
文章圖片

文章圖片

文章圖片

文章圖片
文章圖片
文章圖片

文章圖片

文章圖片

文章圖片
文章圖片

文章圖片
文章圖片
文章圖片
文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片
2025年9月底 , 當絕大多數朋友正翹首以盼十一長假時 , 我們三易生活卻在前往一個許多PC發燒友夢寐以求的地方 , 去參加我們有史以來“技術含量”最高的一次新品體驗活動 。
是的 , 這次我們參加了2025 Intel Tech Tour 。 在此次的“技術之旅”中 , 我們不僅近距離參觀了這家芯片巨頭位于鳳凰城最新的晶圓廠 , 還提前獲知了大量關于他們最新消費級與企業級新品的細節信息 。
不過由于這趟旅途的“信息量”實在是太大 , 所以我們也不得不花了好些時間 , 才趕在國慶假期將其整理成文、以饗諸君 。
首先 , 我們需要先來上個關于制程的歷史課
提到英特爾的半導體制程技術 , 不知道大家首先會想到什么?
可能很多朋友會想到英特爾前幾年使用的14nm、14nm+、14nm++等制程工藝 , 但可能很多人不知道的是 , 在這組看似“裹足不前”的數字背后 , 實際上體現出的反而正是那段時間英特爾的“良心” 。
簡單來說 , 其實整個半導體行業(不只是英特爾)在20nm到16/14nm階段時 , 都面臨著“晶體管密度難以繼續大幅度改進”的問題 。 但當時有一部分企業想出了個“好辦法” , 那就是只對實際工藝做很小幅度的提升 , 卻為其賦予一個看起來進步很大的“數字” 。
比如 , 當時一些廠商會將改進的20nm制程“稱作”16nm、甚至14nm , 同時將其進一步改進的版本再叫做12nm、11nm 。 當這種把戲越玩越多之后 , 對于他們來說 , “制程”這個數字實際上就已經與真正的工藝、晶體管密度并不掛鉤了 。
可問題在于 , 當時的英特爾并不贊同這種做法 。 于是當其他的競爭對手們拿著30MTr/mm2(3000萬晶體管每平方毫米)的制程 , 就敢叫“14nm”、甚至“12nm”時 , 英特爾44.67MTr/mm2的“真14nm” , 反而成為了在市場宣傳上吃虧的那一個 。
正因如此 , 當時間來到2021年 , 英特爾首次打破常規 , 將旗下的改進版10nm工藝(嚴格來說算是10nm++)“重命名”為Intel 7 , 算是被迫迎合了半導體行業的主流宣發策略 。
但即便如此 , 英特爾依然保留了一些“矜持” 。 比如他們的Intel 7、Intel 4工藝 , 在命名上都不會加“nm”這個單位 , 且英特爾在這些“等效數字”的選擇上也從未有過夸大 。 例如“Intel 7”的晶體管密度就高達100MTr/mm2 , 確實完全等同于其他家的“7nm”工藝水平 。
“18A”降臨 , 英特爾的半導體技術終于要反殺了
雖然英特爾至今仍保有在制程命名上的“矜持” , 但從產品信息來看 , 至少在目前在售的酷睿Ultra 100系、200系消費級處理器產品線上 , 他們大量使用了來自第三方的制程工藝 。 這確實也在客觀上表明 , 英特爾此前在頂級先進制程方面 , 依然存在性能或產能等方面的信心不足 。
好在 , 英特爾并沒有就此放棄 。 就在此次TechTour期間 , 我們就近距離接觸到了英特爾即將推向市場的18A工藝 , 以及首批基于這一工藝打造的全新處理器產品線 。
其實關于“18A”這個命名 , 我們甚至向英特爾方面提出過疑問 。 因為盡管專業人士可能知道 , “18A”里的“A”指的是“埃斯特朗(?ngstr?m)” , 即1A=0.1nm 。 但它一方面不是個國際制單位 , 知道的人本來就少 。 所以對于完全不接觸晶體學或光譜學的大多數人而言 , 這個命名很可能反而會產生“它比3nm、2nm的數字要大、因此是老舊制程”的錯誤認知 。
而且從另一方面來說 , “A”(注意不叫“埃米” , 那是訛稱)這個后綴的出現 , 也相當于打破了英特爾此前“Intel 7”、“Intel 4”等制程不加長度單位后綴的“自我規制” 。
“18A”里的“A”本身就是個長度單位 , 所以不可寫成“Am”或者“埃米”
那么英特爾為什么會突然如此高調起來呢?原因其實很簡單 , 因為18A制程真的很特別 , 也絕對足夠強 。
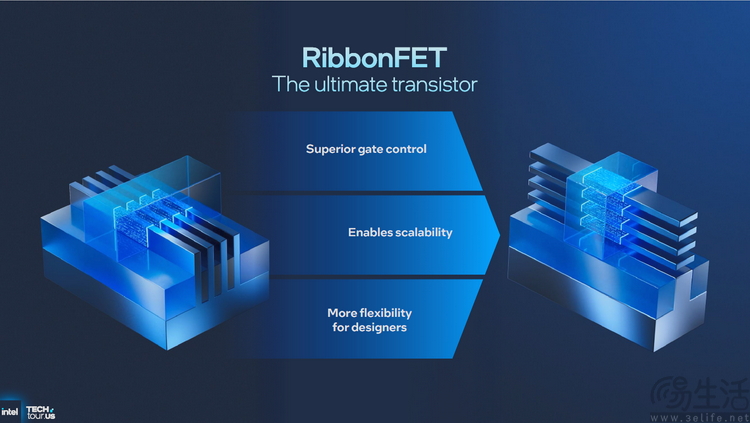
我們先來看18A制程兩大最核心的技術亮點 , 也就是RibbonFET晶體管結構以及PowerVia背面供電設計 。
首先是RibbonFET , 這其實就是英特爾版本的GAA(全環繞柵極) 。 眾所周知 , 英特爾是最早在量產產品中引入FinFET(鰭式場效應管)結構的廠商之一 。 但對于越來越精密、尺寸越來越小的半導體微結構來說 , FinFET對于導電通道的控制能力已經“不夠看”了 , GAA注定是整個先進半導體行業的未來 , 因為它可以顯著提升晶體管內部的電流控制能力 , 減少漏電、降低功耗 。
與此同時 , PowerVia則更可以說是英特爾的“獨門絕技” 。 這一技術的核心亮點 , 在于它將傳統晶體管上“混合布局”的供電和信號電路分離開來 , 將供電電路改到了晶體管的背部 。
這一供電設計就帶來了許多的好處 。 從制造層面來說 , 它讓18A工藝的制造工序相比于此前的Intel 3反而大幅簡化 , 降低了金屬層制造成本 。 從芯片本身的性能表現來看 , PowerVia可以將標準單元利用率提高約10% , 同時將芯片內部的電壓降減少30% , 大幅提高了芯片的穩定性和能源利用率 。
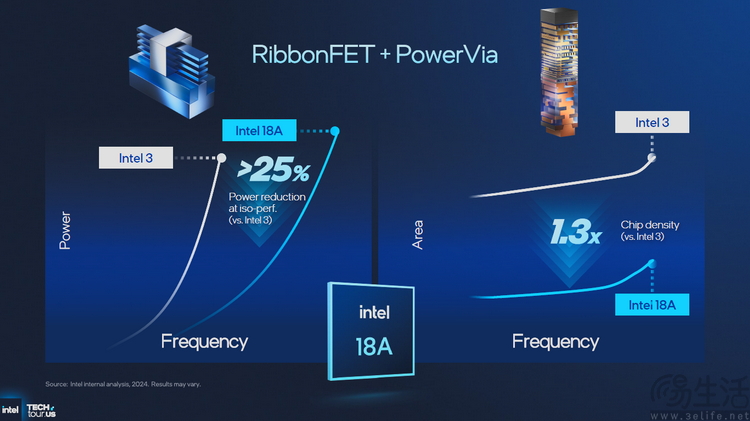
從整體結果來說 , 相比Intel 3工藝 , 在采用了RibbonFET和PowerVia兩大核心技術后 , Intel 18A的每瓦性能可以提高15% , 芯片密度增加了30% , 同時在達到相同等級性能前提下 , 采用18A工藝芯片的總功耗更是可以下降超過25% , 能效改進效果非常顯著 。
獨家復雜封裝方案 , 讓高性能芯片更小、還能更強
接下來 , 我們來聊聊英特爾在芯片封裝技術方面的一些最新動向 。
大家有關注過最近這幾年CPU市場的技術動向就會發現 , 現如今無論英特爾、還是AMD , 其實都沒有再去研發“一整塊”的大號CPU產品 。 大家做的都是模塊化設計 , 之后再通過先進封裝技術將其整合起來 , 形成“一顆”完整的解決方案 。
模塊化的設計有很多好處 , 比如可以降低CPU迭代的成本 , 允許CPU在更新換代時只更換其中的部分模組 , 同時沿用不那么重要的部分 。 同時 , 模塊化設計也大幅簡化了超多核CPU的構成方式 , 允許廠商大量復用“小核心”來組成一顆大尺寸的多核CPU , 而不太需要考慮原生超多核布局所帶來的走線困難 。
但是 , 模塊化設計也有局限性 。 比如在AMD的CPU上可以看到 , 他們是將多個小尺寸的計算核心和IO核心分開來布局在PCB上 , 以此所構成的超多核方案 。 這種設計的最大問題 , 就是跨模組之間過長的走線路徑會造成極其明顯的通訊延遲問題 。 以至于哪怕是在家用級的銳龍9處理器上 , 玩家們也往往不得不手動鎖定(游戲)線程在一顆模組內部 , 才能避免跨模組通信帶來的顯著性能降低 。 而且過于分散的模組互聯布局還會帶來隱性的功耗短板 , 從而降低CPU的整體能效 。 特別是對于企業級的超多核CPU服務器來說 ,由于CPU跨模組通信所帶來的額外功耗浪費 , 有時候便不能被忽視 。
正因如此 , 英特爾從很早就開始有意避免這種“簡單粗暴”的多核模組設計方案 。 取而代之的 , 是他們開發出了自家的Foveros系列多芯片互聯封裝設計 。
以英特爾下一代消費級CPU使用的Foveros-S 2.5D技術為例 , 它就是將多個小尺寸的芯片(Die)置于無源互聯層(Passive Base Die)之上 , 通過互聯層內部的走線來完成多核心互聯通信 。
與傳統的、基于PCB內部走線的互聯方案相比 , Foveros-S 2.5D封裝的焊點密度提高了16倍之多 , 同時單bit的通信功耗從0.5pJ(皮焦耳)降低到僅0.15pJ 。
當然 , 這還沒完 , 針對企業級的更大型處理器設計 , 英特爾還有更進一步的Foveros Direct 3D互聯 。 它的焊點密度更是可以達到傳統PCB上BGA焊接工藝的100倍之多 , 單bit傳輸功耗低至0.05pJ , 只有PCB多芯片互聯工藝1/10的功耗 。
而且Foveros Direct 3D封裝所使用的有源基板(Active Base Tile)并不只擔當“互聯層”的作用 , 它還可以在內部集成內存控制器、甚至是內含巨大的LLC(Last Level Cache)緩存 。 有沒有覺得有點眼熟?其實這就是傳聞中的英特爾版本“X3D”方案 。 只不過這個“X3D”同時具備了緩存、內存控制器、CPU核心互聯層的功用 , 可以說在客觀上就彰顯了英特爾在復雜封裝工藝上的大膽設計思路 。
黑豹湖搶先詳解:大小核全部換新 , CPU調度也重新設計
說完了新架構和新的封裝工藝 , 我們就該來看看英特爾具體的新款處理器細節了 。
首先登場的 , 是此前已經傳言了許久的Panther Lake(黑豹湖)產品線 。 這條產品線非常特別 , 因為它實際上要同時接班Lunar Lake和Arrow Lake-H這兩個不同定位的處理器家族 , 用英特爾方面自己的話來說 , 這就使得Panther Lake從一開始就需要同時具備Lunar Lake低功耗、超高能效比 , 以及Arrow Lake-H更多核心數、更多IO接口的全部優點 。
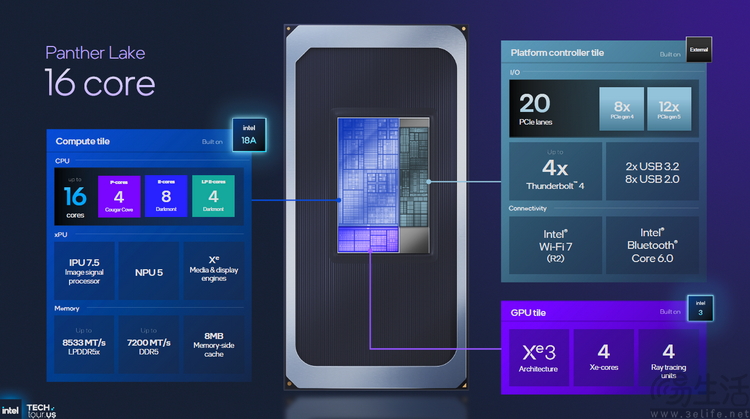
那么 , Panther Lake要如何實現這種“兼顧”式的設計呢?答案很簡單 , 因為它幾乎在所有的方面都使用了最新技術 。 其中包括英特爾18A制程的CPU Tile、全新的大小核架構、全新的Xe3核顯、全新的核心布局方式 , 以及全新的調度策略 。
先來看看Panther Lake的整個產品線布局 。 從目前英特爾方面公布的初步信息來看 , Panther Lake至少包含三個不同的版本 。
它們分別是8核心CPU+4核Xe3核顯的“基礎款” 。
以及16核心CPU+4核Xe3核顯 , 支持20條PCIe通道和傳統DDR5 SODIMM內存 , 明顯偏獨顯全能本的版本 。
還有16核心CPU+12核Xe3核顯 , 但PCIe通道更少、內存只支持LPDDR5X方案 , 明顯針對核顯高端輕薄本的版本 。
很顯然 , 英特爾這次是吸收了前代產品的不少教訓 。 其中 , 基礎款的8+4版本既可以用來做平價全能本、也能降低超輕薄/二合一設備的價格門檻;而16核CPU的兩個不同版本 , 則可分別作為高端Arrow Lake-H和Lunar Lake的“繼任者” 。
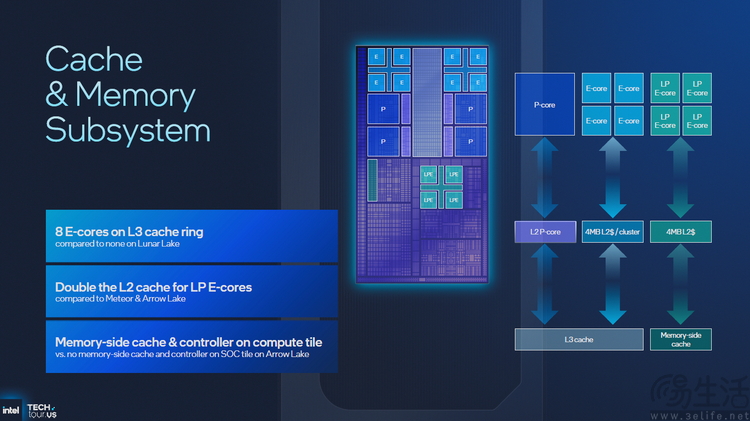
具體到CPU核心架構 , Panther Lake的“大小核”架構也久違地進行了全面更新 。 它的Cougar Cove P核此次配備18個執行窗口、具備1.5倍容量的TLB、更寬的隊列、改進的分支預測機制 , 新的內存消歧義技術 , 以及基于AI的電源管理功能 。
與此同時 , 新的Darkmont E核則延續了前代的3*3寬度解碼設計 , 主要在分支預測、動態預取、微碼性能 , 以及內存消歧義性能上進行了顯著改進 。 同時新的E核如今每四顆核心共享4MB的L2緩存 , 且緩存帶寬也被顯著增大 , 再加上4組128bit的浮點和向量單元 , 可以說是越來越有“P核化”的趨勢 。
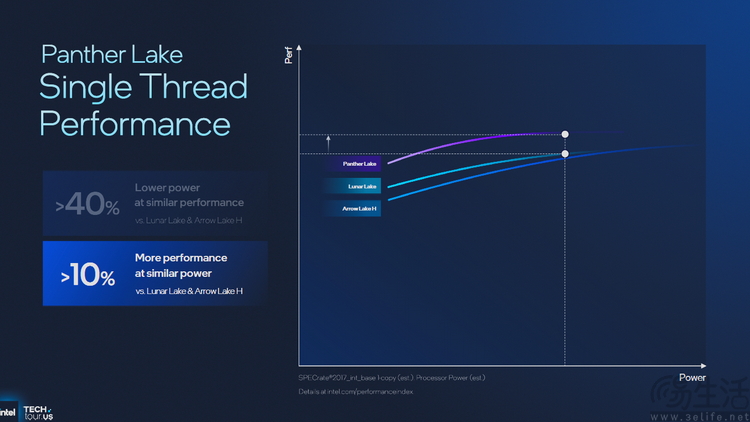
根據英特爾方面透露的信息 , Panther Lake只需過去不到60%的功耗 , 即可達到前代相同的單核性能水平 。 同時在相同功耗下 , 它的單核可以發揮出多10%的性能 。
同時與Lunar Lake相比 , Panther Lake在低功耗下的多核性能暴漲50% , 而與同為16核的ArrowLake相比 , 它在達到近似性能時的功耗則可以節約30%、甚至更多 。
而且在Panther Lake上 , 四顆LPE超低功耗核心的L2緩存被加倍 , 且它們不再位于SoC Tile , 而是被整合進了計算模塊 , 與四顆P核、八顆E核“靠”得更近 。 這四顆LPE核現在能夠訪問單獨的內存側緩存 , 相當于它們與其他核心之間的調度延遲被大幅降低 , 讓和四顆LPE核也等于變相擁有了自己的獨立“L3”緩存配置 。
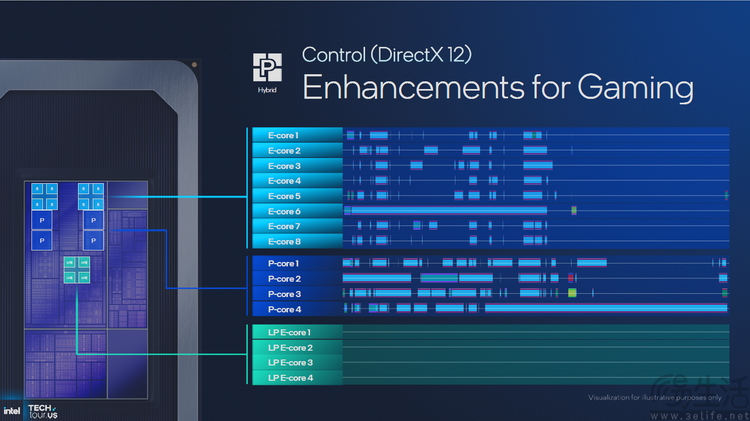
從結果來說 , 在Panther Lake上 , 英特爾現在可以讓四顆LPE核心開始承擔更多的日常任務 , 甚至是作為“最優先”被使用的CPU核心 。 按照他們的說法 , 在諸如視頻會議、彈幕視頻觀看這類場景 , Panther Lake CPU都可以做到幾乎不調度P核與E核 , 完全靠LPE核心以極低功耗就能“搞定” 。
如果涉及到諸如游戲這類對核間調度非常敏感的任務 , Panther Lake就會主動將大部分計算任務放到P核與E核上 , 進而起到提高性能、降低延遲的作用 。 至于視頻剪輯、AI編碼這種只追求多核性能、不要求延遲的計算場景 , Panther Lake的全部核心就都會被同時“激活” , 共同發揮最大的多線程性能 。
Xe3 GPU架構首秀:英特爾也有多幀生成了
接下來 , 我們來談談伴隨Panther Lake產品線首次公開亮相的Xe3 GPU架構 。
與Xe2相比 , Xe3的基本組成方式沒有太大的變化 , 其每個Xe核心內部依然包含8個512bit的向量引擎、8個2048bit的XMX引擎 , 但向量引擎的吞吐量增加了25% , 同時新增對FP8浮點的原生支持 。 此外 , 每個Xe核心的L1緩存也增加了1/3 。
在此基礎上 , Xe3架構對大量的固定功能單元都進行了增強 , 比如它具備兩倍的各向異性過濾速度、兩倍的模板測試速度 。 從結果來說 , 與Xe2架構相比 , Xe3的FP32吞吐量增加了50% , 16倍各向異性過濾速度提升100% , 網格渲染快了140% , 而深度寫入速度甚至達到了前代架構的7倍以上 。
根據英特爾方面公布的實測成績顯示 , Panther Lake上的12核Xe3核顯在具體的繪圖任務中 , 幾乎所有的幀生成流程耗時都僅為Lunar Lake上8核Xe2核顯的一半 。 而其最高性能 , 則可以比LunarLake上的Xe2足足提高50% 。
這還沒完 , 隨著Xe3 GPU架構的發布 , 英特爾也即將帶來XeSS 3功能套件 , 而它最重要的特性 , 就是基于XMX單元的XeSS-MFG(多幀生成) 。
按照目前官方透露的信息 , XeSS 3、或者說XeSS-MFG并不需要游戲做額外的適配 , 而且XeSS-MFG將會在顯卡驅動里提供開關 , 只要是能夠支持XeSS 2的游戲都將自動支持新的多幀生成功能 。 雖然XeSS 3會伴隨新GPU架構發布 , 但只要是內置XMX單元的舊款Xe GPU , 也都可以支持新的多幀生成功能 , 這其中甚至會包括初代的ARC A系列獨顯 。
從這個角度來說 , 之前購買了A770、B580這些英特爾獨顯的用戶 , 還真是將再度迎來美好的“戰未來”性能增強 。 有意思的是 , Panther Lake里目前集成的Xe3核顯并不會被歸于“ARC C”產品序列 , 它們依然屬于ARC B家族 。 而且英特爾方面也已經暗示 , 他們會發布更強大的“Xe 3P”架構 , 這似乎才會代表著英特爾獨顯的真正高端崛起 。
除了筆記本電腦處理器 , 還有最高288核心的至強6+
除了面向消費級的產品 , 此次活動中英特爾還展示了全新的、最高可達288核心至強處理器的一些技術細節 。
其實說到288核心至強 , 可能有些朋友首先會想到的 , 是此前代號為“Sierra Forest-AP”的第六代至強中、最高端的6900E產品線 。 但查詢公開信息就會發現 , 至強6 6900E系列實際上從未在公開市場發售 , 因為它采取了定制的方式銷售 , 也就是說只有少數大型企業才有能力與英特爾合作部署這一處理器 。 而“一般企業用戶”能夠買到的 , 僅有最多144核心的“Sierra Forest-SP”、即至強6 6700E家族 。
在這樣的背景下 , 能夠真正向廣泛用戶提供最高288核心的Clearwater Forest , 也就是此次亮相的“至強6+”處理器 , 自然就有理由得到更多的期待 。
那么至強6+有什么過人之處呢?簡單來說 , 它使用了與Panther Lake相同的Darkmont E核架構 , 但用上了非常大膽的模組化封裝技術 。 其CPU一共包含12顆Compute Tile , 每個Tile內部為6個CPU模組 , 每個模組包含四顆Drakmont核心 。 同時這12顆Compute Tile通過前面講到的Foveros Direct 3D封裝“疊放”在三組Active Base Tile上 , 從而獲得576MB的巨大垂直L3緩存 。
除此之外 , 至強6+還具備12通道DDR5 8000MT/s控制器、288MB的內部L2緩存 , 以及多達96條的PCIe 5.0通道 。
根據英特爾方面透露的信息 , 對比目前能夠買到的至強6700E系列 , 至強6+帶來了17%的IPC提升、5倍的L3緩存容量、1.8倍的內存帶寬 , 以及100%的核心數量增加 。
那么對于企業用戶來說這些意味著什么呢?英特爾方面舉了個例子 , 如果一家企業至今仍在使用第二代可擴展至強 , 那么升級到至強6+方案后 , 他們的服務器機架數量將可以減少到原來的1/8、節約71%的機房空間、獲得每瓦3.5倍的性能提升 , 同時減少大約750kW的能源消耗 。 很顯然 , 對于本就屬于高能耗行業的云計算、通訊核心網等場景來說 , 至強6+處理器的出現將有望帶來更加綠色、對企業來說也更省錢的運營助力 。
總結:統一架構和制程 , 英特爾要“重新開始”
不得不說 , 此次2025 Intel Tech Tour的信息量確實是過于巨大 , 所以我們先要感謝能耐心看完本文的讀者朋友!
那么 , 總結此次英特爾的新制程、新技術和新品內容 , 大家有發現什么規律嗎?很顯然 , 與過去幾年相比 , 這可能是英特爾久違地在消費級和企業級產品線上再次統一了制程與架構方案 。 也終結了過去幾年里 , 至強在架構上一直落后于酷睿處理器的情況 , 同時18A制程在新產品線里的廣泛使用 , 實際上也相當于英特爾在明示其對于自家新制程的足夠信心 。
在官方公布的信息里 , Darkmont似乎也被有意置于Cougar Cove的“身前”
當然 , 關于英特爾此次公布的新品 , 我們還可以有更多遐想 。 比如Darkmont核心進一步增大規模、且采用了4*128的SIMD構造 , 這就不得不讓人懷疑他們是否準備在E核上“復活”AVX-512計算能力 , 并將E核正式“扶上位”、成為主流技術路線 。 更不要說傳言了好幾年的“小核聚合變大核”設計 , 如今看來可能性還真就越來越大了 。
又比如在Panther Lake上 , 它所搭載的全新NPU5(50TOPs)方案 , 算力其實并未比之前的NPU4(48TOPs)有顯著提升 , 主要改進在于縮小了面積、提高了算力密度 。 而這 , 也可以視為英特爾或將推出更大規模(更多核心)NPU的“前奏” 。
【18A制程首秀、新架構井噴:2025 Intel Tech Tour解析】除此之外 , 英特爾方面在此次活動期間幾乎已經“明示”了新一代的ARC獨顯核心 。 這也就意味著 , 此前傳言的ARC B770 , 大概率是被取消了 , 取而代之的會是徹底換用新架構、新制程的ARC C系列家族 。 而后者到底會是怎樣的定位 , 是否能夠成功改變中端乃至中高端獨顯的市場局面 , 與未來的英特爾核顯又是否可以產生“聯動”效應 , 這無疑都是值得持續關注的話題 。
推薦閱讀













- 亞馬遜“盲眼”機器人30秒跑酷首秀驚艷!華人學者領銜
- 麒麟9030參數曝光,采用等效5nm制程工藝,性能追趕第三代驍龍8
- SK海力士啟動1c制程GDDR7量產計劃
- 榮耀Magic 8系列新動態:AI智能體YOYO首秀,mini版本疑似入網!
- 小米17最炫功能首秀,米粉瘋狂造梗,iPhone17瞬間變土老帽!
- 英特爾二代顯卡首秀筆記本:微軟Surface Laptop將嘗鮮
- 狂攬全球目光!追覓雙機械臂空調IFA首秀引行業轟動
- 無需構圖!影石8K全景無人機IFA首秀,讓人人都成航拍大師?
- 英特爾首席財務官:由于使用High NA EUV量產,14A將比18A更昂貴
- 小米16首秀,這外觀設計亮瞎眼!還買啥iPhone17?