
文章圖片
文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片
本文作者楊磊 , 目前在大模型初創公司階躍星辰擔任后訓練算法工程師 , 其研究領域包括生成模型和語言模型后訓練 。 在這之前 , 他曾在曠視科技擔任了六年的計算機視覺算法工程師 , 從事三維視覺、數據合成等方向 。 他于 2018 年本科畢業于北京化工大學 。
當前 , 主流的基礎生成模型大概有五大類 , 分別是 :Energy-Based Models (Diffusion)、GAN、Autoregressive、VAE 和 Flow-Based Models 。
本項工作提出了一種全新的生成模型:離散分布網絡(Discrete Distribution Networks) , 簡稱 DDN 。 相關論文已發表于 ICLR 2025 。
DDN 采用一種簡潔且獨特的機制來建模目標分布:
1.在單次前向傳播中 , DDN 會同時生成 K 個輸出(而非單一輸出) 。
2.這些輸出共同構成一個包含 K 個等權重(概率均為 1/K)樣本點的離散分布 , 這也是「離散分布網絡」名稱的由來 。
3.訓練目標是通過優化樣本點的位置 , 使網絡輸出的離散分布盡可能逼近訓練數據的真實分布 。
每一類生成模型都有其獨特的性質 , DDN 也不例外 。 本文將重點介紹 DDN 的三個特性:
零樣本條件生成 (Zero-Shot Conditional Generation ZSCG) 樹狀結構的一維離散潛變量 (Tree-Structured 1D Discrete Latent) 完全的端到端可微分 (Fully End-to-End Differentiable)
論文標題: 《Discrete Distribution Networks》 論文鏈接: https://arxiv.org/abs/2401.00036 項目鏈接: https://discrete-distribution-networks.github.io/ 代碼地址: https://github.com/DIYer22/discrete_distribution_networks離散分布網絡原理
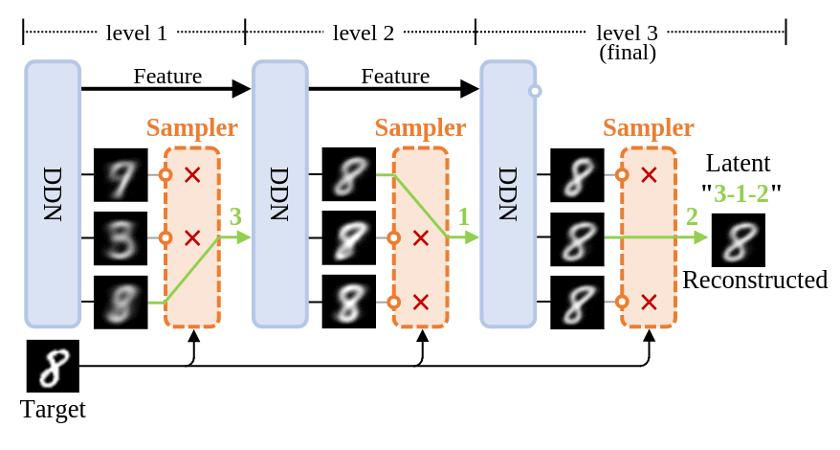
圖1: DDN 的重建過程示意圖
首先 , 借助上圖所示的 DDN 重建流程作為切入點來一窺其原理 。 與 diffusion 和 GAN 不同 , 它們無法重建數據 , DDN 能像 VAE 一樣具有數據重建能力:先將數據映射為 latent, 再由 latent 生成與原始圖像高度相似的重建圖像 。
上圖展示了 DDN 重建 target 并獲得其 latent 的過程 。 一般 DDN 內部包含多個層級結構 , 其層數為 L , 示意圖里 L=3 。 但先讓我們把目光集中在最左側的第一層 。
離散分布: 正如上文所言 , DDN 的核心思想在于讓網絡同時生成 K 個輸出 , 從而表示「網絡輸出了一個離散分布」 。 因此每一層 DDN 都有 K 個 outputs , 即一次性輸出 K 張不同的圖像 , 示意圖中 K=3 。 每個 output 都代表了這個離散分布中的一個樣本點 , 每個樣本點的概率質量相等 , 均為 1/K 。
層次化生成: 最終目標是讓這個離散分布 (K 個 outputs) , 和目標分布(訓練集)越接近越好 , 顯然 , 單靠第一層的 K 個 outputs 無法清晰地刻畫整個 MNIST 數據集 。 第一層獲得的 K 張圖像更像是將 MNIST 聚為 K 類后得到的平均圖像 。 因此 , 我們引入「層次化生成」設計以獲得更加清晰的圖像 。
接著 , 從第二層的 outputs 中繼續選擇出和 target 最相似的一張作為第三層的 condition , 并重復上述過程 。 隨著層數增加 , 生成的圖像和 target 會越來越相似 , 最終完成對 target 的重建 。
Latent: 這一路選下來 , 每一層被選中 output 的 index 就組成了 target 的 latent(圖中綠色部分「3-1-2」) 。 因此 latent 是一個長度為 L 取值范圍 [1K
的整數數組 。
網絡結構
將「重建過程示意圖」進一步細化 , 就有下圖 (a) 的網絡結構圖:
DDN 網絡結構示意圖和支持的兩種網絡結構形式
在圖 (a) 中 , 把生成相關的設計整合為 Discrete Distribution Layer (DDL) ,把僅提供基礎計算的模塊封裝為了 NN Block , 并重點展示訓練時 DDL 內部的數據流 。 主要關注以下幾點:
第一層 DDN 的輸入為 zero tensor , 不需要任何 condition; DDL 內部通過 K 個 conv1x1 來同時生成 K 個 outputs;
右側的 (b)、 (c) 兩圖分別展示了 DDN 支持的兩種網絡結構形式:
(c)Recurrence Iteration: 各層 DDL 共享相同參數 , 類似 diffusion 模型 , 需要做多次 forward 才能生成樣本 。出于計算效率考慮 , DDN 默認采用具有 coarse-to-fine 特性的 single shot generator 形式 。
損失函數
此外 , 本文還提出了 Split-and-Prune 優化算法來使得訓練時每個節點被 GT 匹配上的概率均勻 , 都是 1/K 。
下圖展示了 DDN 做二維概率密度估計的優化過程:
左:生成樣本集;右:概率密度GT
實驗與特性展示
隨機采樣效果展示
在人臉數據集上的隨機采樣效果
更通用的零樣本條件生成
先描述一下「零樣本條件生成」(Zero-Shot Conditional Generation ZSCG)這個任務:
首先 , Unconditional 地訓練一個生成模型 , 即訓練階段 , 模型只見過圖像 , 沒有見過任何 condition 信號 。 在生成階段 , 用戶會提供 condition , 比如 text prompt、低分辨率圖像、黑白圖像 。 任務目標:讓已經 unconditional 訓練好的生成模型能根據 condition 生成符合對應 condition 的圖像 。 因為在訓練階段 , 模型沒見過任何的 condition 信號 , 所以叫 Zero-Shot Conditional Generation 。
用 Unconditional DDN 做零樣本條件生成效果:DDN 能在不需要梯度的情況下 , 使不同模態的 Condition (比如 text prompt 加 CLIP) 來引導 Unconditional trained DDN 做條件生成 。 黃色框圈起來部分就是用于參考的 GT 。 SR 代表超分辨率、ST 代表 Style Transfer 。
如上圖所示 , DDN 支持豐富的零樣本條件生成任務 , 其做法和圖 1 中的 DDN 重建過程幾乎一樣 。
具體而言 , 只需把圖 1 中的 target 替換為對應的 condition , 并且 , 把采樣邏輯調整為從每一層的多個 outputs 中選出最符合當前 condition 的那一個 output 作為當前層的輸出 。 這樣隨著層數的增加 , 生成的 output 越來越符合 condition 。 整個過程中不需要計算任何梯度 , 僅靠一個黑盒判別模型就能引導網絡做零樣本條件生成 。 DDN 是第一個支持如此特性的生成模型 。
換為更專業的術語描述便是:
DDN 是首個支持用純粹判別模型引導采樣過程的生成模型;
某種意義上促進了生成模型和判別模型的大一統 。
這也意味著用戶能夠通過 DDN 高效地對整個分布空間進行篩選和操作 。 這個性質非常有趣 , 可玩性很高 , 個人感覺「零樣本條件生成」將會得到廣泛的應用 。
Conditional Training
【全新生成模型「離散分布網絡DDN」如何做到原理簡單,性質獨特?】訓練 conditional DDN 非常簡單 , 只需要把 condition 或者 condition 的特征直接輸入網絡中 , 網絡便自動學會了 P (X|Y) 。
此外 , conditional DDN 也可以和 ZSCG 結合以增強生成過程的可控性 , 下圖的第四 / 五列就展示了以其它圖像為 ZSCG 引導的情況下 conditional DDN 的生成效果 。
Conditional-DDNs 做上色和邊緣轉 RGB 任務 。 第四、五列展示了以其它圖像為引導的情況下 , 零樣本條件生成的效果 , 生成的圖像會在保證符合 condition 的情況下盡可能靠近 guided 圖像的色調 。
端到端可微分
DDN 生成的樣本對產生該樣本的計算圖完全可微 , 使用標準鏈式法則就能對所有參數做端到端優化 。 這種梯度全鏈路暢通的性質 , 體現在了兩個方面:
1.DDN 有個一脈相承的主干 feature , 梯度能沿著主干 feature 高效反傳 。 而 diffusion 在傳遞梯度時 , 需多次將梯度轉換到帶噪聲的樣本空間進行反傳 。
2.DDN 的采樣過程不會阻斷梯度 , 意味著網絡中間生成的 outputs 也是完全可微的 , 不需要近似操作 , 也不會引入噪聲 。
理論上 , 在利用判別模型做 fine-tuning 的場景或著強化學習任務中 , 使用 DDN 作為生成模型能更高效地 fine-tuning 。
獨特的一維離散 latent
DDN 天然具有一維的離散 latent 。 由于每一層 outputs 都 condition on 前面所有的 results , 所以其 latent space 是一個樹狀結構 。 樹的度為 K , 層數為 L , 每一個葉子節點都對應一個 DDN 的采樣結果 。
DDN 的 latent 空間為樹狀結構 , 綠色路徑展示了圖 1 中的 target 所對應的 latent
Latent 可視化
為了可視化 latent 的結構 , 我們在 MNIST 上訓練了一個 output level 層數 L=3 , 每一層 output nodes 數目 K=8 的 DDN , 并以遞歸九宮格的形式來展示其 latent 的樹形結構 。 九宮格的中心格子就是 condition , 即上一層被采樣到的 output , 相鄰的 8 個格子都代表基于中心格子為 condition 生成的 8 個新 outputs 。
Hierarchical Generation Visualization of DDN
未來可能的研究方向
通過調參工作、探索實驗、理論分析以改進 DDN 自身 , Scaling up 到 ImageNet 級別 , 打造出能實際使用、以零樣本條件生成為特色的生成模型 。 把 DDN 應用在生成空間不大的領域 , 例如圖像上色、圖像去噪 。 又或者 Robot Learning 領域的 Diffusion Policy 。 把 DDN 應用在非生成類任務上 , 比如 DDN 天然支持無監督聚類 , 或者將其特殊的 latent 應用在數據壓縮、相似性檢索等領域 。 用 DDN 的設計思想來改進現有生成模型 , 或者和其它生成模型相結合 , 做到優勢互補 。 將 DDN 應用在 LLM 領域 , 做序列建模任務 。
推薦閱讀










- 比GPT-5還準?AIME25飆到99.9%刷屏,開源模型首次!
- 中南大學等機構突破難題:讓AI真正理解長文本并生成完美圖像
- 希伯來大學讓AI\考官\幫你從千萬個模型里找到最合適的那一個
- 阿里通義新一代語音模型Fun-ASR再進化 垂直領域識別準確率提超15%
- GPT-5變蠢背后:抑制AI的幻覺,反而讓模型沒用了?
- Windows 12.2曝光:全新開始菜單 支持Windows 7主題
- 華為新品官宣:8月22日,全新開售
- 蘋果吸取教訓?iPhone 17 全新保護殼登場,布面質感+抗污耐用
- 高通莊思民解讀6G:AI原生的6G設計賦能全新服務,邁向AI互聯未來
- 究竟會花落誰家?DeepSeek最新大模型瞄準了下一代國產AI芯片