
文章圖片
文章圖片
本工作來自北京大學智能學院賀笛老師課題組與螞蟻集團武威團隊 。 賀笛老師在機器學習領域獲得過多項榮譽 , 包括 ICLR 2023 杰出論文獎與 ICLR 2024 杰出論文獎提名 。
擴散模型近年來在圖像生成領域取得了令人矚目的成就 , 其生成圖像的質量和多樣性令人驚嘆 。 這自然引發了人們的思考:這種強大的生成范式能否遷移到文本領域 , 挑戰甚至取代目前主流的自回歸語言模型?擴散語言模型(Diffusion Language Models)憑借其并行生成多個詞元的潛力 , 似乎預示著文本生成領域的一場效率革命 。 然而 , 這一前景是否真的如此美好?來自北京大學和螞蟻集團的最新研究表明 , 答案遠非簡單的 “是” 或 “否” , 在某些關鍵場景下 , 結論甚至可能恰恰相反 。
- 論文標題:Theoretical Benefit and Limitation of Diffusion Language Model
- 論文鏈接:https://arxiv.org/pdf/2502.09622
擴散模型 vs. 自回歸:效率神話面臨拷問
自回歸模型 , 作為語言生成領域的主流范式 , 以其逐詞元(token-by-token)的順序生成方式著稱 。 盡管在生成質量上取得了巨大成功 , 但其固有的串行機制限制了推理速度 , 尤其是在處理長序列時 。 與之相對 , 擴散語言模型 , 特別是其中的掩碼擴散模型(Masked Diffusion Models MDMs) , 允許在每個擴散步驟中并行采樣多個詞元 , 這從理論上為提升生成效率提供了可能 。
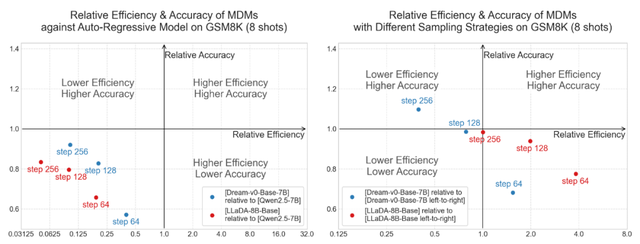
然而 , 理論上的優勢在實踐中似乎遭遇了 “效率悖論” 。 研究人員觀察到 , 目前開源的擴散語言模型在某些任務上需要更多的采樣步驟才能達到與自回歸模型相當的準確率 , 導致了比自回歸模型更高的推理成本 。 這一悖論在實驗中得到了印證 。 下圖直觀展示了這一現象:在數學推理基準測試 GSM8K(8-shot)上 , 當與同等規模的自回歸模型 Qwen2.5-7B 對比時 , 兩款最近發布的大型掩碼擴散模型 Dream-v0-7B 和 LLaDA-8B , 在不同的采樣步數下 , 其性能和效率均落后于自回歸基線 , 處于左圖中的第三象限(代表更低效率和更低性能) 。
鑒于不同模型可能使用了不同的訓練數據 , 研究人員意識到這可能對性能評估造成天然偏差 。 為消除該因素帶來的影響 , 團隊設計了更加客觀、公平的對比實驗:給定一個預訓練好的擴散語言模型 , 我們強制約束其在推理中采用從左到右的逐詞生成方式 , 并以這種\"偽自回歸式\"的解碼性能與效率作為基線 , 重新進行對比分析 。 理論上 , 在消除訓練數據差異的前提下 , 相對這種偽自回歸式的解碼方式 , 擴散語言模型理應在效率與性能之間取得更優平衡 , 表現應進入第一象限 。 然而 , 實驗結果卻出人意料 —— 即使與這種被約束的模型對比 , 擴散語言模型仍未展現出任何優勢 , 未能同時實現更高的生成效率與更優的輸出質量 。
圖 1:MDMs 在 GSM8K (8-shot) 上的效率和準確率 。 (左) MDMs 相對于 Qwen2.5-7B 的表現 。 (右) MDMs 相對于其自身自回歸式解碼的表現 。
這些觀察結果引出了一個核心問題:“離散擴散模型是否真的能提供比自回歸模型更好的權衡 , 即在保持高質量生成內容的同時實現更高的效率?” 這正是這項新研究試圖解答的關鍵 。
北大團隊新研究:撥開迷霧 , 關鍵在評估指標
針對上述疑問 , 研究團隊對此進行了深入的理論剖析 。 他們的研究目標是 “對一種廣泛采用的變體 —— 掩碼擴散模型(MDM)進行嚴格的理論分析” , 以探究觀測到的效率限制是否是其固有的缺陷 。
這項研究的核心結論是 , 關于擴散模型與自回歸模型優劣的 “結論高度依賴于評估指標的選擇” 。 研究團隊采用了兩種互補的評估指標來全面衡量 MDM 的性能:
詞元錯誤率(TER):該指標量化了詞元級別的準確性 , 通常與生成文本的流暢度相關 。 在實踐中 , 困惑度(Perplexity)是衡量語言模型詞元級別錯誤的常用指標 , 因此論文中 TER 由困惑度定義 。 較低的 TER 通常意味著模型能生成更流暢、連貫的文本 。
序列錯誤率(SER):該指標評估整個序列的正確性 , 這對于需要邏輯上完全正確的序列的推理任務(如解決數學問題、代碼生成)至關重要 。
研究團隊首先分析了擴散語言模型以詞元錯誤率(TER)為主要衡量標準時的效率 , 即評估的重點在于生成文本的流暢度和連貫性 。 研究團隊證明目標是接近最優的困惑度時 , MDM 可以在與序列長度無關的恒定采樣步數內實現這一目標 。 換而言之 , 為了達到理想的困惑度 , MDM 所需的采樣步數并不隨序列長度的增加而增長 , 而是一個常數 。 這與自回歸模型形成了鮮明對比 , 后者必須執行序列長度的次數才能生成整個序列 。 因此 , 在生成長篇流暢文本等任務中 , MDM 具備顯著的效率提升潛力 。
這一定程度上解釋了為何 MDM 在 GSM8K 這類數學推理基準測試中表現不佳(如圖 1 所示) 。 數學推理要求思維鏈條的每一步都完美正確 。 SER 與 MDM 解決數學問題的準確性密切相關 , 因為錯誤的思維鏈通常會導致錯誤的答案 。 因此 , MDM 難以在這類數學推理任務上取得效率優勢 , 從而解釋了觀察到的實驗現象 。
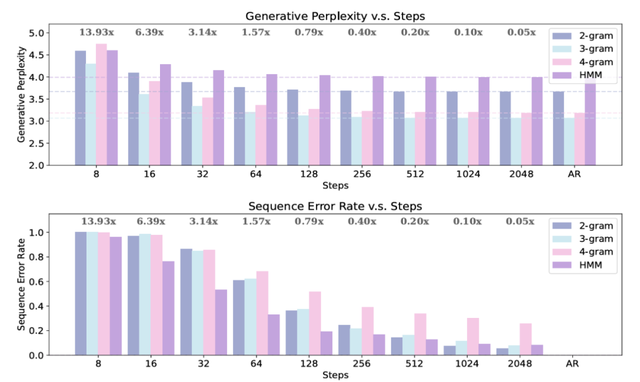
除了理論分析 , 研究團隊又進一步在一些形式語言上驗證了這些理論結果 , 如下圖 2 所示 。 這些實驗結果再一次證明 , 當考慮詞元級別的錯誤率時 , MDM 能夠展現出效率優勢 , 然而當使用序列級別錯誤率作為衡量指標時 , MDM 則不如 AR 模型高效 。
圖 2:MDMs 在形式語言上的表現 。 (上) MDMs 的困惑度與采樣步數的關系 。 (右) MDMs 序列錯誤率與采樣步數的關系 。
結論:擴散語言模型 , 何時才是更優?。 ?
那么 , 回到最初的問題:擴散語言模型真的會比自回歸模型更好嗎?這項研究給出的答案是:視情況而定 , 關鍵在于用什么樣的指標去衡量 。基于這項研究的理論分析和實驗結果 , 我們可以為實踐者提供以下的指導方針。
當任務優先考慮生成文本的流暢性、高吞吐量 , 并且能夠容忍一定程度的序列級別不完美時 , 例如:長篇幅的創意寫作 , 其中整體的可讀性和連貫性比每一句話的絕對事實準確性更重要 , 在這些場景下 , 擴散語言模型能夠展現出效率的優勢 。 然而 , 當任務對序列級別的準確性和邏輯正確性有極高要求時 , 擴散語言模型為達到低 SER 所需的采樣步數隨序列長度線性增長 , 這抵消了其潛在的并行效率優勢 , 甚至可能因單步計算成本更高而變得更慢 。 此時 , 自回歸模型是更好的選擇 。
這項研究為理解 MDM 的比較優勢和局限性奠定了首個堅實的理論基礎 。 當然 , 研究團隊也指出了當前工作的一些局限性 , 例如分析主要集中在形式語言上 , 未來需要將其擴展到更復雜的現代大語言模型;同時 , 分析主要針對掩碼擴散模型 , 其他類型的擴散模型的表現仍有待探索 。
【擴散語言模型真的會比自回歸好?理論分析結果可能恰恰相反】總而言之 , 擴散技術在圖像生成領域的巨大成功 , 并不意味著其優勢可以直接、簡單地平移到語言領域 。 語言的離散性和序列性帶來了獨特的挑戰 , 需要更細致和針對性的評估 。 這項研究以其嚴謹的理論和清晰的實驗 , 為我們揭示了擴散語言模型在效率與質量權衡上的復雜性 , 為整個領域的發展注入了重要的理性思考 。 對于追求特定目標的模型部署而言 , 理解這種權衡對于成本控制和用戶體驗都至關重要 , 錯誤的選擇可能導致用戶體驗不佳或不必要的計算資源浪費 。 最終 , 沒有絕對 “最好” 的模型 , 只有最適合特定任務和特定評估標準的模型 。
推薦閱讀










- AI模型的耗電量驚人 下一步是建設太空數據中心?
- 大模型「躲在洞穴里」觀察世界?強化學習大佬吹哨提醒LLM致命缺點
- 蘋果WWDC掀AI重構風暴!端側模型全開放、AI版Siri卻成最大鴿王
- SSM+擴散模型,竟造出一種全新的「視頻世界模型」
- 大模型智能體如何突破規模化應用瓶頸,核心在于Agentic ROI
- 傳統符號語言傳遞知識太低效?探索LLM高效參數遷移可行性
- 最新發現!每參數3.6比特,語言模型最多能記住這么多
- 多模態擴散模型開始爆發,這次是高速可控還能學習推理的LaViDa
- 刷新世界記錄,40B模型+20萬億token,散戶組團挑戰算力霸權
- 美國人又來搞事,“華為式”的制裁又要擴散了?