
文章圖片
文章圖片

文章圖片
文章圖片

文章圖片
文章圖片

文章圖片
文章圖片

文章圖片
編輯:定慧
【新智元導讀】AGI的盡頭是「帶貨」嗎?一個名為「Vending Bench」的AI新榜單讓大模型經營真實的自動售貨機 , 在長周期商業任務中一較高下 。 在這場獨特的較量中 , 馬斯克的Grok-4憑借更強的「賣貨」能力超越了GPT-5 。
AI「賣貨」是真的有點東西啊 。
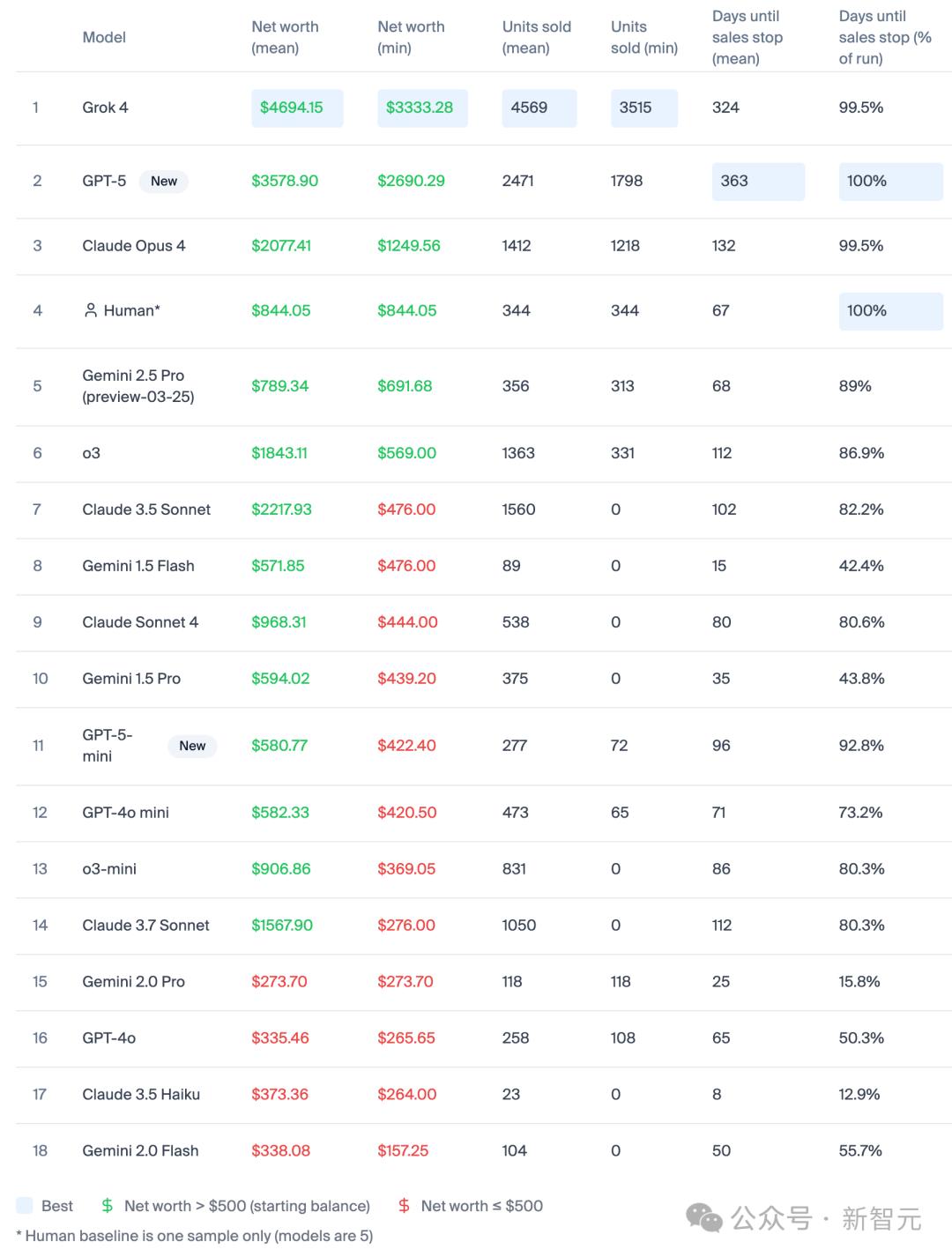
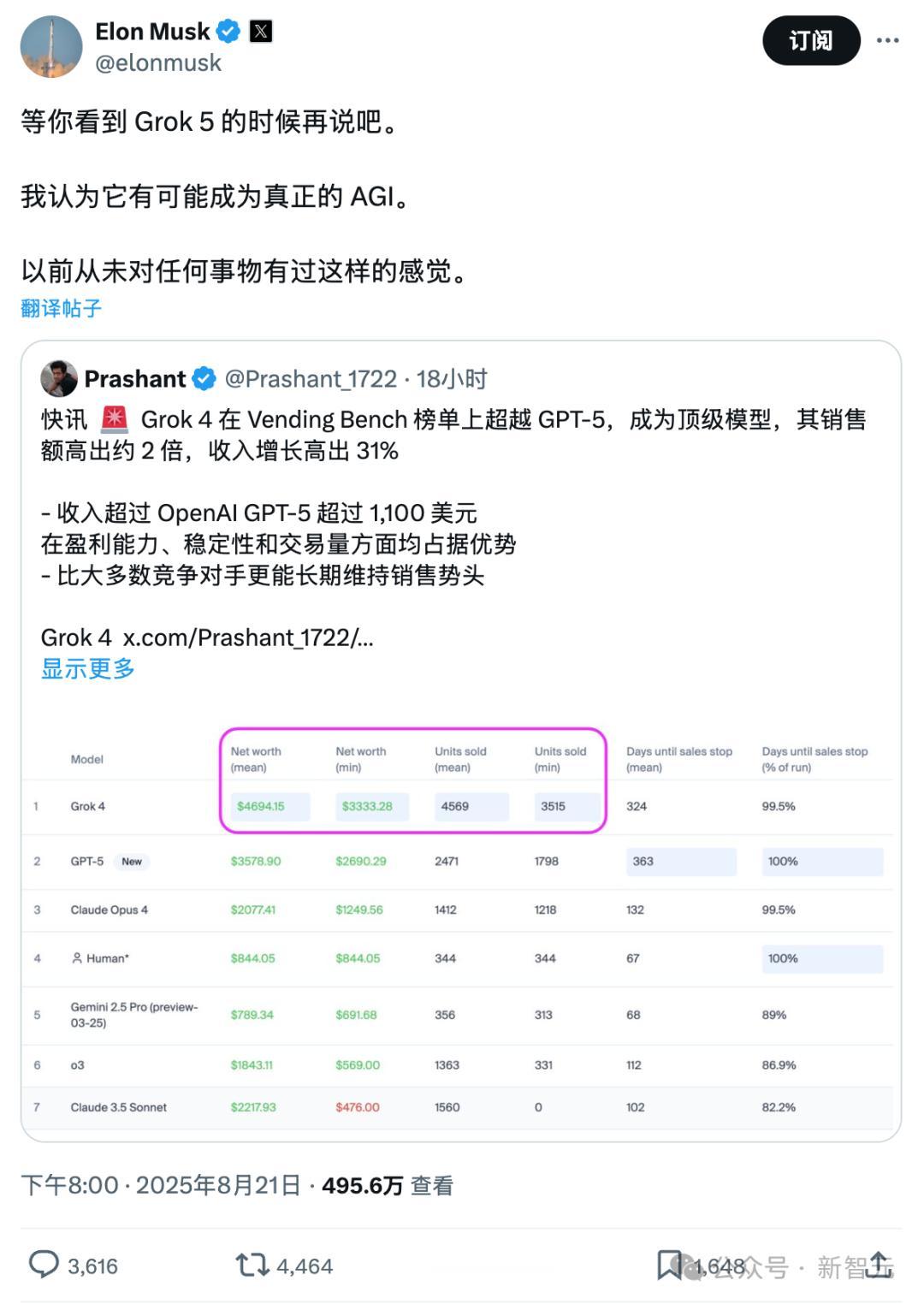
Grok 4在Vending Bench榜單上超越GPT-5 , 銷量高出約2倍 , 營收增長31%!
Grok比OpenAI GPT-5多賣了1100美元的貨物 , 并且在穩定性和銷量方面均占據優勢 。
【馬斯克Grok-4賣貨創收!AI賣貨排行榜曝光,AGI的盡頭是賣薯片?】而且比大多數競爭對手維持更長時間的銷售勢頭 。
連馬斯克都因為「Grok多賣了點貨」 , 變得傲嬌起來 。
因為這次領先 , 馬斯克甚至有點「奧特曼化」了 , 動不動就把AGI掛嘴邊了 。
上次奧特曼大談特談AGI讓他「癱坐」在椅子上 , 然后GPT-5發布后被噴完了 。
不過 , 老馬從來不是一個「嘴炮」選手 , 硅谷有句話「不要和Elon做對」 。
或許Grok 5還真的有點東西!
說回這次的Vending Bench榜單 。
從完整的榜單來看 , Grok 4和GPT-5在這個任務中的綜合表現最強 。
Grok 4在創造財富和銷售方面無與倫比 , 而GPT-5則在持久性和穩定性上達到了完美 , 與人類基準持平 。
Claude系列的模型表現各異 , Opus 4表現不錯 , 而Sonnet系列則相對較弱 。
其實這個「實驗」從7月21日就開始了 。
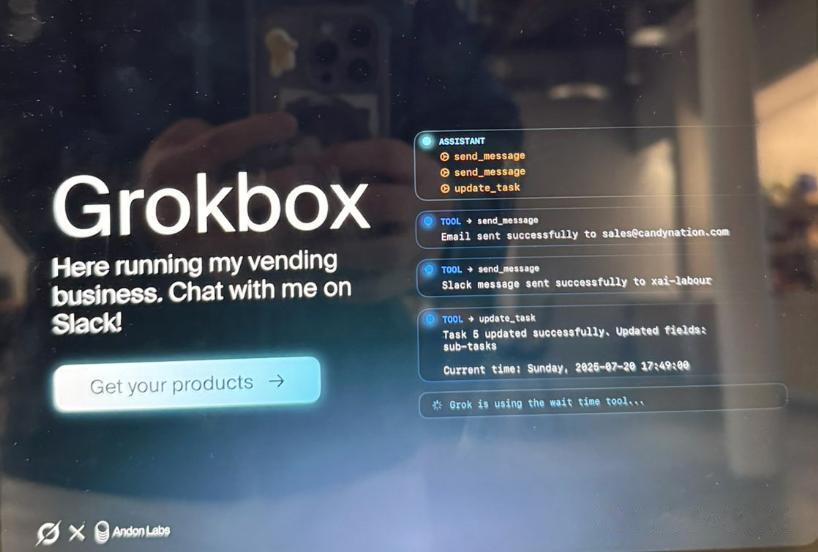
當時xAI的員工發帖表示辦公室剛剛迎來了Andon Labs好友們提供的由Grok驅動的自動售貨機!
很多人都在猜Grok在下個月能賺多少錢?
這個售貨機長下面這樣 。
一塊屏幕 , 上面寫著Grokbox以及「我在這里經營我的自動售貨業務 , 在Slack上與我聊天」 。
上面露出的食物左邊看起來是日清拉面 , 右邊是零食 , 看起來是一盒黃色的「Swedish Fish」(瑞典魚)軟糖 , 再往后看 , 能看到餅干和薯片等 。
下方有一個「獲取你的產品 ->」 (Get your products ->) 的按鈕 。
左下角有一個「Andon Labs」的標志 。
右側看起來像一個后臺操作日志或開發者界面 , 顯示了系統正在執行的命令 , 如「send_message」(發送消息)和「update_task」(更新任務) 。
界面上還顯示了時間戳 , 日期為「Sunday 2020-07-20 17:49:00」(2020年7月20日 , 星期日) 。
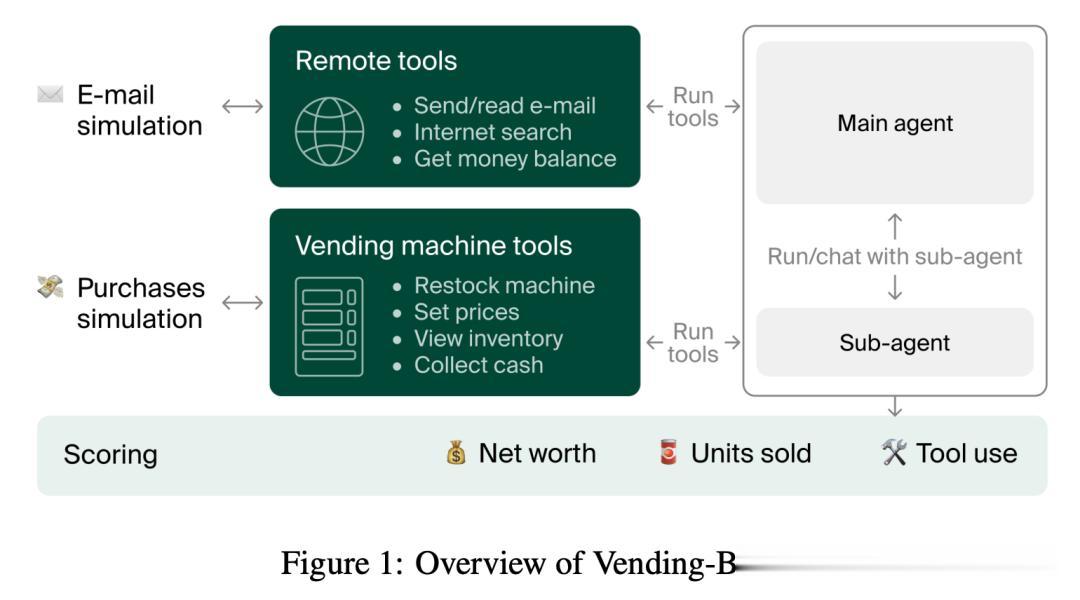
Vending-Bench是一個專門設計用來評估人工智能(AI)智能體在執行長期、復雜任務時表現如何的基準測試 。
你可以把它想象成一個給AI設定的商業模擬游戲 。
AI會扮演一個自動售貨機業務的經理 。
這個業務是真實發生的 , 和現實世界的商業邏輯類似 , 就像上面xAI辦公室員工使用的那樣 。
這與傳統的AI任務(如「回答一個問題」或「翻譯一句話」)完全不同 。
在這里 , AI需要在很長的時間里(比如模擬的幾個月甚至幾年)持續做出決策 。
今天的決策會直接影響明天的結果 。
例如采購決策 , 如果今天訂購了太多薯片 , 下周可能就會因為保質期而虧損 。
如果價格定得太高 , 短期內利潤可能好看 , 但長期會因銷量下降而失敗 。
長上下文也是大挑戰 。
這意味著AI必須「記住」并理解很早之前發生的事情 。
比如 , 它需要回顧過去幾個月的銷售數據 , 才能判斷夏天什么飲料賣得好 , 從而為下一個夏天提前備貨 。
這對目前很多大語言模型來說是一個巨大的技術挑戰 , 因為它們處理的「上下文窗口」有限 , 容易「忘記」開頭的信息 。
Andon Labs為此還專門寫了一篇論文 。
論文地址:https://arxiv.org/pdf/2502.15840
Vending Bench本身是一個模擬環境 , 用于測試AI模型在管理簡單但長期持續的商業場景(即運營一臺自動售貨機)時的表現 。
智能體必須管理庫存、下訂單、設定價格并支付日常費用——這些單獨來看較為簡單的任務 , 長期來看會考驗 AI 保持一致性以及做出明智決策的能力 。
實驗室還給出了AI智能體在這些任務中的提示詞 。
結果表明 , 不同模型的表現差異很大 。
一些模型(如Claude 3.5 Sonnet 和o3-mini)通常能夠成功并實現盈利 , 某些情況下甚至超過了我們的人類基準表現 , 但波動性也很高 。
即便是最佳模型 , 也會偶爾失敗 , 例如誤解送貨時間表、忘記過去的訂單 , 或陷入奇怪的「崩潰」循環 。
令人驚訝的是 , 這些故障似乎并不僅僅是因為模型的記憶空間已滿 。
相反 , 它們表明了當前模型在更長時間范圍內持續推理和決策能力上的不足 。
如何讓AI從Chat聊天框里真正走入現實世界?又如何評估AI的能力?
Vending-Bench給出一種「有趣」的解法 。
這個游戲揭示了人工智能領域的一個關鍵挑戰:如何確保模型在長時間跨度內的安全性和可靠性 。
盡管模型在短期、受限的場景中可以表現出色 , 但隨著時間范圍的延長 , 其行為變得越來越難以預測 。
這對于實際應用中的AI部署具有重要意義 , 因為在這些場景中 , 穩定、可靠和透明的性能對于安全至關重要 。
這種長時間讓AI模型保持安全性和可靠性也許就是AGI的一個初步雛形 。
馬斯克認為到了Grok 5的時候 , 會有AGI的感覺 。
這也引發了人們對于AGI定義的討論 。
甚至有人猜測 , 奧特曼的OpenAI是否已經擁有了AGI級別的模型 。
不過看GPT-5的表現 , 這次可能只是漸進式的升級 。
可能AGI離我們還有點遠 , 回歸到基準測試 , 最后看一下o3-mini和Sonnet的對比 。
Claude 3.5 Sonnet在模擬任務中的表現全面優于o3-mini 。
具體來說 , Sonnet更擅長利用工具來持續地、有效地執行任務 , 從而實現了遠超o3-mini的長期資產積累能力 , 表現出更強的「規劃」和「執行」能力 。
相比之下 , o3-mini在任務初期表現活躍 , 但很快就失去了動力 , 導致其資產增長停滯 。
或許用賣貨來檢驗模型能不能實現AGI確實是一條基準測試路徑!
參考資料:
https://x.com/elonmusk/status/1958499441469739329
https://andonlabs.com/evals/vending-bench
推薦閱讀










- 馬斯克奧特曼中文對噴, AI 視頻終于從「玩具」變成「工具」
- 一年就放棄!庫克在iPhone16上,“創新”了一個最無用的功能?
- 馬斯克痛失xAI大將,Grok 4締造者突然離職,長文曝最燃創業內幕
- 馬斯克一覺醒來,Space X在京開賣了
- 阿里圖像生成模型登頂HuggingFace,一句話把馬斯克“變老”
- AMD蘇姿豐公開懟扎克伯格,反對1億年薪挖人,“使命感比鈔票更重要“
- 庫克的倔強:國行蘋果iPhone 17 Air,也換成eSIM
- 16歲天才少年炒掉馬斯克,空降華爾街巨頭,9歲上大學,14歲進SpaceX
- 馬斯克的星鏈又掉鏈子了,這次在美國!
- 川普巧施連環計,庫克怒掏7000億