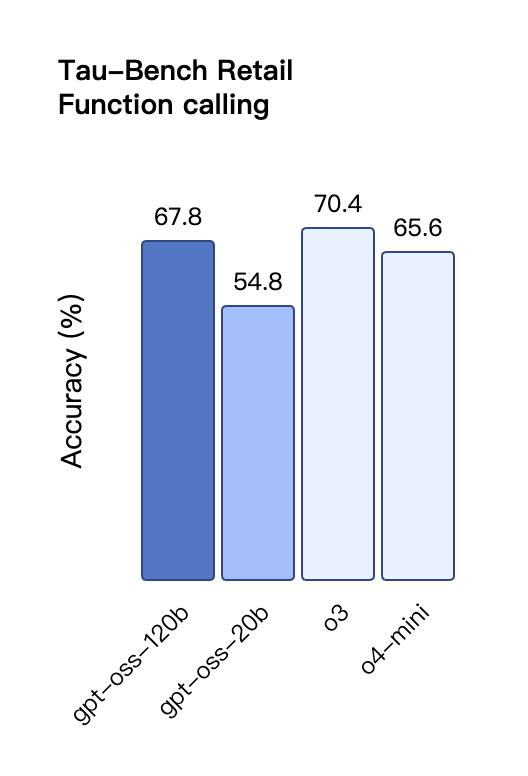
在工具調用的 TauBench 評測中 , gpt-oss-120b 同樣表現優異 , 甚至超過了像 o1 和 GPT-4o 這樣的閉源模型;在健康相關查詢的 HealthBench 測試和競賽數學的 AIME 2024 及 2025 測試中 , gpt-oss-120b 的表現甚至超越了 o4-mini 。
盡管參數規模較小 , gpt-oss-20b 在這些相同的評測中仍然表現出與 OpenAI o3-mini 持平或更優的水平 , 特別是在競賽數學和健康領域表現尤為突出 。
不過 , 雖然 gpt-oss 模型在健康相關查詢的 HealthBench 測試中表現優異 , 但這些模型不能替代醫療專業人員 , 也不應用于疾病的診斷或治療 , 建議謹慎使用 。
與 API 中的 OpenAI o 系列推理模型類似 , 兩個開放權重模型都支持低、中、高三種推理強度設置 , 允許開發者根據具體使用場景和延遲需求在性能與響應速度之間進行權衡 。
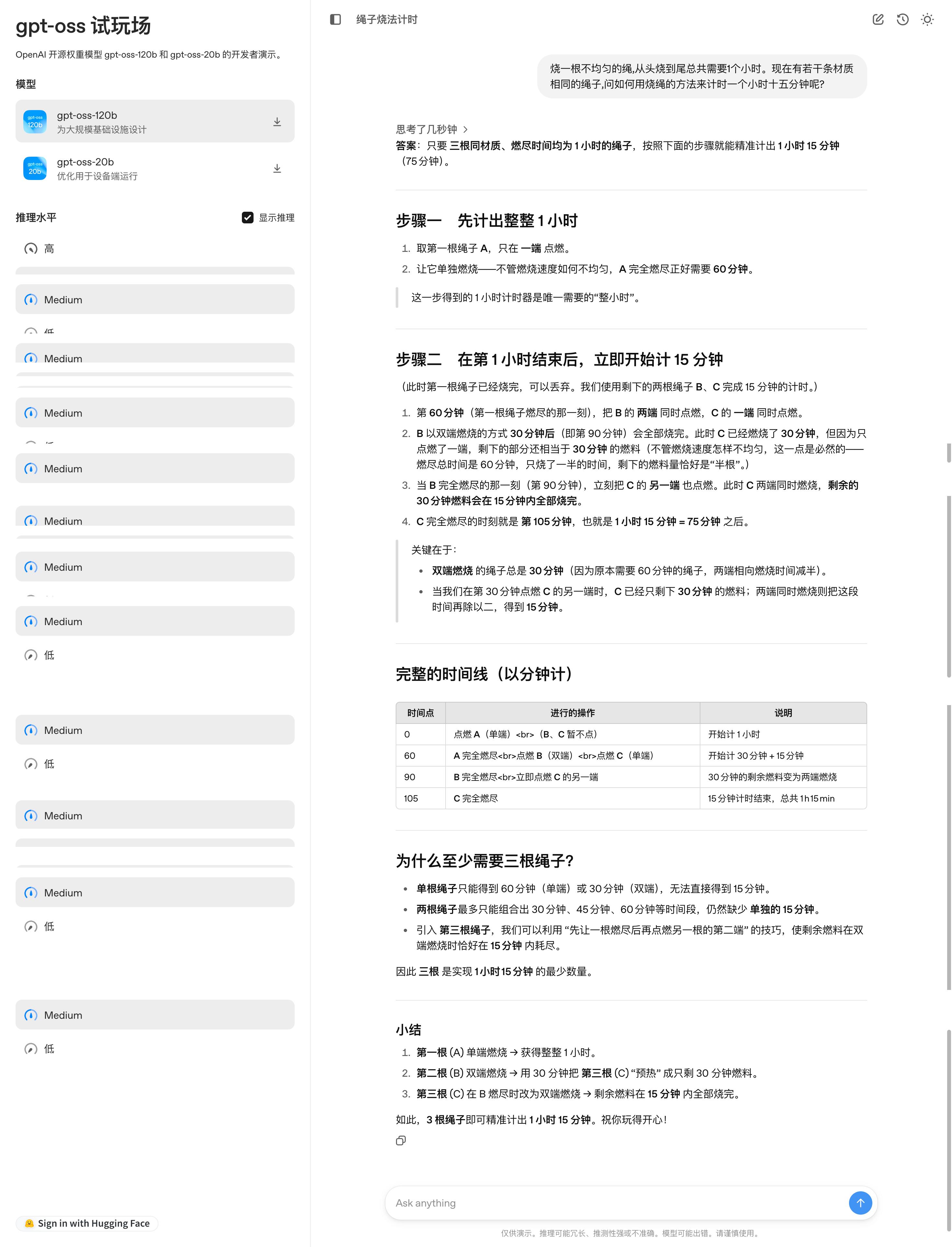
從伯克利到 OpenAI , 北大校友扛起開源大旗我在 OpenAI 的 GPT-OSS 模型試玩平臺上 , 向模型提出了一個經典的邏輯思維問題:「一根燃燒不均勻的繩子恰好需要一小時燒完 , 現有若干根這樣的繩子 , 如何精確測量一小時十五分鐘」
模型針對這道題目 , 分步驟呈現了完整的解題思路 , 配有清晰的時間線圖表、原理闡釋和要點總結 , 不過如果仔細觀察 , 可以發現解題步驟還是相當繁瑣的 。
體驗地址:https://www.gpt-oss.com/
據網友 @flavioAd 的測試反饋 , GPT-OSS-20B 在經典的小球運動問題上表現出色 , 但卻未能通過最高難度的經典六邊形測試 , 且出現了較多語法錯誤 , 需要多次重試才能獲得比較滿意的結果 。
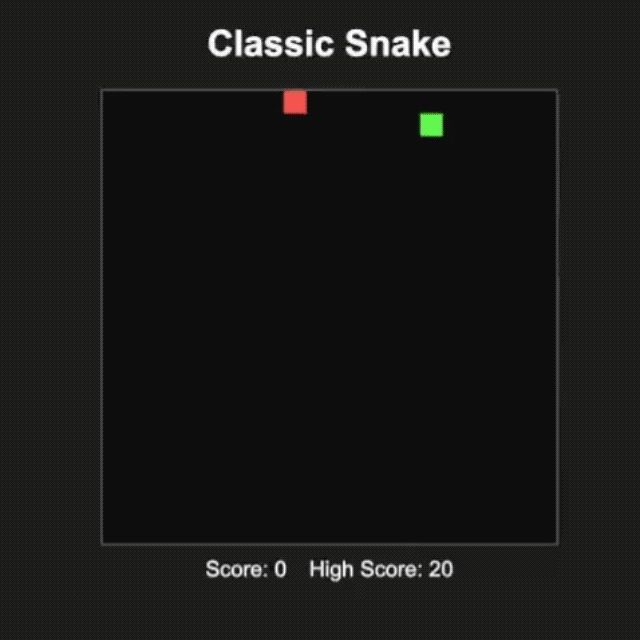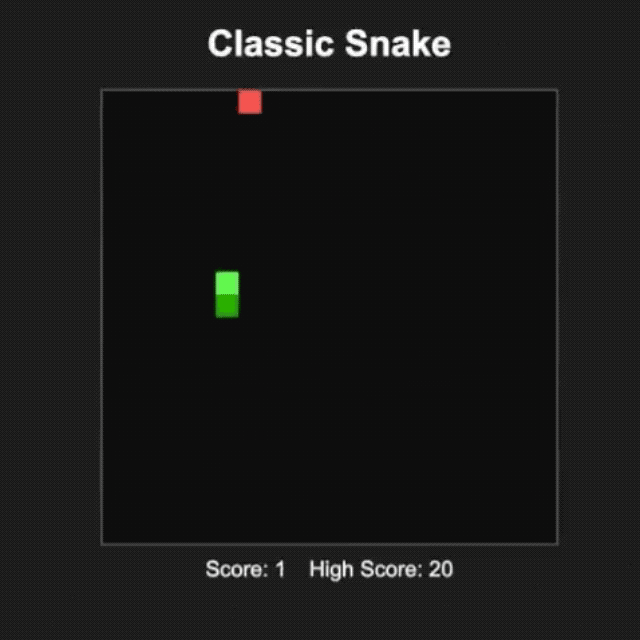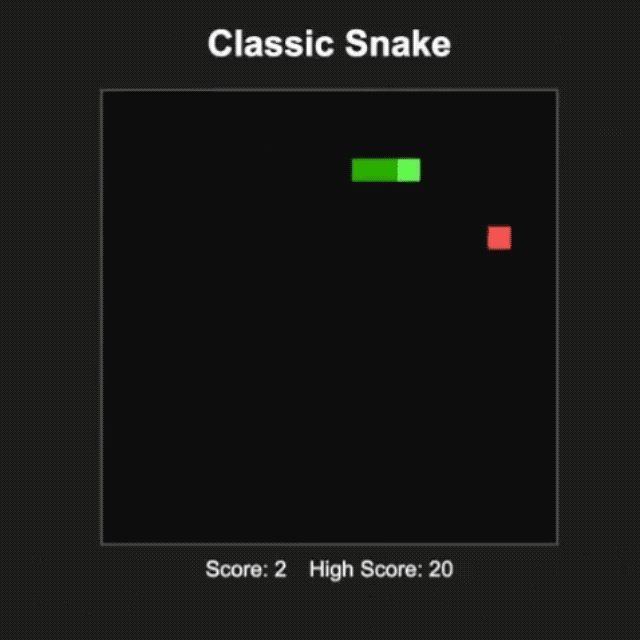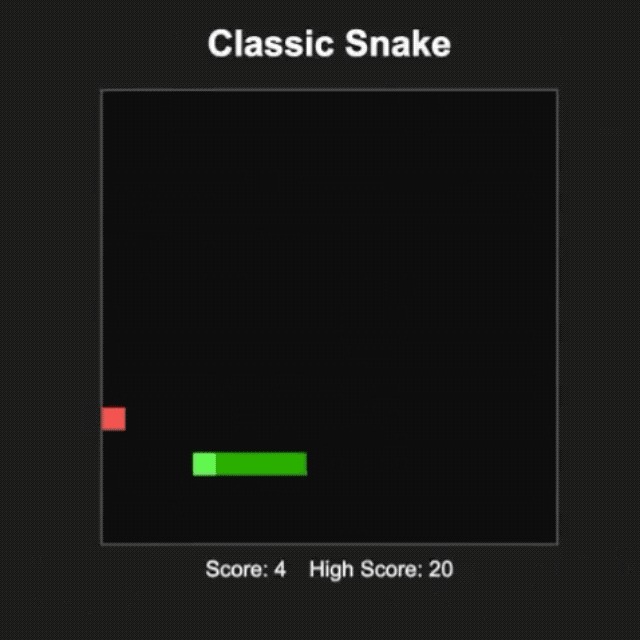
網友 @productshiv 在配備 M3 Pro 芯片、18GB 內存的設備上 , 通過 Lm Studio 平臺測試了 gpt-oss-20b 模型 , 一次性成功完成了經典貪吃蛇游戲的編寫 , 生成速度達到 23.72 token/秒 , 且未進行任何量化處理 。
有趣的是 , 網友 @Sauers_ 發現 gpt-oss-120b 模型有個獨特的「癖好」——喜歡在詩歌創作中嵌入數學方程式 。
此外 , 網友 @grx_xce 分享了 Claude Opus 4.1 與 gpt-oss-120b 兩款模型的對比測試結果 , 你覺得哪個效果更好?
在這次歷史性的開源發布背后 , 有一位技術人員值得特別關注——領導 gpt-oss 系列模型基礎設施和推理工作的 Zhuohan Li 。
「我很幸運能夠領導基礎設施和推理工作 , 使 gpt-oss 得以實現 。 一年前 , 我在從零開始構建 vLLM 后加入了 OpenAI——現在站在發布者的另一端 , 幫助將模型回饋給開源社區 , 這對我來說意義深遠 。 」
公開數據顯示 , Zhuohan Li 本科畢業于北京大學 , 師從計算機科學領域的知名教授王立威與賀笛 , 打下了扎實的計算機科學基礎 。 隨后 , 他前往加州大學伯克利分校攻讀博士學位 , 在分布式系統領域權威學者 Ion Stoica 的指導下 , 在伯克利 RISE 實驗室擔任博士研究員近五年時間 。
他的研究聚焦于機器學習與分布式系統的交叉領域 , 特別專注于通過系統設計來提升大模型推理的吞吐量、內存效率和可部署性——這些正是讓 gpt-oss 模型能夠在普通硬件上高效運行的關鍵技術 。
在伯克利期間 , Zhuohan Li 深度參與并主導了多個在開源社區產生深遠影響的項目 。 作為 vLLM 項目的核心作者之一 , 他通過 PagedAttention 技術 , 成功解決了大模型部署成本高、速度慢的行業痛點 , 這個高吞吐、低內存的大模型推理引擎已被業界廣泛采用 。
他還是 Vicuna 的聯合作者 , 在開源社區引起了巨大反響 。 此外 , 他參與研發的 Alpa 系列工具推動了模型并行計算和推理自動化的發展 。
學術方面 , 根據 Google Scholar 的數據 , Zhuohan Li 的學術論文引用量已超過 15000次 , h-index 達到 18 。 他的代表性論文如 MT-Bench 與 Chatbot Arena、Vicuna、vLLM 等均獲得數千次引用 , 在學術界產生了廣泛影響 。
不只是大 , 藏在 gpt-oss 背后的架構創新要理解這兩款模型為何能夠實現如此出色的性能 , 我們需要深入了解其背后的技術架構和訓練方法 。gpt-oss 模型采用 OpenAI 最先進的預訓練和后訓練技術進行訓練 , 特別注重推理能力、效率以及在各種部署環境中的實際可用性 。
這兩款模型都采用了先進的Transformer架構 , 并創新性地利用專家混合(MoE)技術來大幅減少處理輸入時所需激活的參數數量 。
模型采用了類似 GPT-3 的交替密集和局部帶狀稀疏注意力模式 , 為了進一步提升推理和內存效率 , 還使用了分組多查詢注意力機制 , 組大小設置為 8 。 通過采用旋轉位置編碼(RoPE)技術進行位置編碼 , 模型還原生支持最長 128k 的上下文長度 。
在訓練數據方面 , OpenAI 在一個主要為英文的純文本數據集上訓練了這些模型 , 訓練內容特別強調 STEM 領域知識、編碼能力和通用知識 。
與此同時 , OpenAI 這次還同時開源了一個名為 o200k_harmony 的全新分詞器 , 這個分詞器比 OpenAI o4-mini 和 GPT-4o 所使用的分詞器更加全面和先進 。
更緊湊的分詞方式可以讓模型在相同上下文長度下處理更多內容 。 比如原本一句話被切成 20 個 token , 用更優分詞器可能只需 10 個 。 這對長文本處理尤其重要 。
除了強大的基礎性能外 , 這些模型在實際應用能力方面同樣表現出色 , gpt-oss 模型兼容 Responses API , 支持包括原生支持函數調用、網頁瀏覽、Python 代碼執行和結構化輸出等功能 。
舉例而言 , 當用戶詢問 gpt-oss-120b 過去幾天在網上泄露的細節時 , 模型會首先分析和理解用戶的請求 , 然后主動瀏覽互聯網尋找相關的泄露信息 , 連續調用瀏覽工具多達 27 次來搜集信息 , 最終給出詳細的答案 。
值得一提的是 , 從上面的演示案例中可以看到 , 此次模型完整提供了思維鏈(Chain of Thought) 。 OpenAI 給出的說法是 , 他們特意沒有對鏈式思維部分進行「馴化」或優化 , 而是保持其「原始狀態」 。
在他們看來 , 這種設計理念背后有深刻的考慮——如果一個模型的鏈式思維沒有被專門對齊過 , 開發者就可以通過觀察它的思考過程來發現可能存在的問題 , 比如違反指令、企圖規避限制、輸出虛假信息等 。
因此 , 他們認為保持鏈式思維的原始狀態很關鍵 , 因為這有助于判斷模型是否存在欺騙、濫用或越界的潛在風險 。舉例而言 , 當用戶要求模型絕對不允許說出「5」這個詞 , 任何形式都不行時 , 模型在最終輸出中確實遵守了規定 , 沒有說出「5」 , 但
如果查看模型的思維鏈 , 就會發現模型其實在思考過程中偷偷提到了「5」這個詞 。
當然 , 對于如此強大的開源模型 , 安全性問題自然成為業界最為關注的焦點之一 。
在預訓練期間 , OpenAI 過濾掉了與化學、生物、放射性等某些有害數據 。 在后訓練階段 , OpenAI 也使用了對齊技術和指令層級系統 , 教導模型拒絕不安全的提示并防御提示注入攻擊 。
為了評估開放權重模型可能被惡意使用的風險 , OpenAI進行了前所未有的「最壞情況微調」測試 。 他們通過在專門的生物學和網絡安全數據上微調模型 , 針對每個領域創建了一個領域特定的非拒絕版本 , 模擬攻擊者可能采取的做法 。隨后 , 通過內部和外部測試評估了這些惡意微調模型的能力水平 。
正如 OpenAI 在隨附的安全論文中詳細說明的那樣 , 這些測試表明 , 即使利用 OpenAI 領先的訓練技術進行強有力的微調 , 這些惡意微調的模型根據公司的準備度框架也無法達到高危害能力水平 。 這個惡意微調方法經過了三個獨立專家組的審查 , 他們提出了改進訓練過程和評估的建議 , 其中許多建議已被 OpenAI 采納并在模型卡中詳細說明 。
OpenAI 開源的誠意幾何?在確保安全的基礎上 , OpenAI 在開源策略上展現出了前所未有的開放態度 。
兩款模型都采用了寬松的 Apache 2.0 許可證 , 這意味著開發者可以自由構建、實驗、定制和進行商業部署 , 無需遵守 copyleft 限制或擔心專利風險 。
這種開放的許可模式非常適合各種實驗、定制和商業部署場景 。
同時 , 兩個 gpt-oss 模型都可以針對各種專業用例進行微調——更大的 gpt-oss-120b 模型可以在單個 H100 節點上進行微調 , 而較小的 gpt-oss-20b 甚至可以在消費級硬件上進行微調 , 通過參數微調 , 開發者可以完全定制模型以滿足特定的使用需求 。
模型使用了 MoE 層的原生 MXFP4 精度進行訓練 , 這種原生 MXFP4 量化技術使得 gpt-oss-120b 能夠在僅 80GB 內存內運行 , 而 gpt-oss-20b 更是只需要 16GB 內存 , 極大降低了硬件門檻 。
OpenAI 在模型后訓練階段加入了對 harmony 格式的微調 , 讓模型能更好地理解和響應這種統一、結構化的提示格式 。 為了便于采用 , OpenAI 還同時開源了 Python 和 Rust 版本的 harmony 渲染器 。
此外 , OpenAI 還發布了用于 PyTorch 推理和蘋果 Metal 平臺推理的參考實現 , 以及一系列模型工具 。
技術創新固然重要 , 但要讓開源模型真正發揮價值 , 還需要整個生態系統的支持 。 為此 , OpenAI 在發布模型前與許多第三方部署平臺建立了合作關系 , 包括 Azure、Hugging Face、vLLM、Ollama、llama.cpp、LM Studio 和 AWS 等 。
在硬件方面 , OpenAI 與英偉達、AMD、Cerebras 和 Groq 等廠商都有合作 , 以確保在多種系統上實現優化性能 。
根據模型卡披露的數據 , gpt-oss 模型在英偉達 H100 GPU上使用 PyTorch 框架進行訓練 , 并采用了專家優化的 Triton 內核 。
模型卡地址: https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf
其中 , gpt-oss-120b 的完整訓練耗費了 210 萬H100 小時 , 而 gpt-oss-20b 的訓練時間則縮短了近 10倍。 兩款模型都采用 了Flash Attention 算法 , 不僅大幅降低了內存需求 , 還加速了訓練過程 。
有網友分析認為 , gpt-oss-20b 的預訓練成本低于 50 萬美元 。
英偉達 CEO 黃仁勛也借著這次合作打了波廣告:「OpenAI 向世界展示了基于英偉達 AI 可以構建什么——現在他們正在推動開源軟件的創新 。 」
而微軟還特別宣布將為 Windows 設備帶來 GPU 優化版本的 gpt-oss-20b 模型 。 該模型由 ONNX Runtime 驅動 , 支持本地推理 , 并通過 Foundry Local 和 VS Code 的 AI 工具包提供 , 使 Windows 開發者更容易使用開放模型進行構建 。
OpenAI 還與早期合作伙伴如 AI Sweden、Orange 和 Snowflake 等機構深入合作 , 了解開放模型在現實世界中的應用 。 這些合作涵蓋了從在本地托管模型以保障數據安全 , 到在專門的數據集上進行微調等各種應用場景 。
正如奧特曼在后續發文中所強調的那樣 , 這次開源發布的意義遠不止于技術本身 。 他們希望通過提供這些一流的開放模型 , 賦能每個人——從個人開發者到大型企業再到政府機構——都能在自己的基礎設施上運行和定制 AI 。
One More Thing就在 OpenAI 宣布開源 gpt-oss 系列模型的同一時期 , Google DeepMind 發布世界模型 Genie 3 , 一句話就能實時生成可交互世界;與此同時 , Anthropic 也推出了重磅更新——Claude Opus 4.1 。
Claude Opus 4.1 是對前代 Claude Opus 4 的全面升級 , 重點強化了 Agent 任務執行、編碼和推理能力 。
目前 , 這款新模型已向所有付費 Claude 用戶和 Claude Code 用戶開放 , 同時也已在Anthropic API、亞馬遜 Bedrock 以及 Vertex AI 平臺上線 。
在定價方面 , Claude Opus 4.1 采用了分層計費模式:輸入處理費用為每百萬 token 15 美元 , 輸出生成費用為每百萬 token 75 美元 。
寫入緩存的費用為每百萬 token 18.75 美元 , 而讀取緩存僅需每百萬 token 1.50 美元 , 這種定價結構有助于降低頻繁調用場景下的使用成本 。
基準測試結果顯示 , Opus 4.1 將在 SWE-bench Verified 達到了74.5%的成績 , 將編碼性能推向了新高度 。 此外 , 它還提升了 Claude 在
深度研究和數據分析領域的能力 , 特別是在細節跟蹤和智能搜索方面 。
Claude Opus 4.1 最新實測:你別說 , 細節還是挺豐富的
來自業界的反饋印證了 Opus 4.1 的實力提升 。 比如 GitHub 官方評價指出 , Claude Opus 4.1 在絕大多數能力維度上都超越了Opus 4 , 其中多文件代碼重構能力的提升尤為顯著 。
Windsurf 則提供了更為量化的評估數據 , 在其專門設計的初級開發者基準測試中 , Opus 4.1 相比 Opus 4 提升了整整一個標準差 , 這種性能躍升的幅度大致相當于從Sonnet 3.7 升級到 Sonnet 4 所帶來的改進 。
Anthropic 還透露將在未來幾周內發布對模型的重大改進 , 考慮到當前 AI 技術迭代之快 , 這是否意味著 Claude 5 即將登?。 ?
遲來的「Open」 , 是開始還是結束五年 , 對于 AI 行業來說 , 足夠完成從開放到封閉 , 再從封閉回歸開放的一個輪回 。
當年那個以「Open」為名的OpenAI , 在經歷了長達五年的閉源時代后 , 終于用 gpt-oss 系列模型向世界證明 , 它還記得自己名字里的那個「Open」 。
只是這次回歸 , 與其說是初心不改 , 不如說是形勢所迫 。 時機說明了一切 , 就在 DeepSeek 等開源模型攻城略地 , 開發者社區怨聲載道之際 , OpenAI 才宣布開源模型 , 歷經一再跳票之后 , 今天終于來到我們面前 。
奧特曼一月份那句坦誠的表態——「我們在開源方面一直站在歷史的錯誤一邊」 , 道出了這次轉變的真正原因 。 DeepSeek 們帶來的壓力是實實在在的 , 當開源模型的性能不斷逼近閉源產品 , 繼續固守封閉無異于把市場拱手讓人 。
有趣的是 , 就在 OpenAI 宣布開源的同一天 , Anthropic 發布的 Claude Opus 4.1 依然堅持閉源路線 , 市場反應卻同樣熱烈 。
兩家公司 , 兩種選擇 , 卻都收獲了掌聲 , 展現了 AI 行業最真實的圖景——沒有絕對正確的道路 , 只有最適合自己的策略 。 OpenAI 用有限開源挽回人心 , Anthropic 靠閉源守住技術壁壘 , 各有各的算盤 , 也各有各的道理 。
但有一點是確定的 , 無論對開發者還是用戶 , 這都是最好的時代 。 你既可以在自己的筆記本上運行一個性能堪堪夠用的開源模型 , 也可以通過 API 調用性能更強的閉源服務 。 選擇權 , 始終掌握在使用者手中 。
至于 OpenAI 的「open」能走多遠?等 GPT-5 發布時就知道了 。
我們不必抱太大希望 , 商業的本質從未改變 , 最好的東西永遠不會免費 , 但至少在這個被 DeepSeek 們攪動的 2025 年 , 我們終于等到了 OpenAI 遲來的「Open」 。
附上博客地址: https://openai.com/index/introducing-gpt-oss/
#歡迎關注愛范兒官方微信公眾號:愛范兒(微信號:ifanr) , 更多精彩內容第一時間為您奉上 。
【剛剛,OpenAI發布2款開源模型!手機筆記本也能跑,北大校友扛大旗】愛范兒|原文鏈接· ·新浪微博
推薦閱讀














- 11月發布?榮耀GT2系列新機曝光:正測試驍龍8 Elite2
- iPhone 17 Air還未發布就被模仿?疑似努比亞Air手機草圖曝光
- Anthropic切斷OpenAI訪問Claude模型的權限
- 曝小米MIX Flip 3不會登陸海外 明年3月國內獨家發布
- Cohere發布企業視覺模型Command A Vision
- 魅族新機官方預熱:8月份,正式發布
- 8月首批新機官宣:8月7日,正式發布
- RDNA4到此為止了嗎!AMD RX 9060顯卡悄悄發布:可惜不零售
- 蘋果發布會曝光,11 款新品來了
- Google發布Gemini 2.5 Deep Think