
文章圖片
文章圖片

文章圖片

文章圖片

文章圖片
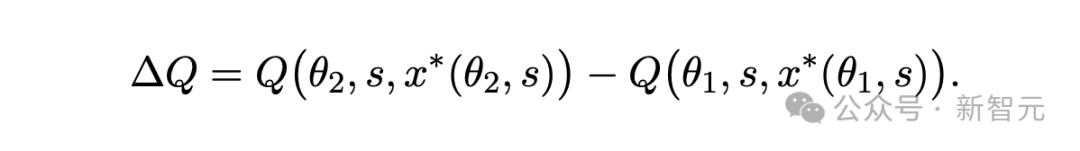
文章圖片
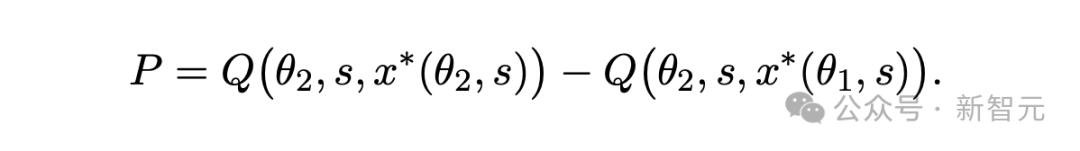
文章圖片
文章圖片
文章圖片
文章圖片

文章圖片

文章圖片

編輯:桃子
【新智元導讀】提示詞才是AI隱藏的王牌!馬里蘭MIT等頂尖機構研究證明 , 一半提示詞 , 是讓AI性能飆升49%的關鍵 。
AI性能的提升 , 一半靠模型 , 一半靠提示詞 。
最近 , 來自馬里蘭大學、MIT、斯坦福等機構聯手驗證 , 模型升級帶來的性能提升僅占50% , 而另外一半的提升 , 在于用戶提示詞的優化 。
他們將其稱之為「提示詞適應」(prompt adaptation) 。
論文地址:https://arxiv.org/pdf/2407.14333v5
為此 , 他們讓DALL-E 2和DALL-E 3來了一場PK , 1893名「選手」在10次嘗試中 , 用隨機分配三種模型之一復現目標圖像 。
令人驚訝的是 , DALL-E 3圖像相似度顯著優于DALL-E 2 。
其中 , 模型升級本身僅貢獻了51%的性能 , 剩余的49%全靠受試者優化的提示詞 。
關鍵是 , 那些沒有技術背景的人 , 也能通過提示詞 , 讓DALL-E 3模型生成更好的圖片 。
OpenAI總裁Greg Brockman也同樣認為 , 「要充分發揮模型的潛力 , 確實需要一些特殊的技巧」 。
他建議開發者們去做「Prompt庫」管理 , 不斷探索模型的邊界 。
換言之 , 你的提示詞水平 , 決定了AI能不能從「青銅」變成「王者」 。
別等GPT-6了!
不如「調教」提示詞
GenAI的有效性不僅取決于技術本身 , 更取決于能否設計出高質量的輸入指令 。
2023年 , ChatGPT爆紅之后 , 全世界曾掀起一股「提示詞工程」的熱潮 。
盡管全新的「上下文工程」成為今年的熱點 , 但「提示詞工程」至今依舊炙手可熱 。
然而共識之下 , 提示詞設計作為一種動態實踐仍缺乏深入研究 。
多數提示詞庫和教程 , 將有效提示視為「可復用成品」 , 但卻用到新模板中可能會失效 。
這就帶來了一些現實的問題:提示策略能否跨模型版本遷移?還是必須持續調整以適應模型行為變化?
為此 , 研究團隊提出了「提示詞適應」這一可測量的行為機制 , 用以解釋用戶輸入如何隨技術進步而演進 。
他們將其概念化為一種「動態互補能力」 , 并認為這種能力對充分釋放大模型的經濟價值至關重要 。
為評估提示詞適應對模型性能的影響 , 團隊采用了Prolific平臺一項預注冊在線實驗數據 , 共邀請了1893名參與者 。
每位受試者被隨機分配三種不同性能的模型:DALL-E 2、DALL-E 3 , 或自動提示優化的DALL-E 3 。
除模型分配外 , 每位參與者還獨立分配到15張目標圖像中的一張 。 這些圖像選自商業營銷、平面設計和建筑攝影三大類別 。
實驗明確告知參與者模型無記憶功能——每個新提示詞均獨立處理 , 不繼承先前嘗試的信息 。
每人需要提交至少10條提示詞 , 需通過模型盡可能復現目標圖像 , 最優表現者將獲得高額獎金 。
任務結束后參與者需填寫涵蓋年齡、性別、教育程度、職業及創意寫作/編程/生成式AI自評能力的人口統計調查 。
隨機分配 , 10次生成
實驗的核心結果指標 , 是參與者生成的每張圖像與指定目標圖像之間的相似度 。
這項指標通過CLIP嵌入向量的余弦相似度進行量化 。
由于生成模型的輸出具有隨機性 , 同一提示詞在不同嘗試中可能產生不同的圖像 。
為控制這種變異性 , 研究人員為每個提示詞生成10張圖像 , 并分別計算它們與目標圖像的余弦相似度 , 隨后取這10個相似度得分的平均值作為該提示詞的預期質量分數 。
回放分析:是模型 , 還是提示詞?
實驗的另一個核心目標在于 , 厘清圖像復現性能的提升中 , 有多少源于更強大的模型 , 又有多少來自提示詞的優化?
根據概念框架的表述 , 當模型從能力水平θ1升級至更高水平θ2時 , 其輸出質量的總改進可表示為:
研究人員將這一變化分解為兩部分:
1. 模型效應:將相同提示詞應用于更優模型時 , 獲得的性能提升;
2. 提示詞效應:通過調整提示詞以充分發揮更強大模型優勢所帶來的額外改進 。
為實證評估這兩個組成部分 , 研究人員對DALL-E 2和DALL-E 3(原詞版)實驗組參與者的提示詞進行了額外分析 。
具體方法是將實驗過程中參與者提交的原始提示詞 , 重新提交至其原分配模型和另一模型 , 并分別生成新圖像 。
· 分離模型效應
針對DALL-E 2參與者編寫的提示詞(x*(θ1s)) , 團隊同時在DALL-E 2和DALL-E 3模型上進行評估 , 分別獲得Q[θ1sx*(θ1s)
和Q[θ2sx*(θ_1s)
的實測值 。
這一對比可分離出模型效應:即在固定提示詞情況下 , 僅通過升級模型獲得的輸出質量提升 。
· 比較提示效應
為了評估提示詞效應 , 作者還比較了以下兩組數據:
1. 在DALL-E 3上回放DALL-E 2提示詞的質量(即Q[θ2sx*(θ1s)
估計值)
2. DALL-E 3的參與者專門為模型編寫的提示詞在相同模型上的質量(即Q[θ2sx*(θ2s)
估計值)
這一差異恰恰能反映 , 用戶通過調整提示詞 , 模型本身得到的額外改進 。
那么 , 這項實驗的具體結果如何?
DALL-E 3強大的生圖能力
提示詞解鎖了一半
實驗中 , 研究團隊主要探討了三大問題:
(i) 接入更強大的模型(DALL-E 3)是否能提升用戶表現;
(ii) 用戶在使用更強模型時如何改寫或優化他們的提示詞;
(iii) 整體性能提升中有多少應歸因于模型改進 , 多少應歸因于提示詞的適應性調整 。
模型升級 , 是核心
首先 , 團隊驗證了使用DALL-E 3的參與者 , 是否比使用DALL-E 2的參與者表現更優?
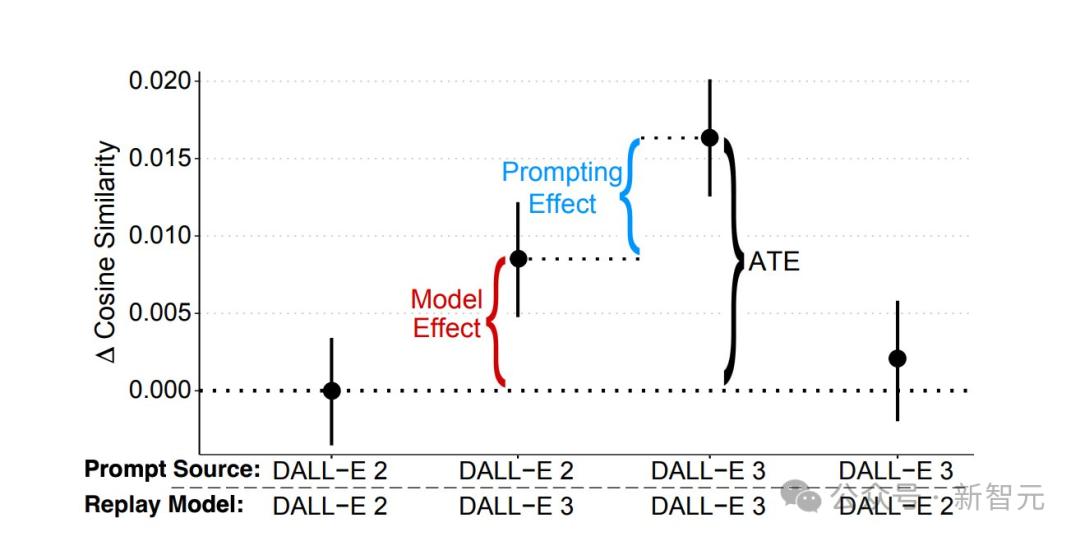
如下圖1所示 , 匯總了所有發現 。
A展示了三組代表性目標圖像 , 每組都包含了從兩種模型中抽取的三張圖像 。
中間行是 , 目標圖像余弦相似度最接近全體參與者平均值的生成結果 , 上行(下行)則呈現比均值相似度高(低)約一個平均處理效應(ATE)的圖像 。
在10次必要提示嘗試中 , 使用DALL-E 3的參與者生成圖像與目標圖像的余弦相似度平均高出0.0164 。
這個提升相當于0.19個標準差 , 如下圖1 B所示 。
而且 , 這種優勢在10次嘗試中持續存在 , 因此不可否認 , 模型升級一定會比前代有著顯著的性能提升 。
而且 , 參與者的動態提示行為在兩種模型間也存在顯著差異:
圖C表明 , DALL-E 3使用者的提示文本平均比DALL-E 2組長24% , 且該差距隨嘗試次數逐漸擴大 。
他們更傾向于復用或優化先前提示 , 這表明當發現模型能處理復雜指令后 , 他們會采取更具開發性的策略 。
此外詞性分析證實 , 增加的詞匯量提供的是實質性描述信息而非冗余內容:
名詞和形容詞(最具描述性的兩類詞性)占比在兩種模型間基本一致(DALL-E 3組48% vs DALL-E 2組49% , p = 0.215) 。
這說明了 , 提示文本的延長反映的是——語義信息的豐富化 , 而非無意義的冗長 。
模型51% , 提示詞49%
研究人員觀察到提示行為的差異表明 , 用戶會主動適應所分配模型的能力 。
DALL-E 3使用者的整體性能提升中 , 有多少源自模型技術能力的增強 , 又有多少歸因于用戶針對該能力重寫提示?
為解答這一問題 , 研究人員采用前文所述的回放(replay)分析法 , 以實證分離這兩種效應 。
模型效應
將DALL-E 2參與者編寫的原始提示 , 分別在DALL-E 2和DALL-E 3上評估性能 。
結果顯示 , 相同提示在DALL-E 3上運行時余弦相似度提升0.0084(p<10^-8) , 占兩組總性能差異的51% 。
提示效應
將DALL-E 2參與者的原始提示與DALL-E 3參與者編寫的提示(均在DALL-E 3上評估)進行對比 。
結果顯示 , 該效應貢獻了剩余48%的改進 , 對應余弦相似度提升0.0079(p=0.024) 。
總處理效應
總處理效應為0.0164 , 關鍵的是 , 當DALL-E 3用戶編寫的提示應用于DALL-E 2時 , 性能較原始DALL-E 2提示無顯著提升(Δ=0.0020;p=0.56) 。
這種不對稱性 , 印證了提示優化的效果依賴于模型執行復雜指令的能力邊界 。
圖2 B通過單一目標圖像直觀呈現這些效應:
- 上行展示DALL-E 2參與者的原始提示 , 在DALL-E 3上生成更高保真度的圖像 , 證明固定提示下模型升級的效果;
- 下行顯示DALL-E 3參與者的提示在DALL-E 2上輸出質量顯著下降 , 凸顯當模型能力不足時 , 提示優化的效果存在天花板 。
提示優化是一種動態互補策略——用戶根據模型能力提升而主動調整行為 , 且這種調整對實際性能增益的貢獻不可忽視 。
技能異質性
如下表1呈現了「回歸分析結果」 , 測試了模型效應、提示詞效應以及總效應是否會在不同技能水平的參與者之間系統性地變化 。
主要發現如下:
1. 總效應與表現十分位數的交互項呈負相關且統計顯著(?0.000115 , p = 0.0152) 。
這表明模型改進縮小了高、低績效用戶之間的整體差距 , 這與概念框架中的命題1一致 。
2. 模型效應與表現十分位數的交互項 , 同樣呈負相關且統計顯著(?0.000059 , p=0.0210) 。
這說明模型升級主要惠及低技能用戶 。 這與命題2的理論預測相符 , 因為接近性能上限的高技能用戶存在收益遞減效應 。
3. 并沒有發現提示詞適應的效益 , 在技能分布上存在顯著差異(?0.000056 , p=0.2444) 。
此外 , 研究團隊還評估了自動化提示詞的效果 。
結果發現 , GPT-4經常添加無關細節或微妙改變參與者的原意 , 導致模型輸出質量下降58% 。
用簡單的話來說 , AI寫的提示詞曲解了意圖 , 不如用戶精心編制的提示詞 。
對此 , Outbox.ai的創始人Connor Davis給出了建議 , 不要去過度自動化提示詞 , 人還應該在其中發揮主動性 。
作者介紹
Eaman Jahani
Eaman Jahani是馬里蘭大學商學院信息系統專業的助理教授 。
他曾在UC伯克利統計系擔任博士后研究員 , 還獲得了MIT的社會工程系統與統計學雙博士學位 。
Benjamin S. Manning
Benjamin S. Manning目前是MIT斯隆管理學院IT組的四年級博士生 。 他曾獲得MIT碩士學位和華盛頓大學學士學位 。
他的研究圍繞兩個相輔相成的方向:(1) 利用AI系統進行社會科學發現;(2) 探索AI系統如何代表人類并按照人類指令行事 。
Joe Zhang
Joe Zhang目前是斯坦福大學博士生 , 此前 , 曾獲得了普林斯頓大學的學士學位 。
個人的研究喜歡從人機交互到社會科學等多個學術領域汲取靈感 , 試圖理解新興的人機協作系統及其對商業和社會的影響 。
參考資料:
https://arxiv.org/abs/2407.14333v5
【一句話性能暴漲49%!馬里蘭MIT等力作:Prompt才是大模型終極武器】https://x.com/connordavis_ai/status/1957057335152836737
推薦閱讀













- 400萬人圍觀的分層推理模型,分層架構不起作用?性能另有隱情?
- 英睿達T710 2TB SSD評測:新一代性能旗艦 14.5G/s僅有57度
- 2799元搭載驍龍8至尊,追求性能直接放棄,說一點真相
- 24K鍍金!新機官宣:超旗艦性能+全面屏,現已開售
- 榮耀豁出去了,7200mAh+16GB+512GB,頂級性能旗艦售價一降再降
- 天璣9500架構深度解讀 | CPU架構大變,性能反超高通?
- 谷歌開源Gemma 3 270M,性能超越Qwen 2.5同級模型
- 超高性價比游戲本平臺!銳龍9 8940HX性能評測
- 蘋果新mini曝光,性能看齊iPhone 17 Pro!
- 5個隱形性能殺手正在悄悄拖慢你的電腦速度