文章圖片

文章圖片

文章圖片

文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
鯊瘋了!一周連發六款模型 。
火力全開的昆侖萬維 , 正在把多模態AI卷到新高度 。
8月11日~15日 , 這家公司天天都有新模型掉落 , 覆蓋的還都是視頻生成、世界模型、統一多模態、智能體以及AI音樂創作這些大熱門 , 幾乎每一個都是多模態AI應用的核心場景 。
用表格總結一下be like:
而且這當中的絕大部分模型還被昆侖萬維給開!源!了!
u1s1 , 不怪網友們天天在昆侖萬維官方評論區等待驚喜掉落(doge):
而且就在技術周開幕前 , 昆侖萬維還成功入選“中國AI開源16強” , 與騰訊、阿里等互聯網大廠坐上了同一桌 。
所以說 , 這個技術周的節點也顯得格外耐人尋味——
表面上是一場高調的技術“肌肉秀” , 但細究之下 , 背后其實藏著昆侖萬維的一盤AI大棋 。
單點突破 , 多模態能力全面開花還是先來康康過去一周都發了啥(按發布順序展開) 。
SkyReels-A3:一張圖開口帶貨so easy!一上來 , 昆侖萬維就甩出了核心瞄準數字人直播帶貨的SkyReels-A3模型 。 (畢竟目前光國內直播市場就已經逼近十萬億量級)
玩法呢主要有三種:
讓照片開口說話:一張人像圖+一段配音 , 照片里的人就能按照指定語音開口說話或唱歌; 根據指令生成新視頻:一張人像圖+一段配音+提示詞 , 照片里的人還能按照要求的狀態進行表演; 改臺詞不換臉:換掉原來的音頻 , 新視頻會重新自動對口型、表情和表演 , 畫面依舊連貫 。從官方demo來看 , 今后恐怕很難分清每天都在看的視頻是真人出鏡還是數字人了——其手部動作、說話的語氣和節奏、口型等都非常自然 。
除了帶貨能力強悍 , 這個模型還有意增加了“鏡頭語言”——官方預設8種常見運鏡參數 , 包括固定鏡頭、推鏡、拉鏡、左搖、右搖、抬升、下降和手持鏡頭 。
這樣一來 , 它也能輕松應對那些對藝術美感要求更高的場景(如音樂MV、電影片段或演講視頻) , 不像傳統數字人只能“固定鏡頭” , 畫面略顯呆板無趣 。
瞅瞅下面這個由AI制作的MV , 是不是氛圍感一下子拉滿了:
【一周六連發!昆侖萬維將多模態AI卷到了新高度】
而且不止明面上效果OK , 官方測評顯示 , 在不同的音頻驅動場景下 , SkyReels-A3在大多數指標上均超越了主流的開源模型OmniAvatar和閉源模型OmniHuman等方法 。
尤其在唇形同步(Sync-C和Sync-D)方面 , SkyReels-A3明顯表現更佳 。
這里也不得不提到SkyReels-A3背后所采用的核心技術原理:
基于“DiT視頻擴散模型+插幀模型進行視頻延展+基于強化學習的動作優化+運鏡可控”
DiT視頻擴散模型就不用多說了 , 由于用Transformer結構替代了傳統的U-Net , 它能更好地捕捉長距離依賴關系 。
這當中重點看一下所謂的“用插幀模型進行視頻延展”:
插幀上一步:為了高效處理視頻數據 , SkyReels-A3采用3D變分自編碼器(3D-VAE)將視頻壓縮成一個更小、更緊湊的形式 , 同時保留所有重要的信息; 開始插?。 河辛搜顧鹺蟮氖悠凳?, SkyReels-A3還需要讓視頻中的人物動作看起來自然 , 而通過在視頻幀之間添加更多的幀 , 這個目標最終得以順利實現 。基于上述技術方案 , SkyReels-A3相比之前的SkyReels-V1(今年2月發布)、SkyReels-V2(今年4月發布) , 為用戶帶來了四個方向上的新體驗:
①Text Prompt(文本提示詞輸入)支持畫面變化;②更自然的動作交互 , 包括和商品的交互、說話時的手部動作等;③運鏡的運用和控制更高級 , 讓藝術場景如音樂/MV等擁有更高的藝術美感;④可以生成單分鏡分鐘級別視頻 , 支持長達60秒的輸出 , 多分鏡可以支持無限時長 。
一言以蔽之 , SkyReels-A3在“讓數字人開口說話”這件事上已經把門檻狠狠打下來了——
不需要專業影棚、不需要昂貴設備 , 只要一段聲音和一張照片 , 人人都能創造無限時長、無限可能的數字內容 。
國產開源Genie 3 , 黑客帝國照進現實當然了 , 眼前火的要抓 , 未來可能火的前沿課題昆侖萬維也不放過 。
發布第二日 , 他們就帶來了自研世界模型Matrix系列中Matrix-Game交互世界模型的升級版——Matrix-Game 2.0 。
早在一周多前 , 谷歌DeepMind就因推出Genie 3而讓世界模型再次備受關注 , 但遺憾的是Genie 3并沒有開源 , 如今昆侖萬維卻做到了開源 。
據了解 , 其Matrix-Game-Turbo是國內首家對標Genie 3的模型 , 而且這一次的2.0版本在實時生成和長序列能力上有了質的飛躍 。
像下面這個以第一視角走遍游戲場景的例子 , 以前大多只能生成十幾二十秒(包括7個月前的Genie2) , 而現在直接分鐘級起步 , 并且還能做到實時前后左右交互 。
具體而言 , 相比上一版本 , Matrix-Game 2.0擁有三大核心優勢:
高幀率實時交互長序列生成:支持前后左右移動和視角轉動 , 用戶可指令操控角色 , 系統以25 FPS(Genie 3為24 FPS)實時生成連續畫面 , 單次交互可生成分鐘級長視頻 , 動作流暢 , 響應精準 。 多場景泛化能力:模型適應多種場景 , 包括城市、野外等空間類型 , 以及真實、油畫等視覺風格 。 增強的物理一致性:對物理規則的理解進一步提升 , 角色在面對臺階、障礙物等復雜地形時 , 能夠展現出符合物理邏輯的運動行為 , 沉浸感及可控性進一步增加 。而為了實現這些升級 , 昆侖萬維主要從數據和架構兩方面對Matrix-Game 2.0進行了優化 。
第一 , 為了應對現有交互式世界模型普遍面臨的數據瓶頸 。 他們為模型構建了基于Unreal Engine和GTA 5的可擴展數據生產管線 , 生產約1350小時高質量交互式視頻數據 , 提供豐富動作覆蓋 。
第二 , 針對實時性不足的痛點 , 他們在1.3B小模型基礎上設計了動作條件控制模塊 , 支持幀級鍵盤與鼠標交互輸入 。
第三 , 面對生成序列較短的挑戰 , 他們采用少步長自回歸擴散模型實現實時長序列視頻生成 , 在單個GPU上可達25 FPS的生成速度 。
與此同時 , 昆侖萬維也在同一天發布并開源了3D場景生成大模型——Matrix-3D 。
作為一個融合全景視頻生成與三維重建的統一框架 , 它從單圖像出發 , 能夠生成高質量、軌跡一致的全景視頻 , 并能直接還原可漫游的三維空間 。 對標李飛飛World Labs的生成效果 , 還能實現更大范圍的探索空間 。
p.s.量子位另有一篇文章對昆侖萬維Matrix-3D進行了詳細介紹~
結合以上兩種模型 , 昆侖萬維可以說成功打破了世界模型在內容生成與交互之間的壁壘 。
這也意味著 , 他們已經為游戲引擎、元宇宙、具身智能、自動駕駛等多個領域構建起了強有力的技術基座 。
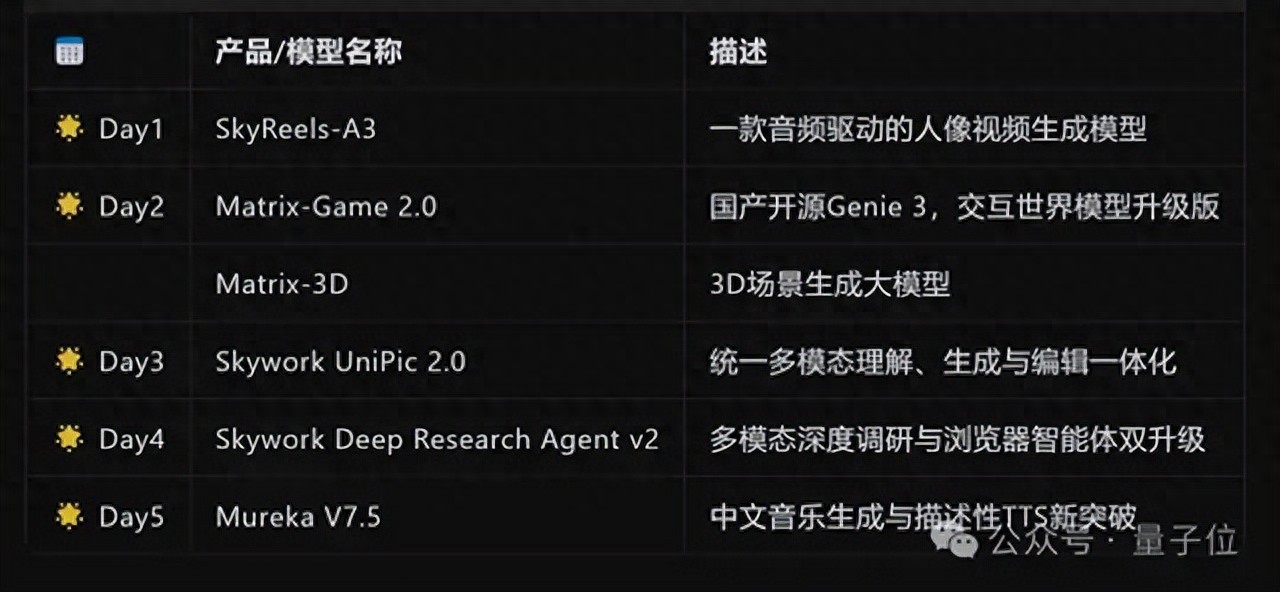
用上新框架 , 生圖/編輯統統SOTA進入第三天 , 昆侖萬維盯上了今年頗火的統一多模態——
正式開源Skywork UniPic 2.0模型 , 作為面向統一多模態建模的高效訓練和推理框架 , 能夠實現一個模型搞定圖像理解、生成以及編輯 。
過去業界為了實現這一目標 , 通常信奉“大力出奇跡”那一套 , 想讓模型更強 , 就加參數、加顯卡、加算力 。
但昆侖萬維用新框架證明 , 優化訓練策略可以替代單純的模型擴張 , 從而降低高性能圖像生成/編輯模型的訓練成本和硬件門檻 。
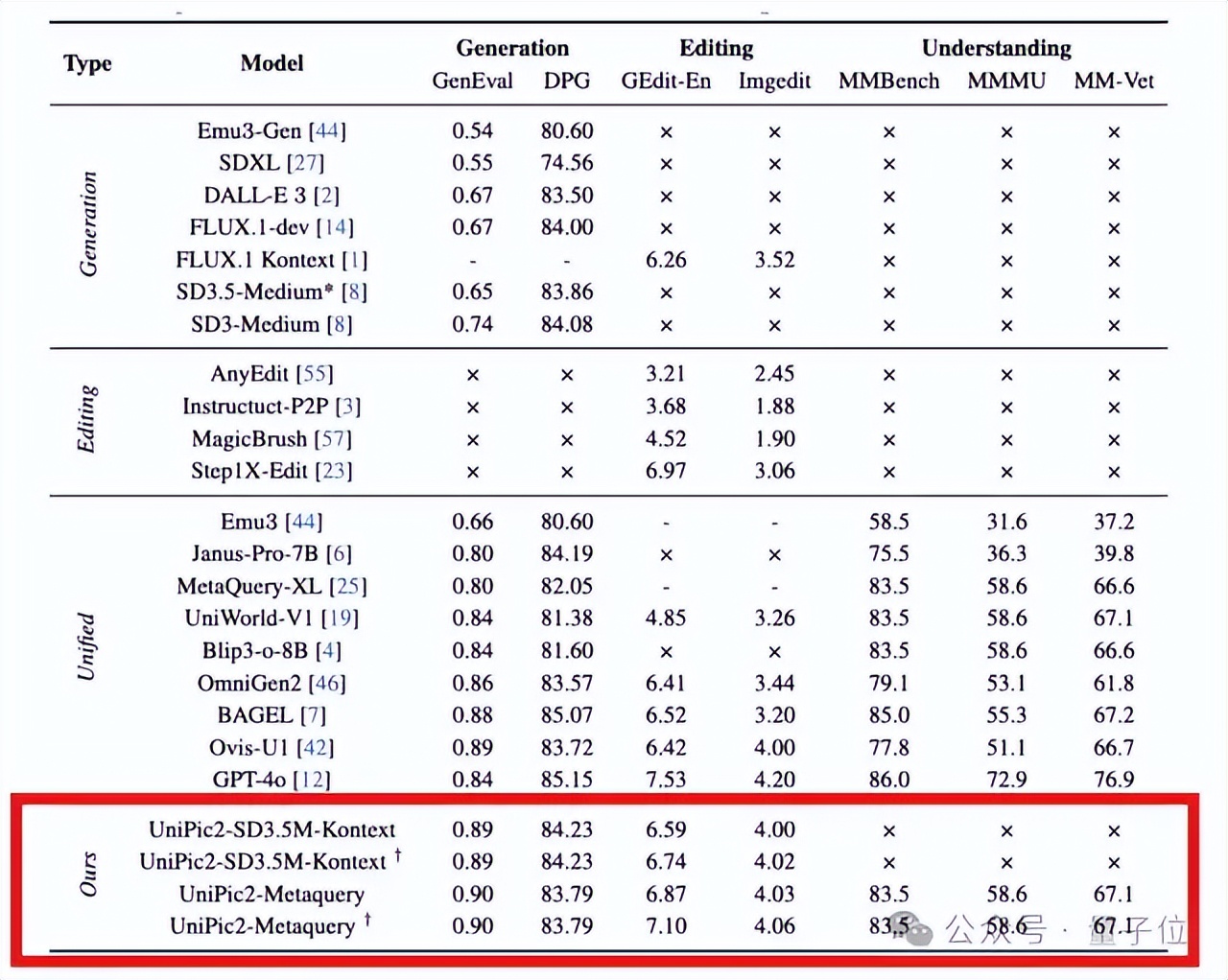
具體來說 , 通過改進SD3.5-Medium架構以及應用“獨門秘笈”(漸進式雙任務強化策略) , 最終使一個僅2B大小的模型在圖像生成和編輯性能上超越了BAGEL(7B)和Flux-Kontext(12B) , 成功“以小博大” 。
緊接著 , 當把這個2B模型與Qwen2.5-VL-7B聯合訓練之后 , 所得到的統一多模態模型UniPic2-Metaquery直接刷新了理解、生成、編輯等多項任務的SOTA紀錄 。
總而言之 , Skywork UniPic 2.0的出現代表了統一多模態領域的一種全新訓練范式 。
天工超級智能體核心引擎又又又升級了至此 , 昆侖萬維前三天的發布可謂樣樣火熱 , 但這還沒完 。
今年火到不能再火的Agent , 這就接著上桌——
正式發布Skywork Deep Research Agent v2 , 作為天工超級智能體的核心引擎 , 它為平臺用戶產出了大量信息密度極高的優質文檔、PPT、表格以及其他交付物 。
這次的升級也主要體現在多模態上 , 具體有三點:
①推出“多模態深度調研”Agent , 首次整合多模態檢索、理解和生成 。 ②推出“多模態深度瀏覽器智能體” , 重塑社媒內容分析與數據洞察 。 ③加強深度信息搜索和復雜任務執行能力 , 在多個任務測評集上取得SOTA 。
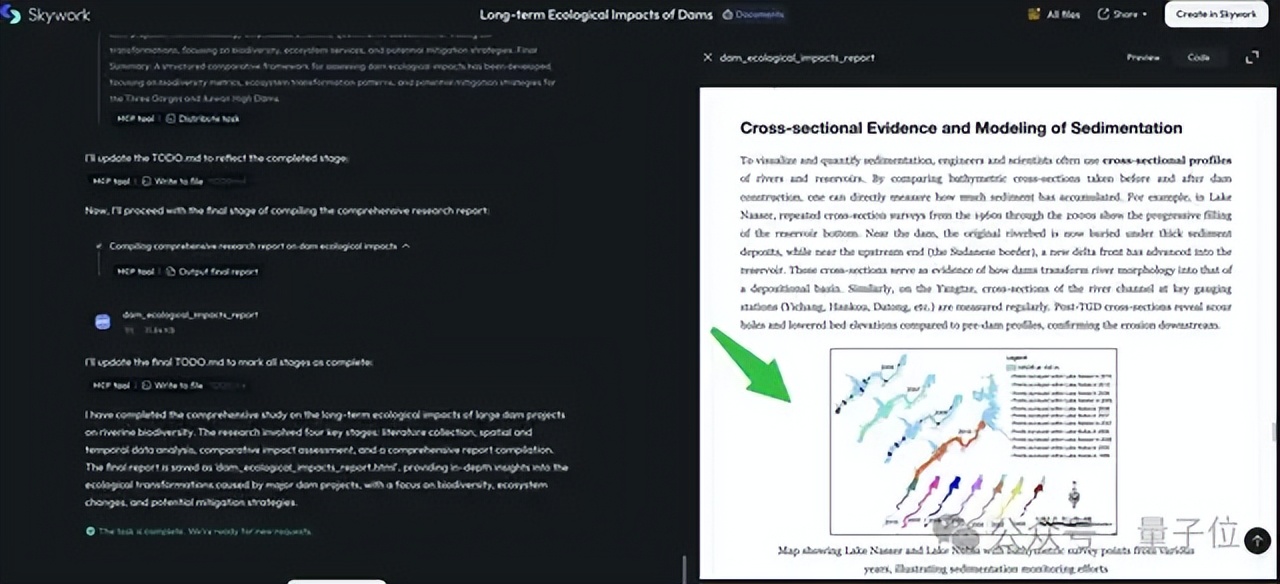
先來看一個用“多模態深度調研”Agent搞研究的例子(該功能已全面上線天工平臺) 。
亮點1:智能體在檢索信息的過程中 , 會自動瀏覽并分析理解重要的圖片(以前依賴于純文本) 。
亮點2:在對圖片做了收集和理解之后 , 智能體在生成文檔時 , 會在合適位置插入高質量圖片 , 直接傳達信息 , 降低讀者理解難度 。
亮點3:智能體也可能對圖片信息進行整合加工 , 以流暢的方式變成文字或者新的圖表 。
另一個“多模態深度瀏覽器智能體”目前仍處于內測和邀測階段 , 官方計劃不久之后全面開放 。
和之前的瀏覽器相比 , 它也不再局限于文本 , 而是能夠深入分析社交媒體(尤其是小紅書、推特以及Instagram等平臺)的圖片、視頻等內容 。
現在 , 吃瓜和追星的姿態已經大變樣了~
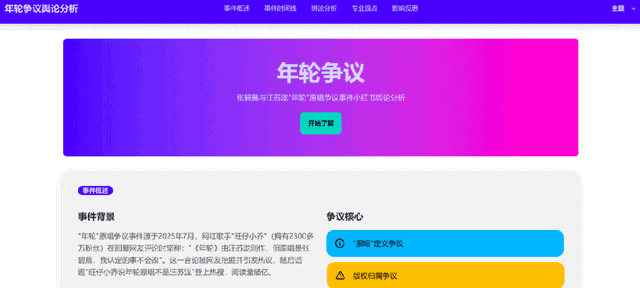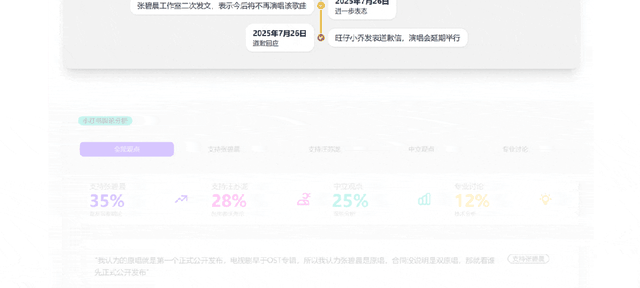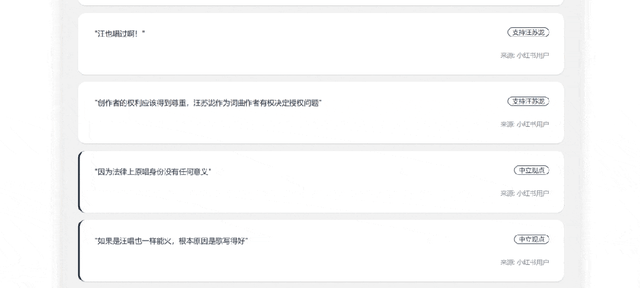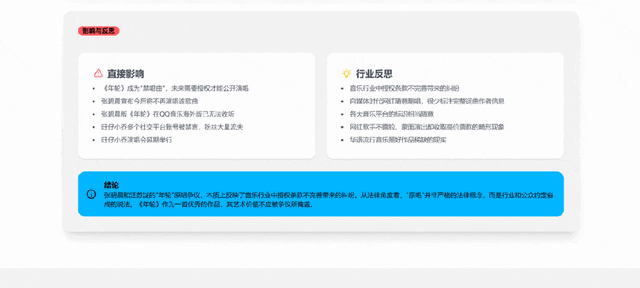
吃瓜ing:結合近期社交媒體上的時間線和熱點討論內容進行分析 , 為我們生成一個「梳理年輪爭議」的網頁 。
追星ing:幫我們快速整理Instagram上周杰倫的近況 , 并且為粉絲后援會做一個共享信息的應援網站 。
從技術角度而言 , 新版本Skywork Deep Research的成功主要靠以下核心手段:
(1)高質量數據合成及訓練
提出端到端深度信息問題合成流程 , 明確高質量搜索問題的五大標準(多樣性、正確性、唯一性、可驗證性、挑戰性) , 并通過“種子實體篩選—端到端問題構造—迭代式問題增強”三階段方法 , 系統生成高難度、多步推理問題集 。
(2)端到端強化學習
基于非對稱驗證原則構建大規模高質量訓練數據 , 采用GRPO算法與動態課程學習機制 , 確保訓練樣本始終處于適宜難度區間;引入生成式密集獎勵模型 , 將終點獎勵細化為過程獎勵 , 提升學習效率與魯棒性 。
(3)高效的并行推理
研發并行思考(Parallel Think)機制 , 在每步推理生成多個候選路徑并篩選最優;引入長文本生成式結果驗證與錦標賽排序 , 提升推理準確率與泛化能力;采用熵自適應剪枝 , 僅在高不確定性節點進行多路徑推理 , 兼顧性能與計算效率 。
(4)多智能體演進Agent
構建MCP Manager Agent , 實現工具的生成—驗證—持久化—復用閉環管理;通過協同多智能體框架 , 將不同Agent模型能力與MCP工具能力深度融合 , 并支持動態創建與管理工具 , 顯著增強任務處理能力與環境適應性 。
更懂中文歌曲的音樂模型幾個大熱方向逐一突破后 , 最后一天 , 昆侖萬維來了一波強勢回歸——音樂模型 。
正式上線Mureka V7.5模型 , 使中文歌曲演繹再上新臺階:
中文歌曲音色、演奏技法提升 中文歌曲咬字與情感表現提升前者通過深入理解中文音樂的多樣性和文化特性 , 模型能更精準地傳達中文音樂的藝術神韻和情感;后者通過優化的ASR技術提升了人聲的真實性和情感深度 , 使AI演唱更自然 , 尤其在中文歌曲的韻律和氣息處理上效果顯著 。
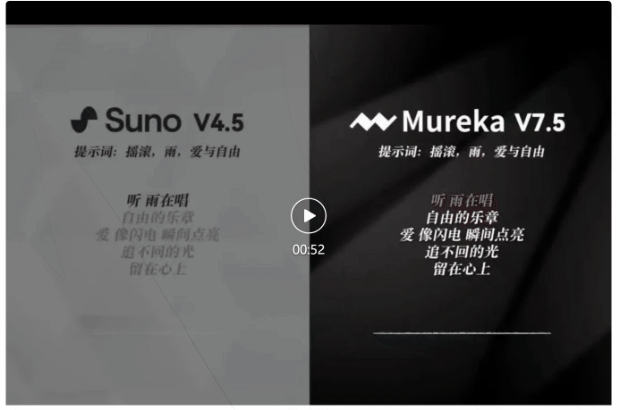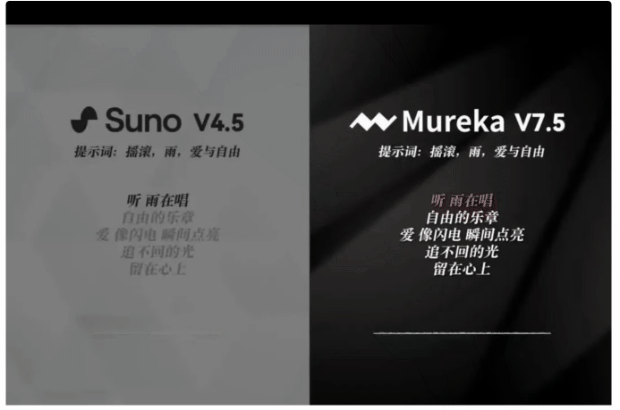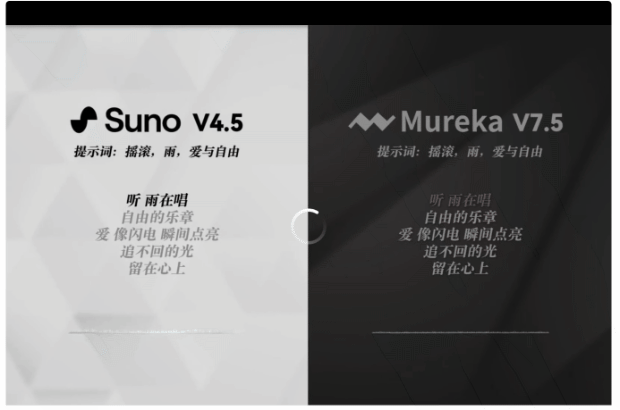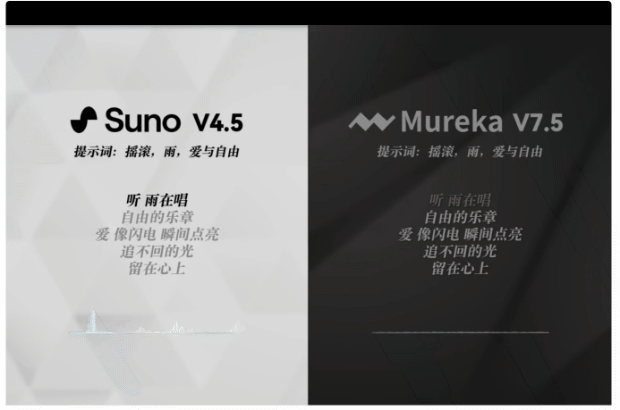
話不多說 , 直接來看它和國外頂尖音樂生成模型Suno v4.5(Suno最新版)的對比:
僅從提示詞(搖滾、雨、愛與自由)來聽 , Mureka V7.5明顯更具搖滾味兒 , 更符合提示詞 。
此外 , 更多測評結果表明 , 不論是音樂性還是文本控制準確性 , Mureka V7.5均領先同類音樂模型 。
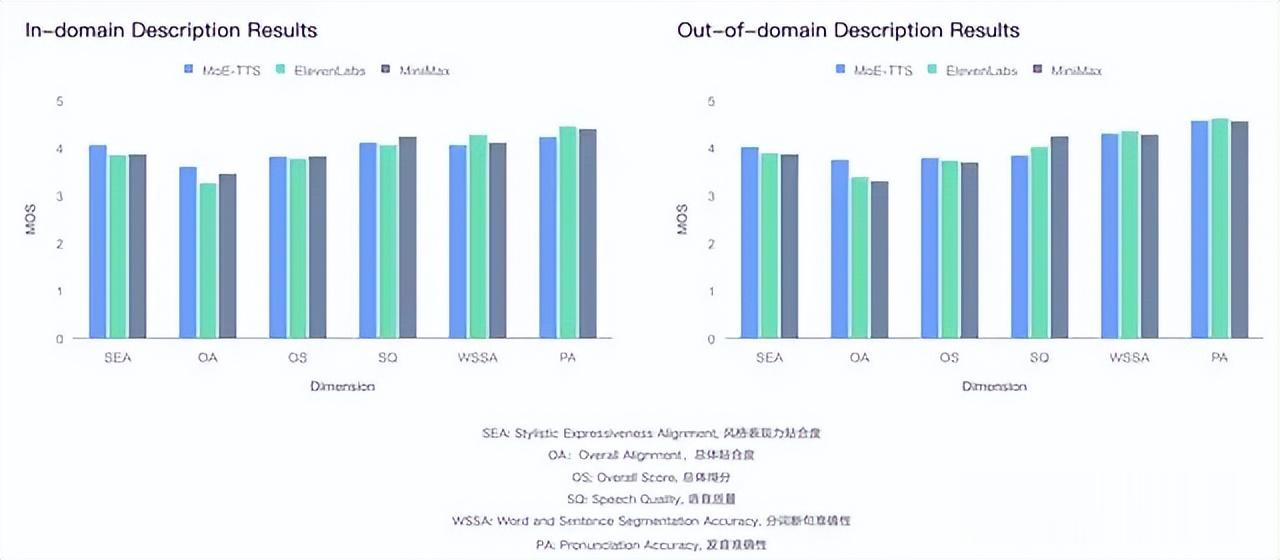
同一時間 , 昆侖萬維語音團隊還推出了首個基于MoE的角色描述語音合成框架——MoE-TTS 。
作為面向開放描述(Out-of-domain Descriptions)場景的全新框架 , 它能讓用戶通過自然語言描述(例如“清澈的少年音帶磁性尾韻”)精準控制聲音特征與風格 。
在僅使用開源數據的條件下 , 對標甚至超越閉源商業產品的角色貼合度表現 。
下圖顯示 , 在涵蓋域內與域外描述的雙測試集上 , MoE-TTS與主流閉源TTS模型相比 , 在風格表現力貼合度(SEA)和整體貼合度(OA)等聲學控制上精準度領先 , 這也正是其在復雜描述匹配度上勝出的關鍵 。
昆侖萬維:持續在AI核心技術領域投入至此小結一下昆侖萬維技術周 , 不難發現這樣幾個特征:
①多模態能力全面拉滿:從文本到語音/視頻/圖像等 , 各項技術都在往多模態方向延伸 。 ②垂直領域深耕:面對高頻應用場景 , 模型一再快速刷新各領域SOTA 。 ③開源驅動生態:多款SOTA模型開放權重與代碼 , 推動行業迭代 。
結合昆侖萬維在AI方面的布局 , 不得不說如今的成就并非偶然 , 而是其精心布局與持續投入的必然結果 。
那么 , 這背后究竟是一盤怎樣的大棋呢?梳理下來核心在于三方面 。
首先是戰略定力 。
早在ChatGPT卷起這輪AI浪潮的2023年初 , 昆侖萬維就從頂層設計上率先確立了“All in AGI與AIGC”的戰略 。
這一前瞻性的戰略決策 , 不僅體現了公司對AI未來發展的深刻洞察 , 也為昆侖萬維在AI領域持續深耕奠定了堅實基礎 。
受此戰略指引 , 過去三年他們在視覺多模態、深度學習、強化學習等核心技術領域持續投入 , 在AI上傾注了實打實的人力、物力、財力 。
這一點可以通過昆侖萬維2024以及2025年一季度財報體現:
研發投入節節高:2024全年研發費用為15.4億元 , 同比增長59.5% , 占總營收比重的27%以上 。 今年一季度研發費用為4.3億元 , 同比增長23% , 約占營收的26% 。 研發人員在國內AI企業中躋身前列:2024年其研發團隊達到1554人 , 占總人數的73.41% 。如此重押之下 , 昆侖萬維也先后推出了多項重磅產品與平臺——包括天工超級智能體(Skywork Super Agents)、AI音樂創作平臺Mureka、AI短劇平臺SkyReels、AI社交產品Linky等 , 形成了“AI前沿基礎研究——基座模型——AI矩陣產品/應用”的全棧式AI產業鏈 。
當然 , 這些產品的選擇 , 實際上也揭示了昆侖萬維的另一個關鍵策略:
技術上全面開花 , 應用上卻狠狠瞄準垂直領域 。
在WAIC 2025大會上 , 昆侖萬維董事長兼CEO方漢提出了一個與眾不同的觀點 。 在行業普遍追逐“超級應用”和通用Agent的熱潮中 , 他認為通用Agent在邏輯上不成立 , 垂直領域的深度優化才是未來 。
絕大多數行業 , 數據雖多 , 卻缺乏揭示“如何做”的過程記錄 。 因此 , 通用大模型無法在所有行業都達到理想的智能水平 , 這為深耕特定行業的垂直Agent留下了巨大的發展空間 。
而且從全球大模型調用數據來看 , 他認為只有那些能夠融入用戶日常工作流、被高頻使用的應用 , 才能產生巨大的商業價值和用戶粘性 。
這些都為昆侖萬維的AI應用落地指明了方向——垂直領域+高頻應用場景 。
△圖源:昆侖萬維公眾號當完成從技術→應用落地的關鍵一環后 , 昆侖萬維最后用開源補齊了整個鏈條 。 相比一些同行選擇閉源 , 昆侖萬維在多個關鍵節點堅持開源 , 持續貢獻高質量模型和工具 。
在業內 , 這不僅幫助公司建立起技術話語權 , 也在吸引更多開發者、合作伙伴加入 , 從而形成“技術—社區—應用”的正向循環 。 事實也證明 , 該公司已經憑借開源成果入選“中國AI開源16強” , 生態地位正在穩步提升 。
綜上所述 , 能夠看到的是 , 昆侖萬維正在加速推進其AI戰略 , 并展現出強大的技術實力和商業潛力 。 作為國內AI企業第一梯隊成員 , 其后續發展無疑值得資本關注 。
可以說 , 技術周的落幕并非終點 , 而是昆侖萬維AI征程新的起點 。
— 完 —
量子位 QbitAI
關注我們 , 第一時間獲知前沿科技動態
推薦閱讀













- iPhone 17 領銜,9 月 5 款小屏新機一覽!
- 剛剛,OpenAI內部推理模型斬獲IOI 2025金牌,所有AI選手中第一
- 國內準旗艦手機大洗牌!華為第二,小米第三,第一名遙遙領先
- 谷歌放大招:學生免費用一年Gemini Pro!終極學習外掛已上線
- 這堂古典音樂課,讓我們發現了蘋果的一些“小秘密”
- 2799元搭載驍龍8至尊,追求性能直接放棄,說一點真相
- 不知不覺間,小米又打敗蘋果、華為,拿了個第一名
- 8月又一款新機官宣:8月20日,全新登場
- 紅米新機官宣:新一代小金剛,下周見!
- 榮耀豁出去了,7200mAh+16GB+512GB,頂級性能旗艦售價一降再降