
文章圖片

文章圖片
文章圖片

隨著 AI 技術的飛速發展 , 從「快思考」到 「慢思考」 , 大語言模型(LLMs)在處理復雜推理任務上展現出驚人的能力 。 無論是我們熟知的思維鏈(CoT) , 還是更復雜的深度思考模式(Thinking) , 都讓 AI 的回答日益精準、可靠 。
然而 , 這種性能的提升并非沒有代價 。 模型在推理過程中會產生大量的中間步驟和文本(tokens) , 這不僅極大地拖慢了計算速度 , 還對內存和計算資源造成了巨大的壓力 。 簡單來說 , 就是「想得越多 , 算得越慢 , 耗得越多」 。
為了解決這一難題 , 研究者們從人類的認知過程中汲取靈感 。 想象一下人類在解決一個復雜數學題時的情景:我們通常會在草稿紙上寫下關鍵的計算步驟(如下圖 a 中的黃色高亮部分) , 而將一些輔助性的思考過程(非高亮部分)放在腦中 。
圖 1:(a) 展示了一個典型的思維鏈推理過程 , 黃色部分為關鍵步驟 。 (b) 對比了傳統方案 Vanilla 與 LightThinker 的推理流程 。
本文中 , 來自浙江大學、螞蟻集團等機構的研究者提出了 LightThinker , 它模仿了這一高效的思考模式 。 它訓練 LLM 在推理過程中動態地將冗長的中間思考步驟壓縮成緊湊的表示(gist tokens /cache tokens) , 然后「扔掉」原始的、繁瑣的推理鏈 , 僅保留核心摘要以繼續下一步的思考 。這樣一來 , 存放在上下文窗口中的 tokens 數量被大幅削減 , 從而顯著降低了內存占用和計算成本 。
論文標題:LightThinker: Thinking Step-by-Step Compression 論文鏈接: https://arxiv.org/abs/2502.15589 代碼鏈接: https://github.com/zjunlp/LightThinker
LightThinker 概覽
LightThinker 通過訓練的方式讓模型具備這種能力 。 這涉及到兩個關鍵問題:「何時壓縮?」和「如何壓縮?」 。 整個過程可以概括為以下三個關鍵步驟:
第一步:數據重構 —— 在思考流程中植入「壓縮指令」
LightThinker 的第一步就是改造訓練數據 , 讓 LLM 明白「壓縮」這個動作的存在和時機。 具體操作是:
步驟劃分:首先 , 將模型原本冗長的完整回答 Y , 按照語義或段落(即一個完整的「想法」)切分成若干個思維步驟 S1 S2 S3 ... 。插入特殊指令符:在這些思維步驟之間 , 插入一組特殊的「指令令牌」4 。 這組指令符主要包含兩個部分:
緩存令牌 (Cache Tokens C):這是一組特殊的、用于存儲壓縮后信息的「摘要令牌」 。 它的作用就像是為即將產生的「思想摘要」預留的空白便簽 。 輸出令牌 (Output Token [o
):這是一個強制性的輸出信號 , 它的作用是告訴模型:「好了 , 摘要寫完了 , 現在請基于這份摘要繼續你下一步的思考」。
經過這樣的改造 , 原本一條完整的思考鏈 , 就變成了一個「思考步驟 1 S1 → 進行壓縮 → 繼續思考步驟 S2 → 再次壓縮 → ...」的全新格式 。 這等于是在模型的學習材料中明確地標注出了「何時」需要進行壓縮 。
注意 , 研究者在具體實現中 , 采用換行符作為思維步驟的劃分 , 此處不存在任何數據精心構造的過程 。
第二步:注意力改造 —— 學會壓縮與理解壓縮的內容
教會了模型「何時」壓縮 , 下一步就是最關鍵的如何壓縮 。 這主要通過一種名為 「Thought-based Attention Mask」的技術來實現 , 如圖 2 (b) 所示 。 精確地控制著模型在思考時 “能看什么” 和 “不能看什么”。
這個過程分為兩個階段:
壓縮階段(生成思維摘要):當模型需要將思維步驟 Si 壓縮進緩存令牌 C 時 , 注意力掩碼會強制這些 C 令牌只能「看到」三個東西:
最初的問題 X; 先前已經壓縮好的歷史摘要; 當前正在處理的思維步驟 Si 。
其他所有原始的、未壓縮的思維步驟都會被「遮蔽」 。 這迫使模型必須將 Si 中的所有關鍵信息高度濃縮并存儲到 C 中。
生成階段(基于摘要生成思維):當思維步驟 Si 被成功壓縮進 C 之后 , 更關鍵的一步來了 。 在生成下一個思緒片段 S (i+1) 時 , 注意力掩碼會徹底「遮蔽」掉原始的思維步驟 Si 。 此時 , 模型只能「看到」最初的問題 X 和包括剛剛生成的摘要在內的所有歷史摘要。
通過這種方式 , 模型被迫學會僅依賴緊湊的「思想摘要」來進行連貫的、層層遞進的推理 , 而不是依賴越來越長的原始思考全文 。
第三步:動態推理 ——「即用即棄」的高效循環
經過以上兩個步驟的訓練 , LightThinker 模型在實際推理時 , 就會形成一種高效的動態循環 , 如圖 1 (b) 和圖 2 (c) 所示 , 清晰地展示了「生成→壓縮→拋棄」的動態循環過程 。 下面以圖 1 (b) 為例進行分析:
模型接收問題 , 生成第一段思考(Thought 1) 。觸發壓縮 , 將 Thought 1 中的核心信息壓縮成緊湊的摘要(CT1) 。拋棄原文 , 將冗長的 Thought 1 從上下文中丟棄 。模型基于問題和摘要(CT1) , 生成第二段思考(Thought 2) 。再次壓縮 , 將 Thought 2 壓縮為摘要(CT2) , 并丟棄 Thought 2 原文 。如此循環 , 直到問題解決 。
通過這種「即用即棄」的機制 , LightThinker 確保了模型的上下文窗口始終保持在一個非常小的尺寸 , 從而解決了因上下文過長導致的內存爆炸和計算緩慢問題 , 實現了效率與性能的完美平衡 。
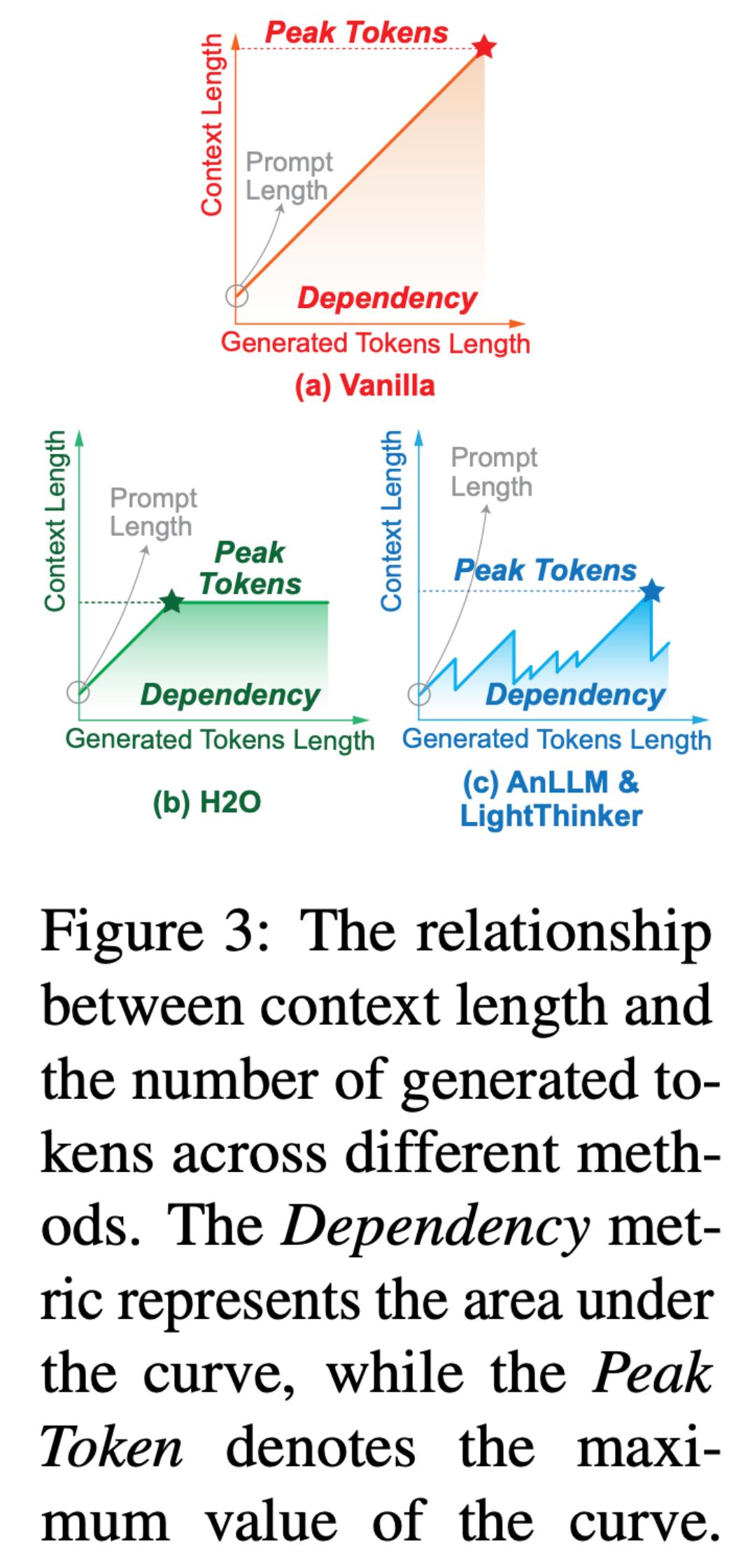
圖 3 展示了不同方法在推理過程中上下文長度的變化 , 其中曲線和坐標軸圍城的面積為我們定義的新指標 Dependency , 其意義生成 token 時需要關注 token 的數量總和 。
實驗結果
研究者在四個數據集和兩個不同的模型上對 LightThinker 進行了廣泛的測試 , 結果如表 1 所示 。
表 1 主要實驗結果 。 Acc 為準確率 , Time 為平均推理耗時 , Peak 為平均峰值 token 占用數量 , Dep 為生成 token 時需要關注 token 的數量總和(如圖 3)所示 。
結果表明 , 在 Qwen 系列模型上 , 與傳統模型(Vanilla)相比:
峰值內存使用減少 70%:LightThinker 極大地節約了寶貴的內存資源 。 推理時間縮短 26%:在保證結果準確性的前提下 , 思考速度得到了顯著提升 。 取得了準確度和效率的平衡 。
此外 , 在 Llama 上 , 也取得了準確度和效率的平衡 。
相關工作
當前關于加速大語言模型(LLMs)推理過程的研究主要集中在四類方法:模型量化、輔助解碼、生成更少的 Token 和減少 KV 緩存 。 模型量化包括參數量化 [1-2
和 KV 緩存量化 [3-4
, 輔助解碼主要包括投機采樣 , 本節將重點關注后兩類方法 。
需要注意的是 , 生成長文本和理解長文本代表著不同的應用場景 , 因此 , 專門針對長文本生成階段的加速方法(例如 , 預填充階段加速技術如 AutoCompressor [5
、ICAE [6
、LLMLingua [7
、Activation Beacon [8
、SnapKV [9
和 PyramidKV [10
)不在此處討論 。 以下是后兩類方法的詳細概述 。
生成更少的 Token
這一類別可以根據推理過程中使用的 token 數量和類型進一步分為三種策略:
離散 Token 減少通過提示工程 Prompt [11-13
、指令微調 [14-15
或強化學習 [16-17
等技術來引導 LLM 在推理過程中使用更少的離散 token 。 例如 , TALE [11
提示 LLM 在預定義的 token 預算內完成任務 。 Arora 和 Zanette [16
構建特定數據集并采用強化學習獎勵機制來鼓勵模型生成簡潔準確的輸出 , 從而減少 token 使用量 。 連續 Token 替換這些方法 [18-19
探索使用連續空間 token 代替傳統的離散詞匯 token 。 一個代表性例子是 CoConut [18
, 它利用課程學習來訓練 LLM 使用連續 token 進行推理 。 無 Token 使用通過在模型層之間內化推理過程 , 在推理過程中直接生成最終答案而不需要中間 token [20-21
。
這三種策略都是在模型訓練后實施的 , 推理過程中不需要額外干預 。 從技術上講 , 這些方法的加速效果依次遞增 , 但代價是 LLM 的泛化性能逐漸下降 。 此外 , 第一種策略并不能顯著減少 GPU 內存使用 。
減少 KV 緩存
這一類別可以分為兩種策略類型:基于剪枝的離散空間 KV 緩存選擇和基于合并的連續空間 KV 緩存壓縮 。
基于剪枝的策略設計特定的淘汰策略 [22-25
在推理過程中保留重要的 token 。 例如 , StreamingLLM [23
認為初始的 sink token 和最近的 token 是重要的;H2O [22
關注具有高歷史注意力分數的 token;SepLLM [24
強調對應于標點符號的 token 是重要的 。 基于合并的策略引入錨點 token , 訓練 LLM 將歷史重要信息壓縮到這些 token 中 , 從而實現 KV 緩存合并 [26
。
這兩種策略都需要在推理過程中進行干預 。 關鍵區別在于:第一種策略是無需訓練的 , 但對每個生成的 token 都要應用淘汰策略;而第二種策略是基于訓練的方法 , 允許 LLM 自主決定何時應用淘汰策略 。
局限性
受限于自身的數據重構方案(目前分割思維步驟是依賴規則 , 而不是基于語義)和訓練數據(約 16K 訓練數據) , 本文方法在數學相關的任務上表現并不出色 。
如下圖所示 , 展示了 LightThinker 在 GSM8K 上的一個 Bad Case 。 研究者觀察到 , 盡管 LLM 在思考過程中得出了正確答案(見上圖中的 Model's Thoughts 字段) , 但在最終輸出中卻出現了錯誤(見圖中的 Model's Solution 字段) 。
具體來說 , 在 Model's Solution 字段的第三句話中 , 第一次出現的「4000」是錯誤的 。 這表明在第二次壓縮步驟中發生了信息丟失(理論上 , 「8000」、「4000」和「24000」都應該被壓縮 , 但 LLM 只壓縮了「4000」和「24000」) , 導致后續的推理錯誤 。 這類錯誤在 GSM8K 數據集中頻繁出現 , 表明當前的壓縮方法對數值的敏感度還不夠 。
參考文獻
[1
Lin J Tang J Tang H et al. AWQ: Activation-aware weight quantization for on-device LLM compression and acceleration. MLSys 2024.
[2
Dettmers T Lewis M Belkada Y et al. GPT3.INT8 (): 8-bit matrix multiplication for transformers at scale. NeurIPS 2022.
[3
Liu Z Yuan J Jin H et al. KIVI: A tuning-free asymmetric 2bit quantization for KV cache. ICML 2024b.
[4
Hooper C Kim S Mohammadzadeh H et al. KVQuant: Towards 10 million context length LLM inference with KV cache quantization. NeurIPS 2024.
[5
Chevalier A Wettig A Ajith A et al. Adapting language models to compress contexts. EMNLP 2023.
[6
Ge T Hu J Wang L et al. In-context autoencoder for context compression in a large language model. ICLR 2024.
[7
Jiang H Wu Q Lin C et al. LLMLingua: Compressing prompts for accelerated inference of large language models. EMNLP 2023.
[8
Zhang P Liu Z Xiao S et al. Long context compression with activation beacon. arXiv:2401.03462 2024b.
[9
Li Y Huang Y Yang B et al. SnapKV: LLM knows what you are looking for before generation. NeurIPS 2024.
[10
Cai Z Zhang Y Gao B et al. PyramidKV: Dynamic KV cache compression based on pyramidal information funneling. CoRR abs/2406.02069 2024.
[11
Han T Wang Z Fang C et al. Token-budget-aware LLM reasoning. CoRR abs/2412.18547 2024.
[12
Ding M Liu Z Fu Z et al. Break the chain: Large language models can be shortcut reasoners. CoRR abs/2406.06580 2024.
[13
Nayab S Rossolini G Buttazzo G et al. Concise thoughts: Impact of output length on LLM reasoning and cost. CoRR abs/2407.19825 2024.
[14
Liu T Guo Q Hu X et al. Can language models learn to skip steps? NeurIPS 2024a.
[15
Kang Y Sun X Chen L et al. C3oT: Generating shorter chain-of-thought without compromising effectiveness. CoRR abs/2412.11664 2024.
[16
Arora D Zanette A. Training language models to reason efficiently. arXiv:2502.04463 2025.
[17
Luo H Shen L He H et al. O1-pruner: Length-harmonizing fine-tuning for o1-like reasoning pruning. arXiv:2501.12570 2025.
[18
Hao S Sukhbaatar S Su D et al. Training large language models to reason in a continuous latent space. CoRR abs/2412.06769 2024.
[19
Cheng J Van Durme B. Compressed chain of thought: Efficient reasoning through dense representations. CoRR abs/2412.13171 2024.
[20
Deng Y Choi Y Shieber S. From explicit CoT to implicit CoT: Learning to internalize CoT step by step. CoRR abs/2405.14838 2024.
[21
Deng Y Prasad K Fernandez R et al. Implicit chain of thought reasoning via knowledge distillation. CoRR abs/2311.01460 2023.
[22
Zhang Z Sheng Y Zhou T et al. H2O: Heavy-hitter oracle for efficient generative inference of large language models. NeurIPS 2023.
[23
Xiao G Tian Y Chen B et al. Efficient streaming language models with attention sinks. ICLR 2024.
[24
Chen G Shi H Li J et al. SepLLM: Accelerate large language models by compressing one segment into one separator. CoRR abs/2412.12094 2024.
[25
Wu J Wang Z Zhang L et al. SCOPE: Optimizing key-value cache compression in long-context generation. CoRR abs/2412.13649 2024a.
【EMNLP 2025 | 動態壓縮CoT推理新方法LightThinker來了】[26
Pang J Ye F Wong D et al. Anchor-based large language models. ACL 2024
推薦閱讀













- ipad筆哪個牌子的好用?2025年精選10款好用的國產iPad筆推薦!
- 36氪CEO馮大剛發表主辦方致辭 | 36氪2025AI Partner百業大會
- 紡織印花機需求暴增76.6%!2025上半年中國工業打印機市場逆勢上揚
- 蘋果2025秋季發布會定檔,9大新品清單曝光(iPhone 17系列領銜)
- WRC2025:當頭部品牌從技術藍圖走進現實生活
- 2025公認“最耐用”的3款手機,滿級防水還耐摔,512GB用到2031年
- 可靈AI二季度又多賺了一個億,2025年收入預計比年初目標翻倍
- 蘋果官宣: 2025 年秋季特別活動定于 9 月 9 日,起售價 799 美元
- 拿下75%市場份額,華為折疊屏手機2025年上半年出貨量創新高
- IFA 2025首秀!雷神科技攜全線重磅產品閃耀登場