文章圖片

文章圖片
文章圖片
文章圖片
2023年4月 , Meta AI發布了首個圖像分割基礎模型Segment Anything Model(SAM) 。
SAM的目標是讓計算機「能分割任何東西」 。
2024年7月 , Meta推出SAM 2 , 將模型擴展到視頻分割并顯著提升性能 。
如今 , SAM模型即將迎來第三次升級 。
ICLR 2026會議盲審論文《SAM3:用概念分割一切》https://openreview.net/pdf?id=r35clVtGzw
論文《SAM 3: Segment Anything with Concepts》 , 也許可以帶我們解鎖這次SAM新升級的內幕 。
該論文目前處于ICLR 2026會議盲審階段 , 作者暫未公布身份 , 但從題目中不難推測其內容為SAM第三代的升級 。
SAM3最大的突破在于它強調「基于概念的分割」 , 即不只是按像素或實例 , 而是可能按「語義概念」來理解和分割圖像:
只要給出一個提示 , 比如「黃色校車」或一張參考圖片 , SAM 3就能在不同場景里找到并分割出對應的物體 。
該功能被定義為可提示的概念分割(Promptable Concept Segmentation , PCS) 。
為了支撐PCS , 研究團隊還構建了一個可擴展的數據引擎 , 生成了涵蓋圖像與視頻的高質量數據集 , 包含約400萬個不同的概念標簽 。
將「概念分割」引入SAM架構SAM架構引入了「可提示分割」任務 , 可通過交互式提示分割圖像與視頻中的目標 。
然而 , 早期的SAM 1和SAM 2更側重視覺提示 , 并且每個提示僅分割單個對象實例 。
這無法解決更普遍的問題:在任意圖像或視頻中 , 自動找到所有屬于同一概念的對象 。
比如 , 你輸入「貓」 , 不僅是要找出一只貓 , 而是找出所有的貓 。 SAM 3正是為解決這一問題而推出的 。
它相比較前代模型 , 不僅改進了可提示視覺分割(PVS) , 還開創了新的標準——可提示概念分割(PCS) 。
PCS可以完成這樣的任務:
模型可以根據提示(文字或圖像) , 找出圖像或視頻中所有符合這個「概念」的對象 , 并保持每個對象的身份一致 。
比如輸入「紅蘋果」 , 模型會在不同幀中追蹤每一個紅蘋果 。
在實際使用中 , 用戶還能通過交互方式(比如添加更多提示)逐步細化結果 , 解決模糊或歧義情況 。
圖1對比展示了SAM 3與SAM 2的核心區別 , 說明了從「可提示視覺分割」(PVS)到「可提示概念分割」(PCS)的進化 。
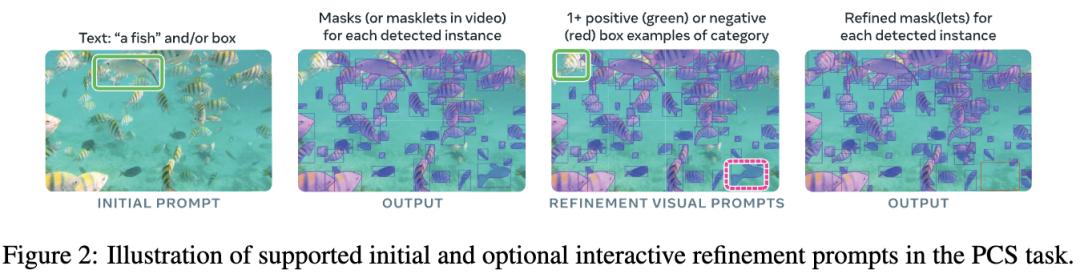
圖2中展示了SAM 3如何從「理解一個提示」到「交互式細化分割結果」的全過程 , 它體現了PCS任務的核心特征——可提示、可交互、可概念化 。
SAM 3系統實現了三大創新:
1. 更廣的媒體域:不局限于同質化網頁來源 , 涵蓋更豐富的圖像和視頻場景;
2. 智能標簽生成:使用多模態大模型(MLLM)作為「AI標注員」 , 生成更多樣且有挑戰性的概念標簽;
3. 標簽驗證:通過微調MLLM使其成為高效的「AI驗證員」 , 達到接近人類的表現 , 從而將標注吞吐量翻倍 。
研究團隊構建了一個包含400萬唯一短語與5200萬掩碼的高質量訓練數據集 , 以及一個包含3800萬短語與14億掩碼的合成數據集 , 還推出了一個新的測試標準SA-Co基準 。
實驗結果顯示 , SAM 3在可提示分割上建立新SOTA , 例如在LVIS數據集上 , SAM 3的零樣本分割準確度達到47.0(此前最佳為38.5) 。
在SA-Co基準上表現提升至少2倍 , 并在PVS基準上優于SAM 2 。
在一張H200GPU上 , SAM 3只需30毫秒就能在單張圖中識別上百個對象 , 視頻場景中也能保持接近實時的處理速度 。
可提示概念分割(PCS)研究人員將PCS定義為如下任務:
給定一張圖片或一段不超過30秒的視頻 , 讓模型根據一個概念提示(可以是文字、示例圖像 , 或兩者結合) , 去檢測、分割并跟蹤所有符合該概念的對象 。
這些「概念」一般是由簡單名詞短語(noun phrase , NP)組成的 , 包含一個名詞和可選修飾語 , 比如「紅蘋果」或「條紋貓」 。
文字提示會對整張圖片或整段視頻都生效 , 而圖像示例(例如框選某個目標)則可以用于細化結果 , 幫助模型更精確地理解「我說的就是這個」 。
PCS的一個難點在于我們面對的「概念」范圍幾乎無限 , 這帶來了很多歧義性 。
這些歧義即使在封閉類別(如LVIS數據集)中也存在 。
SAM3采取以下措施應對歧義:
多專家標注:每個測試樣本由三位獨立專家標注 , 確保結果更客觀;
評估協議優化:評估時允許多種「合理答案」共存;
標注規范與數據清洗:在數據收集和指南中盡量減少歧義;
模型層面處理:在SAM 3中設計了專門的「歧義模塊」 , 幫助模型理解并容忍這些模糊邊界 。
讓分割模型能夠理解「概念」 同時還要看得見、記得住SAM 3是對前一代SAM 2的拓展與泛化 。
它同時支持兩類任務:
可提示視覺分割(PVS):根據幾何或視覺提示(點、框、掩碼)圈出指定物體;
可提示概念分割(PCS):根據概念提示(簡短的文字或示例圖像)識別并分割所有符合該概念的目標 。
換句話說 , SAM 3既能理解「我點的這個東西」 , 也能理解「我說的這個概念」 。
下圖3中展示了SAM 3架構 , 由一個雙編碼器-解碼器Transformer組成:
檢測器(Detector):負責在圖像級別檢測并分割目標;
跟蹤器(Tracker):跟蹤器繼承了SAM 2的Transformer架構 , 負責在視頻中跟蹤已檢測的目標 。
檢測器和跟蹤器分開運作 , 檢測器只管發現目標 , 跟蹤器才關注它們的身份 , 為了避免以上兩種任務相互干擾 , SAM 3引入了一個新的「存在性Token」 , 將識別與定位解耦 。
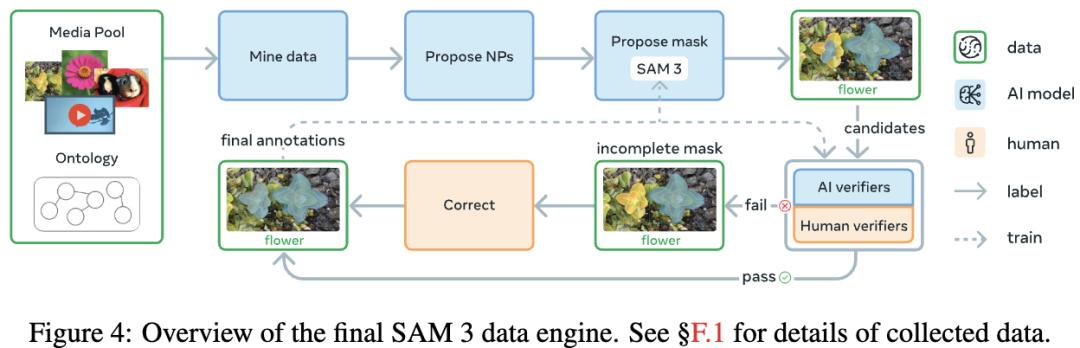
人機協同的數據引擎 讓模型實現「概念分割」能力為了讓SAM 3在可提示概念分割(PCS)上實現跨越式提升 , 它必須在更廣泛的概念范圍和更多樣的視覺數據上進行訓練 。
為此 , 研究團隊構建了一個高效的數據引擎 , 讓人類標注員、AI標注員和SAM 3模型本身組成一個閉環系統 , 推動模型不斷從自己的失敗案例中學習 。
通過這種方式 , AI在一些標注環節上已經能達到甚至超過人類的準確度 , 使得整個數據生成效率提升了約一倍 。
研究人員將數據引擎的建設分為四個階段:
第1–3階段僅針對圖像 , 第4階段擴展至視頻 。
階段1:人類驗證 。
初期階段完全依靠人類驗證 。
研究者使用隨機圖像和簡單文本描述器生成概念短語 , 掩碼由SAM2與開放詞匯檢測器提供 。
階段2:人類+AI驗證 。
利用第一階段積累的人類標簽 , 團隊微調Llama 3.2模型 , 讓它學會自動執行MV與EV驗證 。
【ICLR神秘論文曝光,SAM3用「概念」看世界,重構視覺AI新范式】AI驗證員可以直接判斷「這個掩碼對不對、全不全」 , 從而把人力解放出來 , 專注于最棘手的樣本 。
此時 , AI已能自動發現對模型具有挑戰性的「困難負樣本」 。
階段3:擴展視覺領域
第三階段把數據覆蓋擴展到15個不同視覺域(例如自然場景、工業、藝術等) 。
通過從alt-text(圖像描述文本)和基于Wikidata的本體庫(約2240萬個概念節點)中提取新短語 , 系統進一步補充了長尾類與細粒度類別 。
階段4:視頻標注
將數據引擎擴展至視頻 。
使用成熟的SAM 3模型 , 研究人員在運動、遮擋、跟蹤失敗等復雜場景中采集高質量標注 , 最終構建了SA-Co/VIDEO數據集 , 包含5.25萬視頻、2.48萬唯一短語 , 總計13.4萬視頻-短語對 。
這部分主要聚焦于模型容易出錯的擁擠場景 , 以最大化學習效果 。
SA-Co數據集
數據引擎最終生成了多層級的SA-Co數據集家族:
SA-Co/HQ:高質量人工與AI協作圖像數據 , 包含520萬張圖像、400萬個唯一短語;
SA-Co/SYN:全自動生成的合成數據;
SA-Co/EXT:整合15個外部數據集并補充困難負樣本;
SA-Co/VIDEO:視頻級標注數據集 。
這些數據構成了目前世界上最大規模的開放詞匯分割數據集體系 。
為衡量模型在真實應用中的表現 , 研究人員設計了SA-Co基準(Benchmark) , 涵蓋圖像與視頻共12.6萬個樣本、21.4萬唯一短語 , 包含超過300萬條標注 。
經過研究人員評估 , 在圖像和視頻分割、少樣本檢測與多模態語言配合任務上 , SAM 3全面超越現有系統 , 它在SA-Co的圖像與視頻PCS上將性能提升到以往系統的兩倍 。
與前代模型相比 , SAM 3不再只是一個只會「按圖索驥」的工具 , 而是逐步演變成一個能理解概念、識別類別、保持語義一致性的智能視覺系統 。
它將圖像分割從「點選式」操作提升到「概念級」理解 , 為下一代智能視覺和多模態系統奠定了基礎 。
也許 , 視覺AI的「GPT-3時刻」真的已經不遠了 。
參考資料:
https://openreview.net/forum?id=r35clVtGzw%20
https://openreview.net/pdf?id=r35clVtGzw
本文來自微信公眾號“新智元” , 作者:新智元 , 編輯:元宇 , 36氪經授權發布 。
推薦閱讀













- 剛剛,Meta風雨飄搖中發了篇重量級論文,作者幾乎全是華人
- 斯坦福新論文:微調已死,自主上下文當立
- 蘋果再發論文:精準定位LLM幻覺,GPT-5、o3都辦不到
- 揭秘全球唯一黃金版RTX 5090D!6公斤黃金 神秘大佬買走
- 備受Meta折磨,LeCun依舊猛發論文!新作:JEPAs能感知數據密度
- 神秘中國特供!AMD確認新款專業顯卡Radeon PRO W7900D
- 谷歌Veo 3論文竟無一作者來自美國!揭秘零樣本「看懂」世界
- GPT-5攻克量子NP難題,首篇論文引爆學界!人類2周壓縮至30分鐘
- “零人”搞醫學研究:清華AI智能體從靈感到論文全程自主
- 龐若鳴還有蘋果論文?改善預訓練高質量數據枯竭困境