
文章圖片
文章圖片
全新RISC-V系列瞄準從邊緣到數據中心的AI主導地位 。
RISC-V 計算領域的領導者 SiFive 推出了其第二代智能系列處理器 , 這是在廣泛應用中加速人工智能工作負載的重大進步 。
新系列包含五款基于 RISC-V 的產品 , 其中有全新的 X100 系列(X160 Gen 2 和 X180 Gen 2) , 還有升級的 X280 Gen 2、X390 Gen 2 以及 XM Gen 2 產品 , 這些產品適用于高性能邊緣和數據中心場景 。
通過這些新系列 , SiFive 旨在把握人工智能解決方案需求快速增長的機遇 。 德勤預測 , 各技術環境中人工智能解決方案的需求將至少增長 20% , 其中人工智能邊緣計算的增長尤為顯著 , 將達到 78% 。
全新的 Intelligence 系列致力于增強標量、矢量以及 XM 系列的矩陣處理能力 , 以滿足現代人工智能工作負載的需求 。 SiFive 首席執行官 Patrick Little 強調了人工智能的關鍵作用 , 他表示:“人工智能正在催生 RISC-V 革命的新紀元 。 ”
該公司的產品已在市場上獲得廣泛應用 , 兩家美國一線半導體公司甚至在全新 X100 系列產品正式發布前就已獲得授權 。 這些早期采用者將 X100 IP 用于兩種不同的場景:一種是將 SiFive 標量矢量核心與矩陣引擎搭配 , 用作加速器控制單元;另一種是將矢量引擎用作獨立的人工智能加速器 。
為人工智能處理的未來而創新SiFive 的第二代產品解決了人工智能部署中的關鍵挑戰 , 特別是在內存管理和非線性函數加速方面 。 X 系列 IP 的一項核心創新是能夠用作加速器控制單元(ACU) 。
它允許 SiFive 內核通過專用協處理器接口 , 即 SiFive 標量協處理器接口(SSCI)和矢量協處理器接口擴展(VCIX) , 為客戶的定制加速器引擎提供必要的控制和輔助功能 。 這種架構能讓客戶專注于平臺級別的數據處理創新 , 進而簡化軟件堆棧 。
SiFive 高級首席架構師 John Simpson 曾詳細闡述過其相對于傳統方法的優勢 。 “傳統行業采用的是固化的強化方法 , 你無法改變有限狀態機 , ”Simpson 所指的是傳統的加速器架構 。
他指出 , 在快速發展的人工智能領域 , “每周都會出現新的人工智能模型架構” , 固定的有限狀態機無法適應新的架構類型 。 相比之下 , SiFive 的智能內核具備靈活性 , 通過允許在加速器芯片上進行本地處理 , 減少了系統總線流量 , 還促進了預處理和后處理任務的更緊密耦合 。
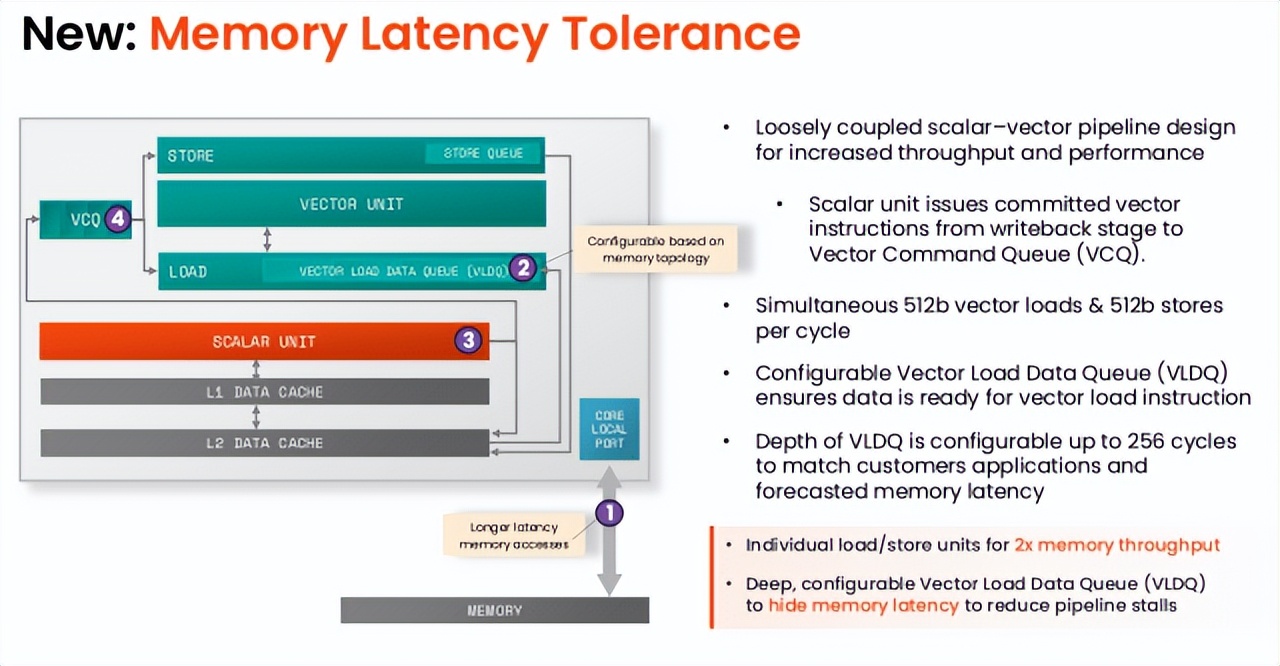
革命性的內存管理SiFive 在內存架構方面引入了兩項重大進步 , 直接解決了性能瓶頸問題 , 分別是內存延遲容忍度提升和內存子系統效率優化 。
Simpson 對內存延遲容忍功能尤為自豪 , 這是一項巧妙的設計 , 能夠隱藏加載延遲 。 他解釋道 , 處理所有指令的標量單元會將已提交的矢量指令調度到矢量命令隊列(VCQ) 。 關鍵的是 , 如果遇到矢量加載 , 其地址會在被放入 VCQ 的同時發送到內存系統(L2 或更高級別) 。
這種早期調度與執行分離的方式 , 允許內存響應返回并重新排序到可配置的矢量加載數據隊列(VLDQ) 。 “這樣做的目的是 , 加載操作將從矢量加載數據隊列中獲取正等待提取的數據 , ”Simpson 說 。
這確保了當加載指令最終從 VCQ 彈出時 , 數據已經準備就緒 , 從而實現 “矢量加載僅需一個周期” 。 Simpson 強調了這一競爭優勢 , 他指出:“在 Hot Chips 上發布的至強處理器可處理 128 個待處理請求 , 這是至強處理器的最高水平 , 而我們的四核處理器能處理 1024 個請求 。 ” 這項 “精妙的技術” 有效防止了流水線停頓 , 保障了持續處理 。
更高效的內存子系統是另一項重大升級 , 它從包含式緩存層級結構轉變為非包含式緩存層級結構 。 John Simpson 詳細介紹了上一代包含式緩存系統 , 在該系統中 , 共享 L3 緩存中的數據會被復制到私有 L2 和 L1 緩存 , 導致 2.5 MB 等效總緩存的有效利用率僅為 40% 。
第二代設計消除了這種復制 。 “現在數據無需在任何地方復制 , ”Simpson 解釋道 , 這使得 1.5 MB 等效空間的利用率達到了 100% 。
這意味著 “容量是第一代的 1.5 倍 , 面積利用率達到 60%” , 使其 “效率更高” 且 “輕松取勝” 。
除了內存方面的改進 , SiFive 還集成了全新的硬件流水線指數單元 。 雖然乘法累加器(MAC)在人工智能工作負載中占據主導地位 , 但指數運算將成為下一個主要瓶頸 。 例如 , 在由矩陣引擎加速的 BERT 大型模型中 , 涉及指數運算的 softmax 運算占據了剩余周期的 50% 以上 。
【SiFive發布第二代RISC-V IP】SiFive 的軟件優化將指數運算函數從 22 個周期減少到 15 個周期 , 而新的硬件單元將其大幅精簡為一條指令 , 使總運算時間縮短至 5 個周期 。 這種 “內置非線性加速” 對于最大限度地提高所有人工智能模型的加速效果至關重要 。
超大規模和全球影響力SiFive 的第二代 Intelligence 系列也正面向超大規模計算廠商 , 這些廠商正積極開發自己的定制芯片 。 盡管這些公司仍依賴 ARM 作為應用核心 , 但他們正積極將多個 SiFive XM 核心或自己的硬件矩陣引擎與 SiFive 的智能核心集成 , 以實現控制和輔助功能 。
這些超大規模企業懷揣著 “在數據中心取代英偉達(Nvidia)” 的雄心 , 其客戶的目標是通過 XM 核心將性能水平提高到每秒 4 千萬億次浮點運算 。
該公司也認可中國快速發展的 RISC-V 生態系統 , 并指出整個 Intelligence 系列在從數據中心到邊緣計算的各個領域都取得了重大設計成果 。 盡管由于保密協議 , 具體客戶名稱尚未公布 , 但 SiFive 表示 , 多家中國客戶對其 IP 的需求十分強勁 。
第二代 Intelligence 系列強大的軟件堆棧基于 SiFive 在 RISC-V 人工智能領域四年多的廣泛投入 , 支持可擴展性 。 對于 XM 系列 , 機器學習運行時已能將工作負載分配到單芯片上的多個 XM 集群中 。 雖然擴展到單芯片以上需要進一步開發處理器間通信(IPC)庫 , 但這仍是一個明確的路線圖項目 , 其驅動力來自客戶在單芯片上實例化多個 XM 的需求 。
SiFive 的全新 Intelligence 系列憑借創新的內存架構、專用接口和增強的處理能力 , 使 RISC-V 成為不斷發展的人工智能硬件領域的重要參與者 , 為從最小的邊緣設備到最大的數據中心 , 提供了無與倫比的靈活性和性能 。
*聲明:本文系原作者創作 。 文章內容系其個人觀點 , 我方轉載僅為分享與討論 , 不代表我方贊成或認同 , 如有異議 , 請聯系后臺 。
想要獲取半導體產業的前沿洞見、技術速遞、趨勢解析 , 關注我們!
推薦閱讀













- 紅米15C正式發布:6000mAh+50MP雙攝,新一代百元神機
- 佳能C50視頻機與85mm F1.4L VCM鏡頭將一起發布
- 魅族新一代旗艦機官宣:9月15日,正式發布
- 蘋果新品官宣:9月10日,全新發布
- iPhone17系列發布前瞻:外觀、內存、價格、開售時間,全解析!
- 售價799元!2K+200Hz高刷屏,REDMI顯示器G27Q 2026發布
- 全網都在玩的生圖模型,我用它把 iPhone 17 提前發布了
- 誰才是耳機之王?索尼蘋果BOSE拿走一半市場,華為沖到第二
- OPPO 美女產品經理 Monica 宣布離職 曾因發布會“高跟鞋踩機”引關注
- 事關5G、人工智能等今日上午將舉行發布會