
文章圖片
文章圖片
文章圖片
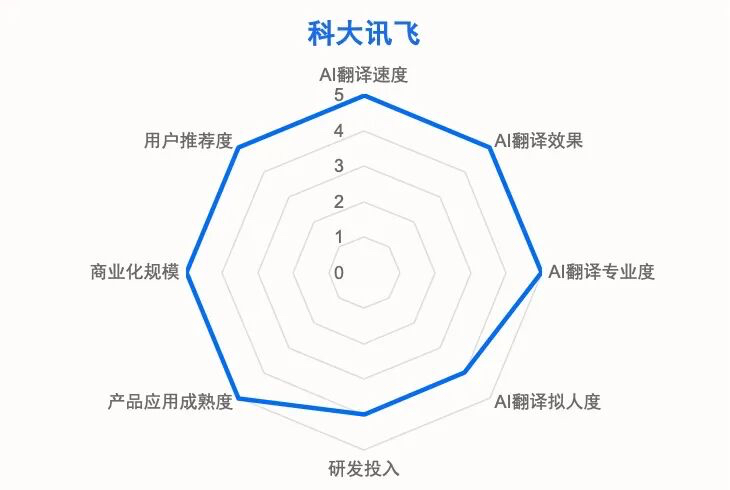
2025 年 10 月 , 國際數據公司(International Data Corporation , IDC)發布了《中國 AI 翻譯技術評估》報告 。 這份以“大模型驅動 AI 翻譯能力全面換新”為主題的報告指出 , 大模型技術的全面滲透正在深刻重塑 AI 翻譯市場 。 通過對主流 AI 翻譯產品的全方位測評 , 報告發現:科大訊飛在翻譯速度、效果、專業度、擬人度、研發投入、產品成熟度、商業化規模、用戶推薦度八個核心維度上均排名第一 , 而騰訊、字節跳動等互聯網企業推出的翻譯大模型、同傳大模型在基礎場景中同樣展現出不俗的能力 。
這場由大模型引發的技術革命 , 不僅提升了翻譯質量的上限 , 更在徹底改寫行業競爭規則 。 當大模型技術讓 AI 翻譯的技術門檻在某種程度上被降低時 , 一個新的問題浮現:什么才是 AI 翻譯產品真正的核心競爭力?
大模型重構 AI 翻譯的底層邏輯
2015 年到 2025 年 , AI 翻譯經歷了從經典機器學習到深度學習 , 再到大模型驅動的三次技術躍遷 。 IDC 在報告中清晰勾勒出這條路徑:2015 年前后 , AI 翻譯停留在“打標簽、設規則”階段;2020 年前后 , 深度學習帶來了越來越實時的語音翻譯;而到了 2025 年 , 大模型和端到端技術讓 AI 翻譯達到了“比肩人類的高擬人度實時翻譯水平” 。
(來源:IDC)
這是一場根本性的質變 。 傳統級聯翻譯方案 , 將語音翻譯拆解為語音識別(ASR)、機器翻譯(MT)和語音合成(TTS)三個獨立模塊串聯 。 每個模塊獨立訓練、獨立優化 , 追求局部最優而非全局最優 。 更嚴重的是 , 一旦某個模塊出錯 , 誤差會在后續環節被疊加放大 。
端到端同傳技術徹底改變了這個架構 。 它使用統一的大模型完成全部任務 , 直接以最終翻譯質量——準確性、流暢性、自然度——作為優化目標 , 自動學習如何在各環節間權衡協調 , 實現全局最優 。
IDC 的測評驗證了這個判斷 。 在涵蓋七大場景、總長 5 萬字的文本翻譯測試 , 以及總時長 60 小時的同傳測試中 , 采用大模型技術的產品在多個維度實現了明顯躍升 。 報告從四個維度描述這種提升:更快——AI 翻譯不必再等待 , 可在 1 到 2 秒內給出翻譯結果;更準確——在各種使用場景下準確率已高度可用;更友好——一個設備解決各種翻譯需求;更自然——更高擬人度 , 多語言自然切換 , 支持圖片、視頻等多模態翻譯 。
(來源:IDC)
這種能力的提升是全行業性的 , 是技術范式革命帶來的普遍紅利 。 大模型技術將整個 AI 翻譯行業的能力基線提升到了前所未有的高度 。 然而 , 當所有參賽者的起跑線都被前移 , 競爭的焦點也隨之轉移——當“快”和“準”逐漸成為新常態 , 真正的差異化優勢體現在哪里?
IDC 評測揭示:AI 翻譯競爭的三重分水嶺
IDC 報告中 , 科大訊飛在八個核心維度的全面領先 , 恰好為“差異化優勢”提供了具象化答案 。 這份領先 , 源于其在技術、數據、產品三大關鍵維度的深層積累 。
(來源:IDC)
第一重分水嶺:算法架構的代際差異
端到端技術相比傳統級聯架構的優勢已經得到驗證 , 行業主流廠商均已轉向大模型路線 , 拿到了進入新賽場的“入場券” 。 然而 , 這僅僅是開始 。 真正的分水嶺在于 , 同樣是端到端大模型 , 其實現的深度和迭代的速度卻存在顯著差異 , 而這 , 也正是產品體驗能否從“能用”提升至“好用”的關鍵 。
端到端方案的優勢在于能夠實現全局優化 。 在級聯方案中 , 即使三個模塊各自達到局部最優 , 疊加起來也未必是全局最優 , 而且一旦某個環節出錯 , 會影響最終效果 。 早在 2025 年 1 月 , 科大訊飛就發布了國內首個端到端語音同傳大模型 , 其技術方案結合人工口譯的思維鏈路 , 設計了端到端的同聲傳譯思維鏈 , 使用統一的大模型進行流式語音識別、流式意群切分、語境理解及信息重組、流式語音合成 , 并通過對人工口譯數據的強化學習 , 實現翻譯速度和質量的平衡 。
這種技術路徑的有效性也反映在用戶體驗評分上 , 據了解 , 該模型的主觀體驗評分為 4.6 分(滿分 5 分) 。
同時 , 得益于領先的布局和深厚的技術積累 , 科大訊飛也展示了較快的迭代速度 。 從 2025 年 1 月首次發布端到端語音同傳大模型 , 到 10 月的第三次技術躍升 , 其在 9 個月內完成了三次重大技術迭代 。 根據公開信息 , 最新版本的中英同傳首字響應時間從 5 秒縮減至 2 秒 , 翻譯綜合質量較首發版本提升 20% , 覆蓋的垂直領域專業詞匯超過 10 萬個 。
這種快速迭代能力的背后 , 是在語音及語言技術領域的長期積累 。 基于星火大模型底座 , 科大訊飛構建的星火語音大模型支持 101 個語言的語音識別、全國 288 個地市的 202 種方言識別 , 以及 55 個語言的語音合成 。 這些在語音識別、語音合成等核心技術上的突破 , 為端到端同傳大模型提供了堅實的技術基礎 。
第二重分水嶺:垂直場景數據壁壘
通用大模型雖然在互聯網數據上訓練得很好 , 但 AI 翻譯需要的是高質量的垂直場景數據 。 IDC 在這次測評中專門設置了醫療、法律、科技等專業場景的測試 , 結果顯示:當對話涉及專業術語、行業語境時 , 翻譯產品的表現開始出現明顯分化 。
在醫療場景 , 一個“chronic pharyngitis”(慢性咽炎)的準確翻譯 , 關系到患者能否理解病情;在法律場景 , “liquidated damages”究竟應譯為“違約金”(補償性)還是“違約罰款”(懲罰性) , 這種細微差異可能導致合同理解的重大偏差;在科技文檔的翻譯中 , “tight hardware-software coupling closed ecosystems”(軟硬強耦合、封閉生態)這樣的復合概念 , 需要翻譯系統完整理解技術語境 , 才能準確傳達 。
IDC 的測評數據表明 , 在這些專業場景下 , 不同產品在翻譯準確性上的差距被明顯拉開 。 這背后 , 正是對垂直領域的深度理解能力 , 而這種能力的根基 , 本質上是一場數據積累的競爭 。
科大訊飛的優勢便建立在海量且真實的行業應用數據之上 。 其翻譯機服務超百萬用戶、翻譯次數高達 10 億次;訊飛同傳則服務全球 50 余個國家、支持超過 42 萬場會議 。 這些從真實使用場景中源源不斷產生的數據 , 包含了通用訓練數據難以替代的寶貴信息:例如特定行業的專業術語用法、復雜聲學環境下的語音特征 , 以及多語種自然切換的真實模式 。
基于這些數據資產 , 科大訊飛采取了一種“通用大模型+行業深度優化”的路徑 。 一方面 , 它通過與金融、汽車、法律、科技文獻等行業的龍頭企業合作 , 陸續發布了 20 多個行業大模型 , 覆蓋 300 多個應用場景 , 將知識深度融入特定場景 。 另一方面 , 它構建了覆蓋超過 10 萬個垂直領域專業詞匯的術語庫 , 為翻譯的精準度提供了保障 。
這種策略的成效 , 最終體現在了測評結果上 。 IDC 的數據顯示 , 科大訊飛在專業領域的翻譯準確性上明顯高于市場平均水平 , 其整體翻譯準確率高于 98% , 尤其在日常交流以及法律、醫療等專業場景中表現突出 , 從而在這場分化中構筑起堅實的數據壁壘 。
第三重分水嶺:從算法到產品的工程能力
大模型解決了“能不能翻譯”的問題 , 而工程能力決定了“能不能穩定、好用地翻譯” 。 IDC 報告特別指出了一個關鍵差異:部分翻譯服務是“逐句翻譯” , 而成熟產品能實現“長時流暢翻譯” 。 這看似簡單的差別 , 背后是復雜的工程挑戰 。 以端到端同傳為例 , 雖然技術原理已經明確 , 但要讓它在實際產品中穩定工作 , 需要解決聲學前端處理、流式識別、實時意群切分、動態上下文管理、語音合成等多個環節的精確協同 。 每個環節的延遲都需要優化到毫秒級 , 任何一個模塊的不穩定都可能導致整體體驗的崩潰 。 科大訊飛通過多年的工程實踐 , 建立了從模型訓練、系統集成、性能優化到產品測試的完整工程體系 。
工程化能力的另一個體現是對復雜場景的適配 。 IDC 的測評顯示 , 在相對安靜的環境中 , 多數 AI 翻譯產品都能達到較高的準確率 , 但在嘈雜環境下 , 不同產品的表現差異明顯 。 科大訊飛通過強大的聲學降噪算法 , 讓翻譯效果受外界環境的影響相對較小 。 這種看似小的技術細節 , 在實際使用中卻會帶來大的體驗差異 。
工程能力的最終價值 , 是轉化為全場景的產品力 。 IDC 報告認為 , 科大訊飛構建了業內最完整的 AI 翻譯產品矩陣——包括訊飛翻譯機、訊飛 AI 翻譯耳機、訊飛 AI 錄音筆等智能硬件 , 以及訊飛翻譯 APP、訊飛翻譯 SaaS 平臺、訊飛同傳等軟件服務 。 這種“軟硬一體、多端協同”的產品布局 , 讓科大訊飛能夠覆蓋從個人消費到企業服務、從便攜設備到專業會議的全場景需求 , 也使得技術優勢能夠快速轉化為可交付的產品價值 。
這個產品矩陣背后 , 這個橫跨個人消費者與企業用戶的龐大基數 , 構成了一個強大且實時的反饋循環系統 。 當數百萬用戶在不同場景下使用產品時 , 他們遇到的問題、提出的需求 , 都會成為產品優化的方向 。
基于這些真實場景的反饋 , 科大訊飛保持著持續的產品迭代 。 多語言切換的響應速度、嘈雜環境下的識別穩定性、專業術語的翻譯準確度——這些看似細微的體驗改進 , 往往來自用戶在實際使用中遇到的具體問題 。
這種基于大規模用戶反饋的持續優化能力 , 或許正是 IDC 用戶推薦度調查中科大訊飛位居前列的原因之一 。 在技術快速迭代的今天 , 產品能否跟上用戶需求的變化 , 決定了用戶體驗能否保持競爭力 。
AI 翻譯的下一個十年:從工具到伙伴
IDC 的這份報告 , 不僅是對當前 AI 翻譯技術的全面摸底 , 更為行業未來發展提供了重要洞察 。 報告指出 , 翻譯大模型將不斷成熟 , 越來越多的語音大模型、同傳大模型走向市?。 蛔既范冉嬲锏餃死嗨?, 同時擬人度不斷提升;翻譯將向行業縱深滲透 , 在醫療、法律、金融等專業領域廣泛應用;下一代 AI 翻譯硬件有望成為個人隨時攜帶的超級助理 。
在這個趨勢下 , AI 翻譯正在經歷一場深刻的角色轉變——從“工具”到“伙伴” 。 過去的 AI 翻譯是一個冷冰冰的對話框 , 你輸入一句話 , 它輸出一個翻譯結果 。 而未來的 AI 翻譯 , 將能夠理解對話背景、感知情緒變化、進行自然交互 , 成為真正意義上的溝通伙伴 。
科大訊飛在大模型和深厚語音技術的雙重加持下 , 正在這場變革中發揮引領作用 。 它的實踐證明:在大模型時代 , 真正的競爭優勢不僅來自算法的先進性 , 更來自將技術深度融入場景、轉化為用戶可以真實感知的可靠產品力的能力 。 只有這樣 , 才能在新的競爭格局中占據主動 。
展望未來 , AI 翻譯正在成為全球化時代不可或缺的新基建 。 無論是個人的跨文化交流 , 還是企業的國際業務拓展 , 都離不開高質量的翻譯服務 。 在這個意義上 , AI 翻譯行業的進步 , 不僅是技術的勝利 , 更是推動人類高效交流與深度融合的重要力量 。 這場由大模型驅動的變革才剛剛開始 , 它將如何塑造我們未來的溝通方式 , 值得持續關注 。
參考資料:
【解讀IDC中國AI翻譯評估:大模型帶來技術平權,新的分水嶺在哪?】1.https://my.idc.com/getdoc.jsp?containerId=CHC53836225
推薦閱讀












- vivo X300系列今日開售!黃金尺寸、護眼屏、治愈配色深度解讀
- 用戶從尼泊爾回國手機“被保護性關停” 中國移動新疆公司致歉并解釋原因
- 中國拿下41%全球電信設備份額,華為第一!通信技術,正在改寫國運
- AI圈再顛覆!中國AI翻譯耳機通話翻譯,實測震撼
- IDC:2025年上半年中國超融合市場、中國全棧超融合市場 深信服雙第一
- 中國移動已投資昆侖芯
- ATG,中國移動還有機會嗎?
- 全球手機市場回暖,vivo中國份額第一,傳音成最大黑馬!
- 美中AI競爭升級:美國巨額交易對戰中國開源策略
- 僅蘋果實現增長!2025年Q3中國大陸智能手機市場份額出爐