
文章圖片
文章圖片
文章圖片
中國科學院磐石研發團隊 投稿
量子位 | 公眾號 QbitAI
科研er看過來!還在反復嘗試材料組合方案 , 耗時又耗力?
新型“神經-符號”融合規劃器直接幫你一鍵鎖定高效又精準的科研智能規劃 。
不同于當前效率低下、盲目性高的傳統智能規劃方法 , 中國科學院磐石研發團隊此次提出的混合規劃器 , 同時融合了神經規劃系統和符號規劃系統的優勢 。
借鑒人類的閉環反饋機制 , 構建雙向規劃機制 , 在表達能力、適應能力、泛化能力以及可解釋性上都實現了顯著提升 。
還能只在正向規劃器需要時 , 自動激活反饋接收 , 在規劃覆蓋率和規劃效率上均顯著優于OpenAI o1 。
目前該智能規劃器已加入“磐石·科學基礎大模型” , 該項目已面向科學領域集成了一系列專用模型 。
借鑒人類運動學習的“反饋閉環理念”基于Knowledge of Result(KR)的閉環系統是人類運動學習的關鍵部分 , 可以幫助學習者糾正錯誤 , 向著目標方向實現有效學習 。
在運動學習中KR是執行運動后的增強信息 , 表明既定目標是否成功 , 而閉環系統是以反饋、錯誤檢測和錯誤糾正為核心的過程 。
規劃任務中的問題、規劃器和動作序列可近似對應于人類運動學習中的試驗、學習者和行動序列 , 規劃任務與運動學習有較強的相似性 。
反饋閉環與對應的規劃問題
因此 , “神經-符號”融合規劃器通過借鑒人類運動學習中的反饋閉環理念 , 構建了一種閉環反饋的雙向規劃機制——KRCL(Knowledge-of-Results based Closed-Loop) , 正向神經規劃器生成問題的動作序列與反向KR反饋機制構成動態的錯誤檢測-糾正閉環 。
通過有效利用信息的雙向傳遞和反饋來評估和調整動作 , 在規劃中研究以KR信息為中心的閉環規劃結構 , 實現準確的反饋以加強錯誤檢測和錯誤糾正 , 持續評估和調整規劃器的動作 , 從而促進規劃器的有效學習 。
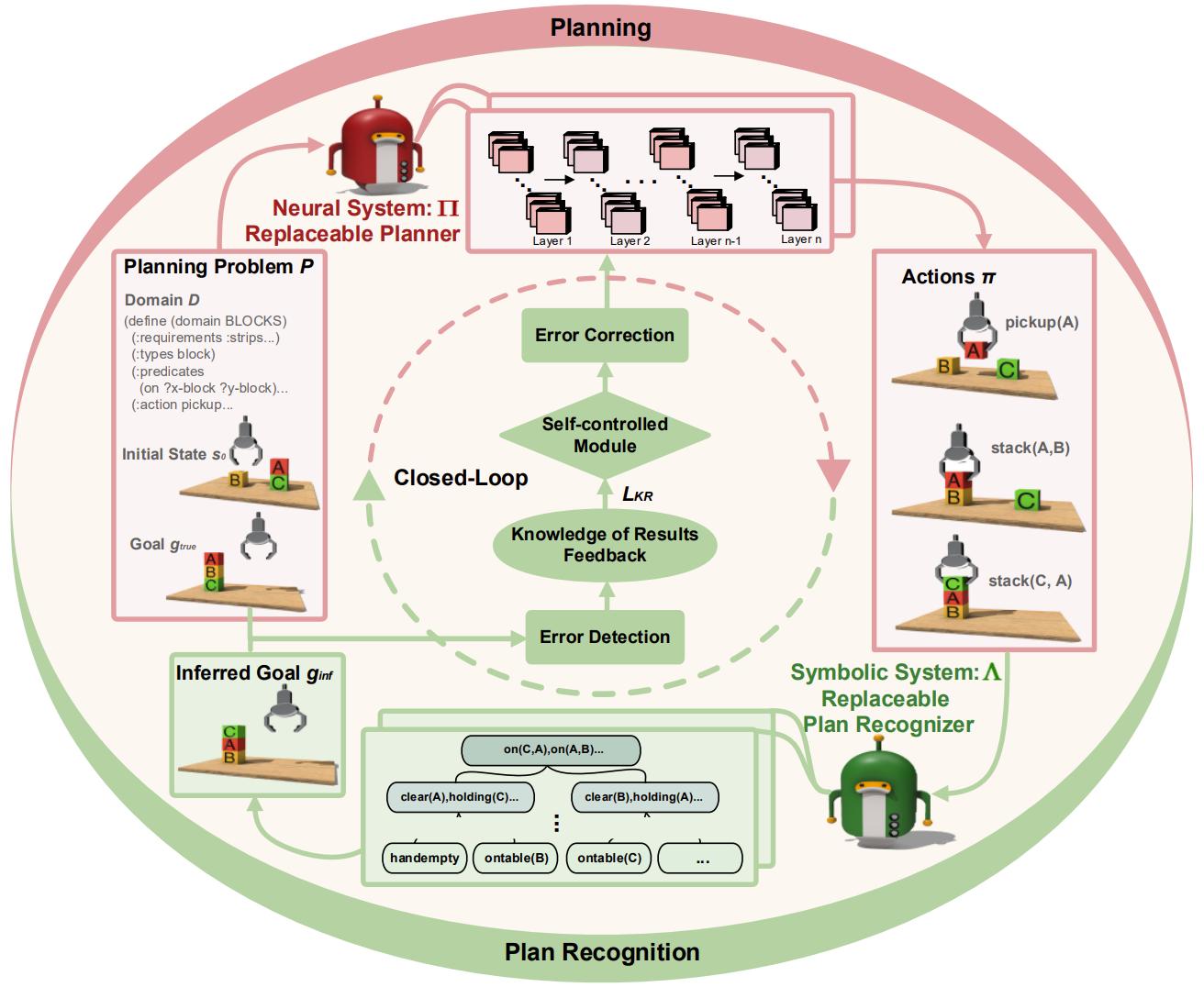
神經規劃器與符號規劃識別器融合“磐石”研發團隊構建了一種神經規劃器與符號規劃識別器的新型融合模式 , 實現了神經系統與符號系統之間的雙向連接 , 通過利用兩種范式的互補優勢 , 在規劃中同時實現的有效學習和推理 。
其中 , 正向的神經規劃器和反向的符號規劃識別器構成KR閉環結構 。
“神經-符號”融合新型規劃器架構
在正方向 , 神經規劃器利用其強大的表示和學習能力生成規劃問題的動作序列 , 可提高規劃效率和靈活性 。
在反方向 , 動作序列則被輸入到符號規劃識別器中 , 推理出最可能的規劃目標 。
符號規劃識別器具備準確、可靠和可解釋性等優勢 , 可幫助神經網絡訓練、學習和推理 , 進而提高模型的可解釋性 。
實現正反向閉環的KR增強信息則利用文本相似度方法來量化 , 通過比較推理目標和真實目標來計算它們的相似度 。
KR強信息賦予規劃器思考能力并對結果進行校正 。 閉環反饋過程兼顧有效學習與推理能力 , 促進規劃器糾正錯誤并能夠更精準地指導規劃器尋找正確的解決方案 。
只在“需要”的時候接收反饋人類運動學習中 , 傳統的固定KR機制由指導者控制KR信息 , 限制了學習者的學習動機和獲取的反饋信息 。
為了解決該問題 , 提出了自我控制機制 , 允許學習者決定何時獲得KR , 這種方式不僅可以增強學習動機 , 還可以增強信息處理能力 , 特別是可以提高閉環系統的錯誤檢測和錯誤糾正能力 。
面向規劃問題的自我控制機制
此外 , 過多的KR增強反饋會使正向規劃器依賴于KR , 導致短期表現提升 , 但會影響模型的長遠表現和遷移能力 。
因此 , “磐石”研發團隊提出了面向規劃問題的自我控制機制 , 從規劃問題的難度和模型表現兩方面展開研究 。
一方面 , 評估規劃問題的難度 , 基于規劃問題的對象、狀態、動作三個重要元素來計算每個問題的難度 , 當難度超過預定義的閾值時激活反向規劃識別器 。
另一方面 , 當正向規劃器表現不佳時 , 反向規劃識別器也會被觸發 。
自我控制機制使得反向規劃識別器只在正向規劃器“需要”的時候被激活 , 以優化正向規劃器接收反饋的頻率 , 減少規劃器對反饋的依賴 , 進而提高模型的自主性 , 另外也為規劃器提供了更高的學習效率 。
它在適當時機選擇性地引入KR反饋 , 避免了固定KR策略中的反饋冗余問題 , 從而在規劃器的學習過程中實現了更快的收斂和更高的覆蓋率 。
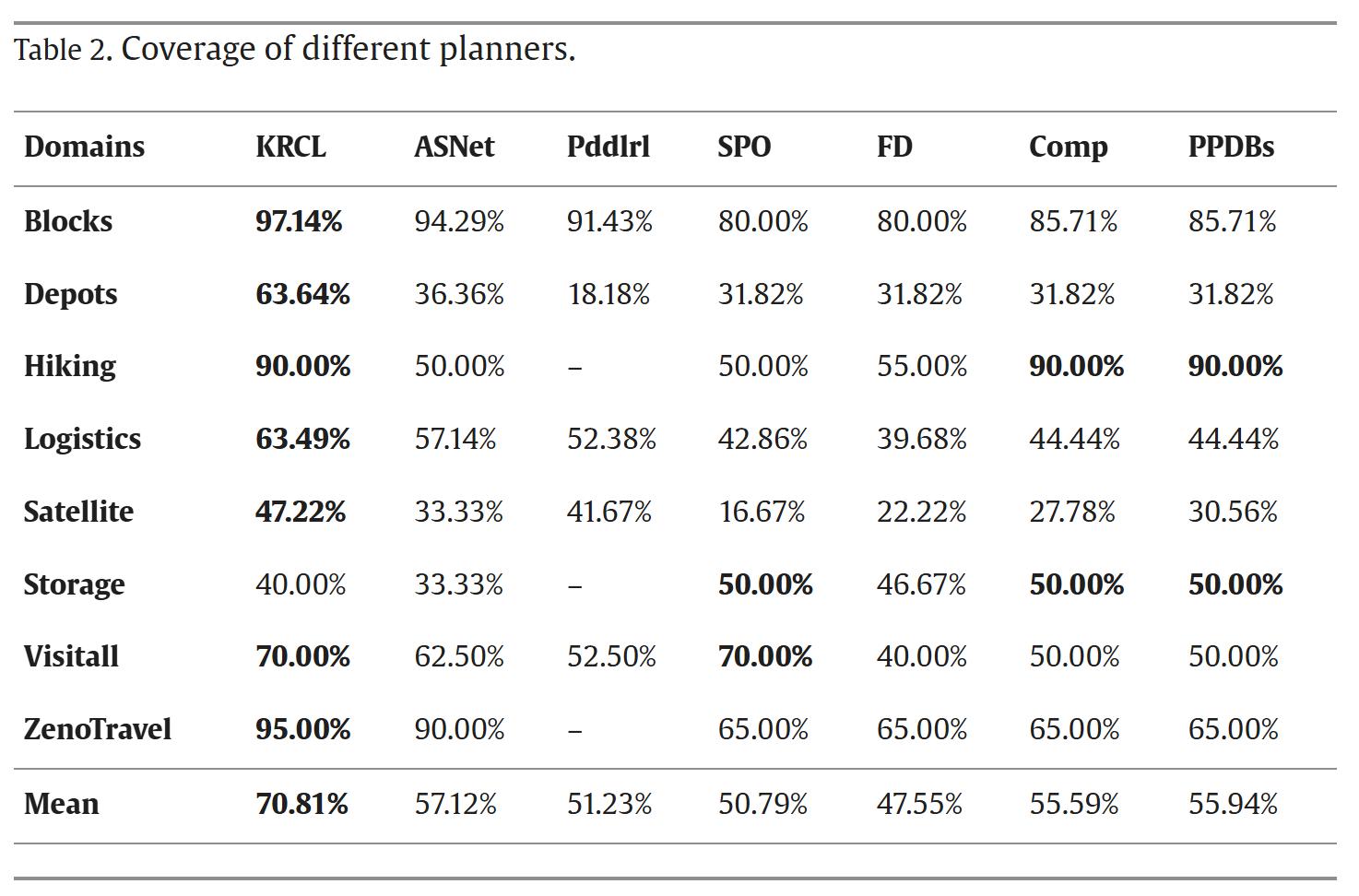
規劃覆蓋率和規劃效率顯著領先研發團隊在國際IPC(International Planning Competition)競賽的8個代表性規劃任務上系統性地評估了KRCL的性能 。
8個代表性規劃任務上的系統評估
結果顯示KRCL的平均覆蓋率顯著優于其他對比規劃器 , 證明了所提出的基于神經-符號融合的雙向規劃器可以指導規劃器尋找正確的解決方案 , 精準有效地解決規劃任務 。
此外 , 團隊還在PlanBench(用于評估大語言模型規劃性能的基準數據集)上對KRCL與大型語言模型OpenAI o1在規劃任務中的性能進行了對比 。
PlanBench上的性能對比
實驗結果表明 ,KRCL在規劃覆蓋率和規劃效率方面均顯著優于OpenAI o1 , 進一步驗證了該方法在規劃任務中的優勢 。
KRCL通過神經和符號系統優勢互補 , 能夠有效提升規劃性能 , 并利用其強大的閉環反饋機制、精準的推理校正能力以及高效的自主規劃特性 , 可為各類科學研究任務提供更可靠、更智能的規劃工具 。
論文鏈接:https://www.sciencedirect.com/science/article/abs/pii/S095070512501086X?via%3Dihub
— 完 —
量子位 QbitAI
【“神經-符號”融合規劃器性能顯著超越o1:借鑒人類運動學習機制】關注我們 , 第一時間獲知前沿科技動態
推薦閱讀










- 愛好者花費6年時間 造出世界上最不實用顯示器!1000個木制“像素”
- 2025國補后,被“嚴重低估”的3款手機,16GB+512GB跌至“真香價”
- 小尺寸平板怎么就突然火了?仔細一分析,它還真是“神器”
- 庫克興奮“劇透”:蘋果未來產品路線圖“絕了”
- iPhone16 Pro進入“清倉期”,跌價2301元,價格“雪崩”
- HarmonyOS 6.0亮相:純血鴻蒙的“AI大腦”終于進化了
- 如何看“中國缺的是光刻機,不是手機芯片設計”這樣的言論?
- 面對AI業務的困境,蘋果選擇了吃“回頭草”
- 蘋果收獲四年來最佳財報,在華營收重回增長,感謝中國“國補”
- 安卓機的“原生磁吸充電”,為啥就這么難