
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
本項目的領導者為李萌 , 于 2022 年加入北京大學人工智能研究院和集成電路學院創建高效安全計算實驗室 。 他曾任職于美國 Facebook 公司的 Reality Lab , 作為技術主管主導虛擬現實和增強現實設備中的高效 AI 算法和芯片研究 。 他的研究興趣集中于高效、安全人工智能加速算法和芯片 , 旨在通過算法到芯片的跨層次協同設計和優化 , 為人工智能構建高能效、高可靠、高安全的算力基礎 , 曾獲 DAC 生成式人工智能系統設計競賽第一名、AICAS 大模型系統設計競賽第一名、CCF 集成電路 Early Career Award、歐洲設計自動化協會最佳博士論文等一系列獎項 。
在數據隱私日益重要的 AI 時代 , 如何在保護用戶數據的同時高效運行機器學習模型 , 成為了學術界和工業界共同關注的難題 。
北大團隊最新完成的綜述《Towards Efficient Privacy-Preserving Machine Learning: A Systematic Review from Protocol Model and System Perspectives》系統性地梳理了當前隱私保護機器學習(PPML)領域的三大優化維度 , 首次提出跨協議、模型和系統三個層級的統一視角 , 為學術界和工業界提供了更加清晰的知識脈絡與方向指引 。
本文由北京大學助理教授李萌課題組和螞蟻集團機構的多位研究者共同完成 。 論文題目及完整作者列表如下:
論文標題:Towards Efficient Privacy-Preserving Machine Learning: A Systematic Review from Protocol Model and System Perspectives 論文地址:https://arxiv.org/pdf/2507.14519
團隊還建立了一個長期維護的 GitHub 項目 , 持續收錄高質量 PPML 文獻 , 歡迎大家 star , 并提出寶貴的意見和補充:
文獻庫:https://github.com/PKU-SEC-Lab/Awesome-PPML-Papers 【北大、螞蟻三個維度解構隱私保護機器學習:前沿進展+發展方向】
文章的總體結構如下:
層級一:協議層級優化
盡管密碼學協議為數據隱私保護提供了嚴格的安全保證 , 但其應用于人工智能計算 , 仍面臨巨大開銷 。 本綜述指出當前協議設計主要存在以下核心痛點:1)基于不經意傳輸(OT)的協議有極高的通信開銷和基于同態加密(HE)的協議面臨嚴重計算瓶頸;2)現有協議忽視模型固有的結構特性(如稀疏性、量化魯棒性) , 因此缺乏 “模型感知” 的協議設計 。
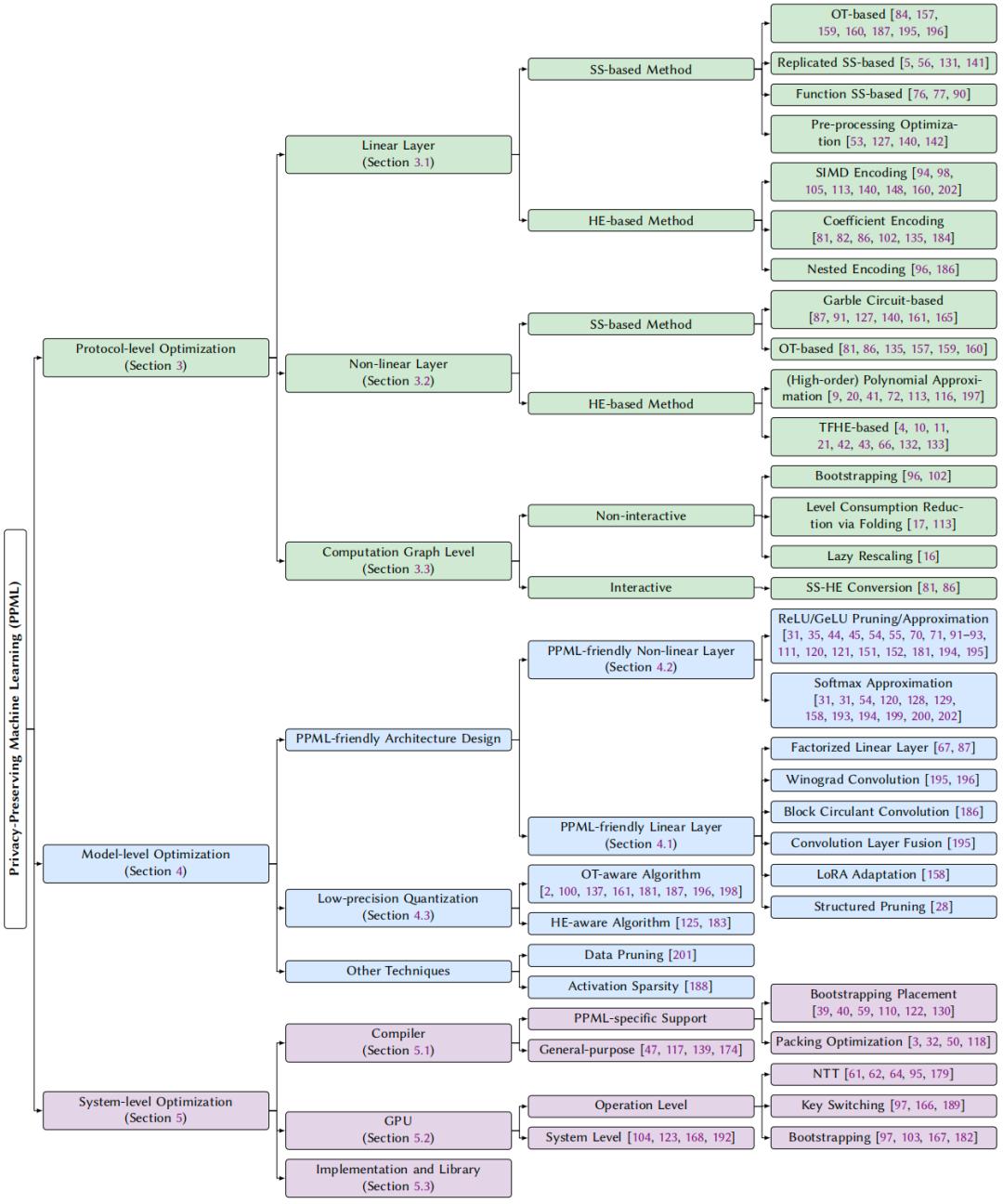
本綜述分別從人工智能模型的線性算子和非線性算子切入 , 主要討論了基于 OT 和 HE 的協議設計和發展脈絡 。 綜述中重點回答了在不同場景中 , 應該使用何種協議以及 HE 編碼方式 。 綜述還分析了在交互式和非交互式協議框架下的圖級協議 , 比如秘密分享和 HE 之間的轉換、全同態中的自舉方案 。 以下是關于編碼方案的總結:
層級二:模型層級優化
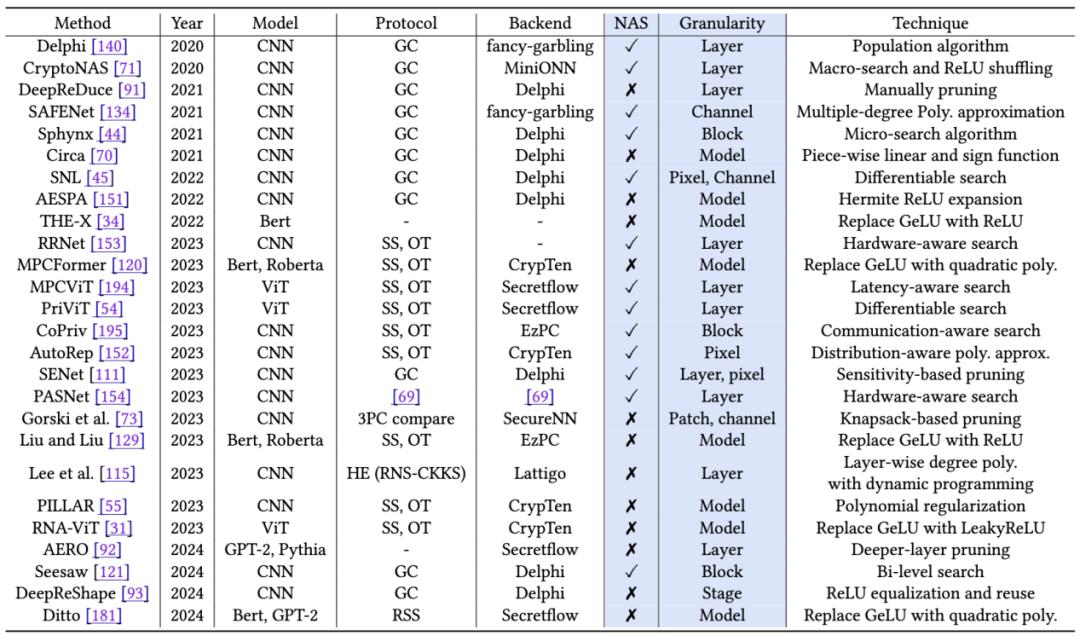
本綜述強調在傳統明文機器學習模型中的設計(如 ReLU 剪枝、模型量化)在 PPML 中往往會導致高昂代價 。 綜述系統地歸納了當前 PPML 領域的四類模型層優化策略:1)線性層優化:比如高效卷積設計、低秩分解、線性層融合;2)非線性層 ReLU 和 GeLU 優化:比如多項式近似、剪枝和 GeLU 的替換;3)非線性層 Softmax 優化:比如昂貴算子的替換、KV cache 剪枝、注意力頭融合;4)低精度量化 , 包括 OT 和 HE 友好的量化算法 。 下表概括了線性層和非線性層的優化方案:
層級三:系統層級優化
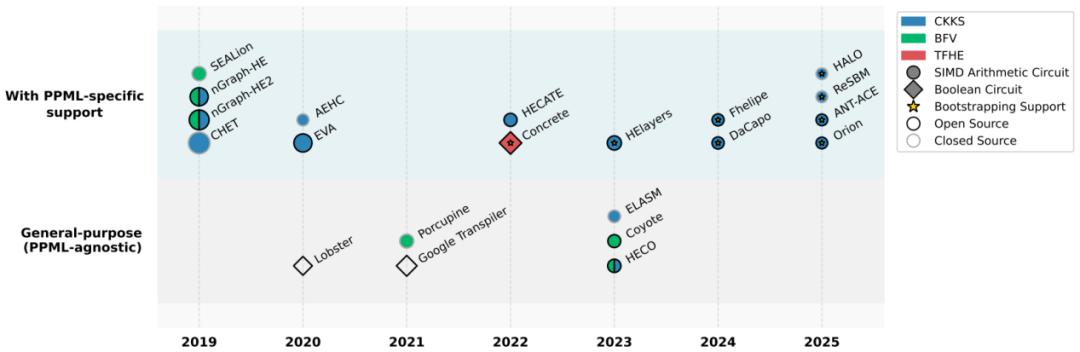
本綜述指出 , 即便協議和模型層級已經得到優化 , 系統層級若無法 “感知協議特性” , 將難以釋放真正性能 。 綜述中梳理了兩個方向的優化路徑:1)編譯器設計:從協議特性感知、靈活編碼、Bootstrapping 支持等方面展開了討論;2)GPU 設計:分別討論了操作層面加速與 PPML 系統層面的優化 , 通過對比現有 GPU 加速實現中典型 PPML 工作負載的執行時間 , 對相關技術進行了總結 。 下圖是 HE 編譯器的梳理:
下表對比了 GPU 加速的 HE 框架:
總結與討論
本綜述強調 , 僅僅在某一層級優化已難以滿足大模型時代對隱私與效率的雙重要求 。 綜述提出必須從 “跨層級協同優化” 的角度重新設計 PPML 的方案 , 未來的研究方向包括:1)協議 - 模型 - 系統協同優化和設計;2)構建面向大模型隱私推理的隱私計算方案;3)面向邊緣設備部署的輕量化隱私計算方案 。
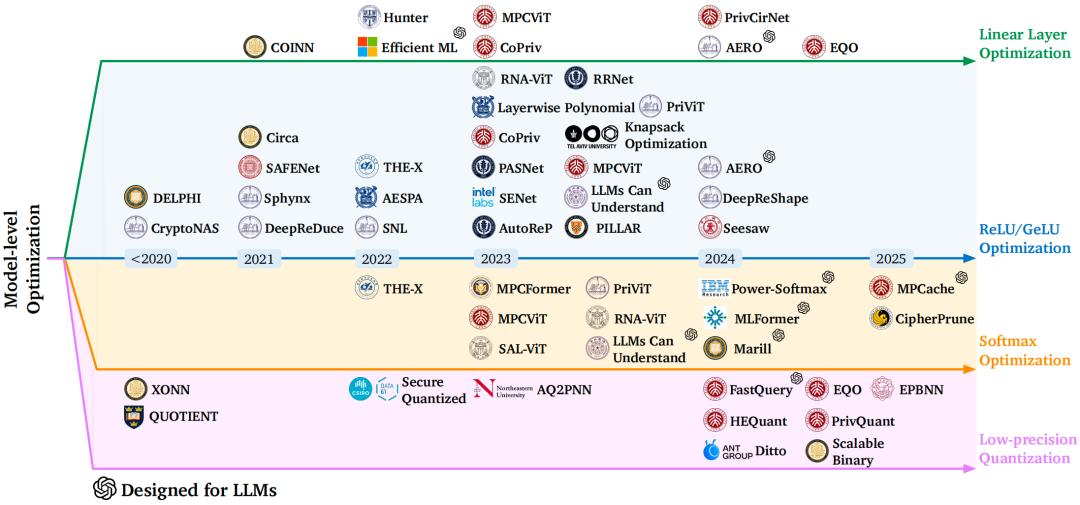
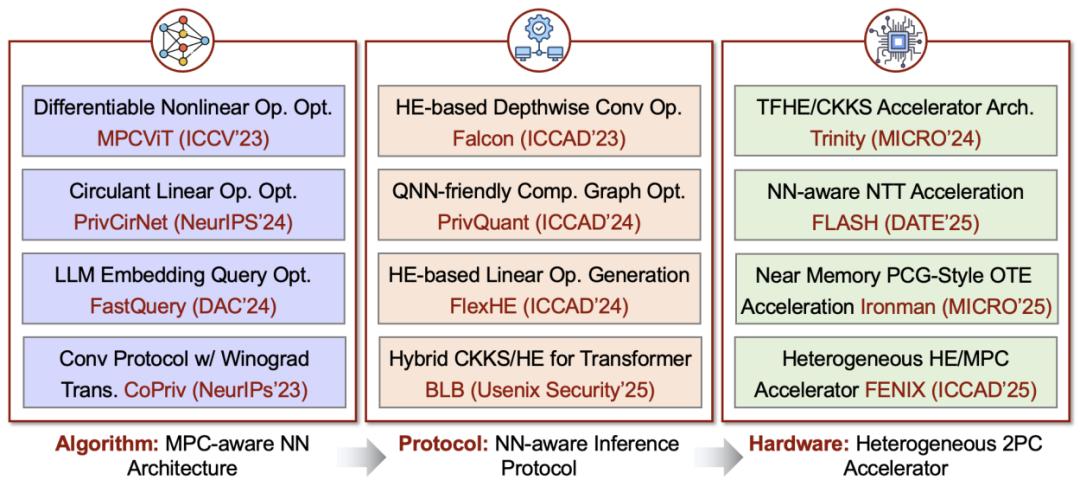
值得一提的是 , 李萌老師課題組近年來圍繞上述三個層面 , 也開展了一系列相關研究工作 , 歡迎各位相關領域老師、同學多多交流 。 下圖總結了課題組已經發表的相關工作:
本綜述詳細討論了跨層級優化帶來的挑戰與機遇 , 分別闡述了模型和協議的系統優化、協議和系統的系統優化 。 例如模型量化難以直接給 PPML 帶來期望的收益 , 非線性層優化難以帶來系統級的效率提升 , 現代 GPU 加速了明文機器學習 , 但其有限的精度支持給 HE 所需的高精度模塊化算術帶來了挑戰 。
綜述還進一步從線性層和非線性層角度討論了大模型對 PPML 的獨特挑戰 , 并提出除了無需訓練的優化方式 , 還可以考慮用參數高效微調(比如 LoRA)等技術去構建 PPML 友好的大模型結構 。
推薦閱讀













- 449元 小米智能室外攝像機4 Pro三攝變焦版開售:3K畫質、9倍變焦
- 兩大AI視頻獨角獸競逐新融資,投前估值360億、230億
- 騰訊校園招新緊盯AI人才 軟件開發、技術研究需求量較大
- 英偉達回應了,沒有后門、沒有終止開關、沒有監控軟件
- AMD AM6插槽針腳數量增加22%!尺寸不變、兼容AM5散熱器
- UFCS融合快充車載充電器加速全面普及 支持華為、OPPO等手機快充
- 剛剛,OpenAI發布2款開源模型!手機筆記本也能跑,北大校友扛大旗
- 樂天移動攜手思科、諾基亞和F5共建5G SA網絡,引領日本移動通信新變革
- AMD下代GPU性能曝光:IPC提升5-10%、可媲美RTX 6090
- 國產手機芯片、AI芯片、CPU、發動機:缺什么,我們就造什么!