想知道你的LLM API被過度收費了嗎?隱藏的Tokens終于可以被審計了

文章圖片
文章圖片
文章圖片

文章圖片
文章圖片
本文作者來自馬里蘭大學的 CASE (Collaborative Automated Scalable and Efficient Intelligence) Lab , 主要參與者為博士生孫國恒與王子瑤 , 指導教師為李昂教授 。
研究背景:在商業保護與用戶知情間尋求平衡
- 論文標題:Invisible Tokens Visible Bills: The Urgent Need to Audit Hidden Operations in Opaque LLM Services
- arXiv 鏈接:https://arxiv.org/pdf/2505.18471
近年來 , 大型語言模型(LLM)在處理復雜任務方面取得了顯著進展 , 尤其體現在多步推理、工具調用以及多智能體協作等高級應用中 。 這些能力的提升 , 往往依賴于模型內部一系列復雜的「思考」過程或 Agentic System 中的 Agent 間頻繁信息交互 。
然而 , 為了保護核心知識產權(如防止模型蒸餾或 Agent 工作流泄露)、提供更流暢的用戶體驗 , 服務提供商通常會將這些中間步驟隱藏 , 僅向用戶呈現最終的輸出結果 。 這在當前的商業和技術環境下 , 是一種保護創新、簡化交互的常見做法 。
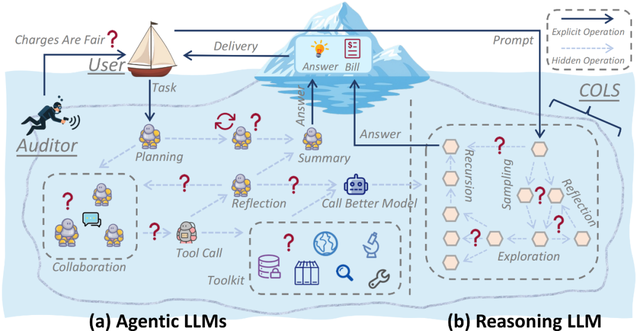
近期 , CASE Lab 團隊將這類隱藏其內部工作流、僅返回最終結果但卻按總 token 量計費的服務定義為「商業不透明大模型服務」(Commercial Opaque LLM Service COLS) 。 如圖 1 所示 , 無論是 Reasoning LLM 還是多智能體系統(Agentic LLMs)相關的服務 , 其內部都存在大量用戶不可見的計費點 。
圖 1:COLS 及其隱藏操作 。
常見的 Reasoning LLM API 和 Agentic LLM APP 如圖 2 所示 , 紅框標識了隱藏操作 。
圖 2:常見的 Reasoning LLM API 和 Agentic LLM APP 。 (a)主流的 Reasoning LLM API 按照包含推理步驟的 completion_tokens 計費 , 但是用戶卻只能看見 Answer 。 (b)主流的 Agentic LLM APP 執行的每個任務都將消耗通過付費訂閱獲得的積分 , 用戶看不到中間過程的細節 。
然而 , 這種商業模式也隱含出一種新型風險:由于用戶無法看到、驗證或質疑這些隱藏操作 , 一些不良的服務提供商在利益驅動下 , 可能通過「虛報消耗 token 數量」或對模型進行「偷梁換柱」來悄悄增加用戶費用或降低自身成本 。
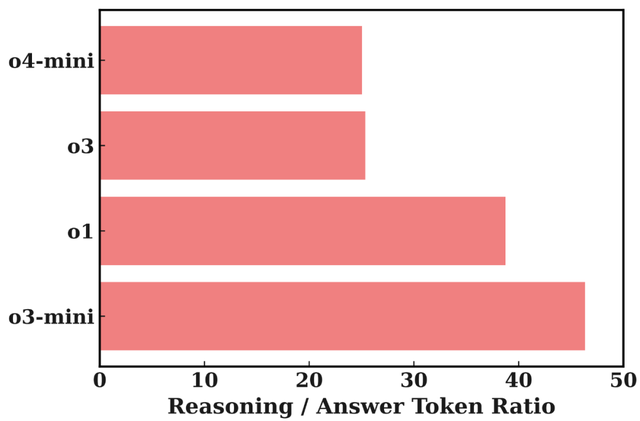
圖 3 以 Reasoning LLM API 為例 , 展示了主流模型隱藏的推理 tokens 數量 , 其常常是最終答案的幾十倍之多 。 這意味著用戶支付的絕大部分費用 , 都花在了他們看不見的地方 , 真實性無從考證 。
圖 3:Reasoning LLM API 在回答 open-r1/OpenR1-Math-220k 數據集中的部分問題時 , 推理 token 與答案 token 的比例 。
團隊對 Reasoning LLM 和 Agentic LLMs 中的主要風險給出了具體定義并給出了潛在解決方案 , 包括:
1. 數量膨脹(Quantity Inflation) , 即服務方通過夸大生成 token 數量或內部模型調用次數來虛增計費 。 具體表現為:
【想知道你的LLM API被過度收費了嗎?隱藏的Tokens終于可以被審計了】
- 在 Reasoning LLM 中 , 可能通過冗余推理步驟(如重復檢索、低效展開)造成 token 增長;
- 在 Agentic LLMs 中 , 則可能存在模型或工具調用的頻率膨脹 , 甚至偽造通信行為 。
2. 質量降級(Quality Downgrade) , 即服務方在保持計費標準不變的情況下 , 悄然替換為低成本模型或工具 。 例如:
- 在 Reasoning LLM 中調用小尺寸的或量化后的模型;
- 在 Agentic LLMs 中模擬工具調用而非真正執行 , 或者用成本更低的工具替代宣稱的高成本工具 , 例如用本地知識庫代替網絡搜索 。
此外 , 如圖 4 所示 , 團隊還提出了一個結構化的三層審計藍圖 , 旨在推動 COLS 行業建立標準化、可驗證的審計基礎設施:
- 第一層(服務執行層):記錄 COLS 內部模型生成、Agent 通信與工具調用等核心操作;
- 第二層(安全承諾與記錄層):將上述操作以加密摘要、哈希鏈、區塊鏈等形式提交為可驗證承諾;
- 第三層(審計與反饋層):允許用戶或第三方審計機構對服務行為進行獨立驗證 , 并為用戶提供賬單合理性或服務一致性的反饋報告 。
圖 4:三層審計框架 。
該框架基于「可驗證但不泄密」的理念 , 鼓勵未來的 COLS 服務商在保護商業敏感信息的同時 , 實現對用戶透明、可信的服務承諾 。 這一體系既支持技術層面的透明性 , 也為政策制定與合規提供了實現路徑 。
CoIn:讓隱藏操作可驗證但不泄露
- 論文標題:CoIn: Counting the Invisible Reasoning Tokens in Commercial Opaque LLM APIs
- arXiv 鏈接:https://arxiv.org/pdf/2505.13778
- GitHub 鏈接:https://github.com/CASE-Lab-UMD/LLM-Auditing-CoIn
- Hugging Face 鏈接:https://huggingface.co/collections/s1ghhh/coin-llm-auditing-6842a46feea043d46c0d338e
為了解決 Reasoning LLM API 的計費審計問題 , 該研究團隊還提出了用于防止 token 數量膨脹(Quantity Inflation)的驗證框架 CoIn , 旨在提供一種技術可能性 , 在尊重和保護 COLS 的商業機密和知識產權的前提下 , 賦予用戶驗證服務真實性的途徑 , 從而在用戶和 COLS 之間搭建起一座「信任橋梁」 。
如算法 1 所示 , CoIn 包含適應性的多輪驗證 , 其中每輪會驗證 COLS 宣稱的 Token 數量是否準確以及隱藏的 Reasoning Token 是否真正參與推導出答案 , 最終由 Verifier 來給出判斷 。 對于正常樣本 , CoIn 會在早期便驗證成功并結束 , 而對于較難判斷的樣本或者數量膨脹后的惡意樣本 , CoIn 會驗證更多輪 , 避免漏判 。
算法 1:CoIn 的適應性多輪驗證 。
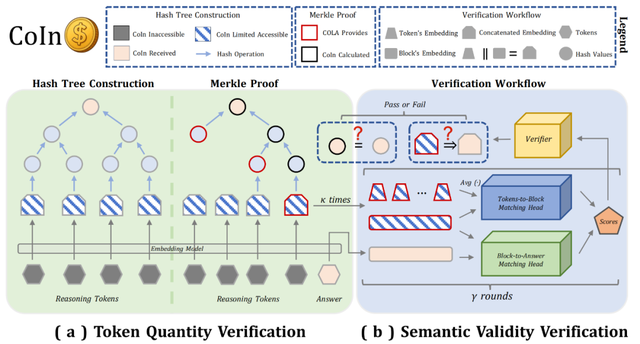
CoIn 框架的單輪驗證主要包含兩大模塊:
1.Token 數量驗證 (Token Quantity Verification): 如圖 5-(a) 所示 , 這一模塊巧妙地運用了密碼學中的默克爾樹 (Merkle Tree) 技術 。 COLS 需將其所有隱藏 tokens 的「指紋」(即嵌入向量 , embedding)作為葉子節點 , 構建一棵哈希樹 , 并向審計方(可以是用戶或獨立的第三方平臺)提供最終的哈希根(Merkle Root) 。 在審計時 , 審計方僅需請求并驗證極少數隨機抽取的 token “指紋” 及其在哈希樹中的路徑(Merkle Proof) , 便能高效地核實 token 總數是否與聲明一致 , 而無需訪問所有 token 的原始內容 。
這種方法的核心優勢在于 , 它能在泄露很少推理步驟的前提下 , 確保數量的準確性 。 更重要的是 , 由于哈希承諾的特性和用戶質疑的隨機性 , 惡意 COLS 的偽造必須做全套 , 并且在返回給用戶結果時就得完成偽造 , 無法專門應對用戶的質疑 , 大大提高了 COLS 的造假成本 。
2. 語義有效性驗證 (Semantic Validity Verification): 僅驗證數量的準確性尚不足以完全打消用戶的疑慮 , 因為理論上 COLS 仍可能產生大量與任務目標關聯較弱的「無效」token 來冒充隱藏 token 。如圖 5-(b) 所示 , CoIn 設計了輕量級的「Matching Head」來分析被抽查的隱藏 token(的指紋)與最終答案之間的語義連貫性和邏輯相關性 , 并給出一個相關性評分 。 如果評分顯著偏低 , 則可能表明這些隱藏 token 對最終結果的貢獻有限 。 這一機制旨在確保用戶支付的費用 , 對應的是真正服務于任務目標的有效推理過程 。
圖 5:CoIn 驗證框架 。
團隊定義了 COLS 可能會實施的多種適應性數量膨脹攻擊 , 并據此在醫療、代碼、數學、通用推理等多個不同領域上構建了高難度的數據集 , 用于訓練 CoIn 框架中的 Matching Head 和 Verifier , 以及驗證 CoIn 框架的性能 。 實驗結果顯示 , CoIn 框架具有如下特性:
- 高效識別 token 數量膨脹:圖 6 展示了 CoIn 在不同模擬場景下的檢測成功率(Detection Success Rate DSR) , 可以看到 , 隨著膨脹率(Inflation Rate = 偽造的 token 數 / 真實 token 數)的增加 , CoIn 的識別能力也相應增強 。 在高膨脹率的場景下(即 COLS 偽造的 token 占比超過 50%) , 即使面對經過特殊設計、語義上與原始內容相似的「自適應 token 膨脹 」場景 , 在僅暴露極少量信息的情況下 , CoIn 的平均 DSR 也能達到 94.7% 。 而對于 COLS 僅僅虛報 10% tokens 的場景中 , CoIn 也有約 40% 的平均 DSR 。
- 可定制性:圖 6 中的紅線和藍線分別代表兩種類型的 Verifier , 一種基于神經網絡 , 一種基于規則 。 前者對于惡意樣本具有很高的 DSR , 但是對正常樣本的誤判率也比較高 。 而后者則可以由 COLS 和用戶協商后設置參數 , 在減少對正常樣本的誤判和高效檢測數量膨脹之間達到平衡 。
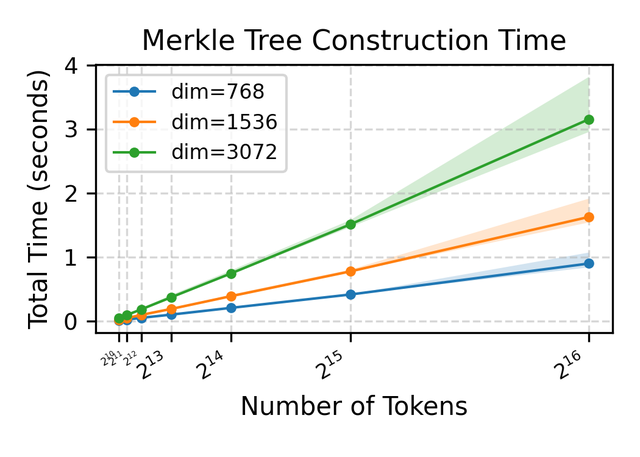
- 極低的審計開銷: 整個審計過程對用戶和服務商而言開銷較低 。 在驗證過程中 , 審計方僅需訪問不到 4% 的隱藏 token 信息(指紋) , 便能完成高精度的驗證 。 如圖 7 所示 , 默克爾樹的構建在單核 CPU 上只需要一秒左右 , 對于擁有強大計算資源的 COLS 而言 , 其額外開銷幾乎可以忽略不計 。
圖 6:不同膨脹率(Inflation Rate)下 , CoIn 應對多種數量膨脹攻擊時的表現 。
圖 7:不同隱藏 Tokens 數量和 Embedding 模型 Hidden Dimension 下 , Merkle 哈希樹的構建成本 。
總的來說 , 來自馬里蘭大學的 CASE Lab 團隊首次系統性地分析了當前主流大模型服務在「隱藏操作」透明度方面面臨的挑戰 , 并提出了首個旨在解決 token 數量膨脹問題的審計框架 CoIn 。
CoIn 的核心貢獻在于 , 它探索出一條在平衡服務商知識產權保護與用戶對服務透明度合理需求之間的技術路徑 , 期望能為構建用戶和服務商之間的相互信任提供有力的技術支撐 。
截至目前 , 主流推理模型均不會暴露自己的推理過程 , 盡管這部分仍然需要用戶付費 。 然而 , 已經有一些轉變標識著各大 LLM API 提供商正在嘗試達到知識產權保護和用戶知情權的平衡 。 例如 , 幾乎所有服務提供商都會提供返回摘要的服務;Claude 4.0 可以提供加密后的推理 tokens 以便用戶檢查真實性以及保障推理過程未被篡改 。
CASE Lab 團隊呼吁學界和業界共同關注這一新興領域 , 共同推動建立更加透明、公平和可信的 AI 服務標準與實踐 。 未來的研究方向可以包括開發更為完善和易于部署的審計協議或框架 , 探討將此類審計機制作為行業準則或第三方認證標準的可行性 , 以及推動相關技術標準和最佳實踐的形成 。 最終目標是促進整個大模型生態系統的健康、可持續發展 , 讓前沿的人工智能技術能夠在贏得公眾持久信任的基礎上 , 更好地服務于社會 。
推薦閱讀














- 掌中時尚影棚,vivo S30一鍵喚醒你的大片創作欲
- 1200行代碼逆襲!DeepSeek工程師開源輕量級vLLM,吞吐量逼近原版
- HarmonyOS 5.1將于7月開啟升級!為你的設備注入全新升級體驗!
- 精致小屏也能性能全開,vivo S30系列重塑你的期待
- 華為mate40,我心中永遠都有你的位置!
- iOS 26升級名單已公布:多款經典設備正式謝幕,你的在內嗎?
- 大模型「躲在洞穴里」觀察世界?強化學習大佬吹哨提醒LLM致命缺點
- vivo S30系列火熱開售中!全能表現滿足你的多樣需求
- 傳統符號語言傳遞知識太低效?探索LLM高效參數遷移可行性
- 預售進行時!vivo S30系列選購指南:哪款配色最適合你的style