
文章圖片
文章圖片

文章圖片

文章圖片
文章圖片

文章圖片
文章圖片

文章圖片
本文由半導體產業縱橫(ID:ICVIEWS)編譯自technews
誰能率先突破傳輸效率與延遲的限制 , 誰就有機會在下一波AI競賽中奪得先機 。
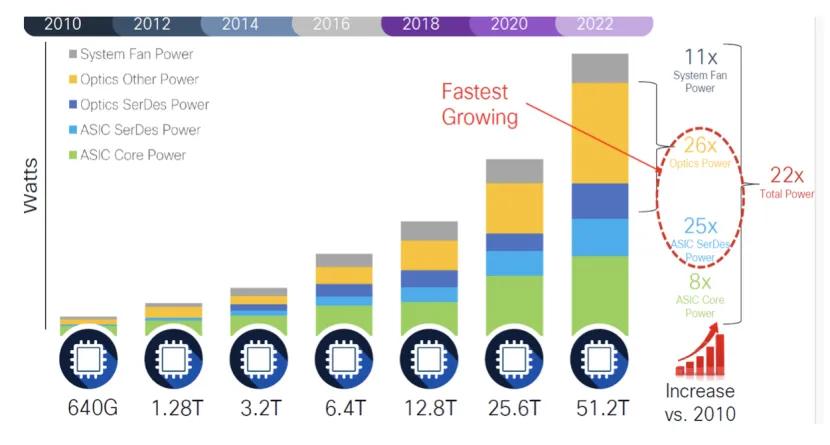
在人工智能(AI)、機器學習的推動下 , 全球數據流量正成倍增長 , 目前數據中心服務器與交換機之間的連線正從200G、400G快速邁向800G、1.6T , 甚至可能進入3.2T的時代 。
市場調研機構TrendForce預測 , 2023年400G以上的光收發模組全球出貨量為640萬個 , 2024年約2040萬個 , 預計至2025年將超過3190萬個 , 年增長率達56.5% 。 其中 , AI服務器的需求持續推升800G及1.6T的成長 , 而傳統服務器也隨著規格升級 , 帶動400G光收發模組的需求 。
另據機構調查 , 2026年1.6T光模組需求將大幅超出預期 , 總出貨量預計高達1100萬支 , 主要動力來自NVIDIA與Google的強勁采購 , 以及Meta、微軟、AWS的部分需求 。
光通信因為高帶寬、低損耗與長距離特性 , 逐漸成為機柜內外互連的主要選擇方案 , 使得光收發模組成為數據中心互連的關鍵 。 TrendForce指出 , 未來AI服務器之間的數據傳輸 , 都需要大量的高速光收發模組 , 這些模組負責將電信號轉換為光信號 , 并通過光纖傳輸 , 以及將接收到的光信號轉換回電信號 。
光收發模組、光通信和硅光子有何關系?根據下圖的前兩個示意圖可知 , 目前市面上的可插拔光收發器傳輸速率可達 800G , 下一階段的光引擎( Optical Engine, 簡稱OE) 已經可安裝在ASIC芯片封裝周圍 , 這稱為載板光學封裝( On- Board Optics, 簡稱OBO) , 其傳輸能力可支援至1.6T 。
目前業界希望走向“CPO”(Co-packaged Optics , 共封裝光學) , 即光學元件與ASIC能共同封裝 , 通過這項技術實現超過3.2T、最高達12.8T的傳輸速度;而最終目標則是達到“Optical I/O”(光學I/O) , 實現類似全光網絡的技術 , 推動傳輸速度超過12.8T 。
如果仔細觀察上圖 , 可以發現作為黃色方塊的光通信模組(以前為可插拔形態)距離ASIC越來越近 , 這主要是為了縮短電信號的傳輸路徑 , 從而實現更高的帶寬 。 而硅光子制程技術 , 就是將光學元件整合到芯片上的技術 。
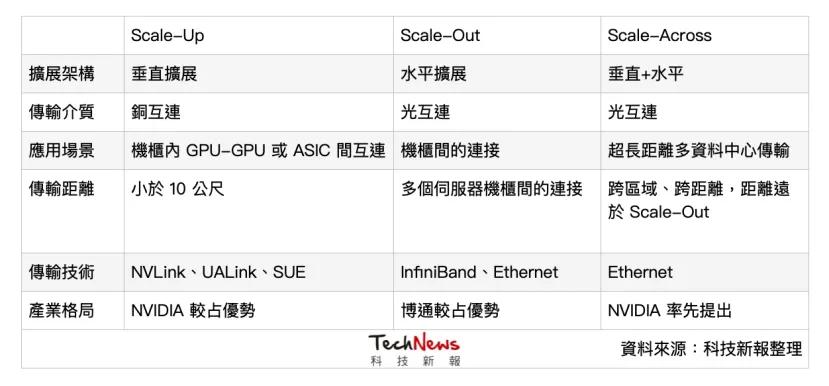
光通信需求暴增 , 業界聚焦三種擴展服務器架構由于AI應用大爆發 , 對于高速光通信的需求急劇提升 , 目前服務器主要聚焦Scale Up(垂直擴展)、Scale Out(水平擴展)兩種擴展方向 , 分別對應不同的傳輸需求與技術挑戰 , 而近期NVIDIA又新宣布“ScaleAcross”這個概念 , 為業界增添一個思考方向 。
Scale-Up
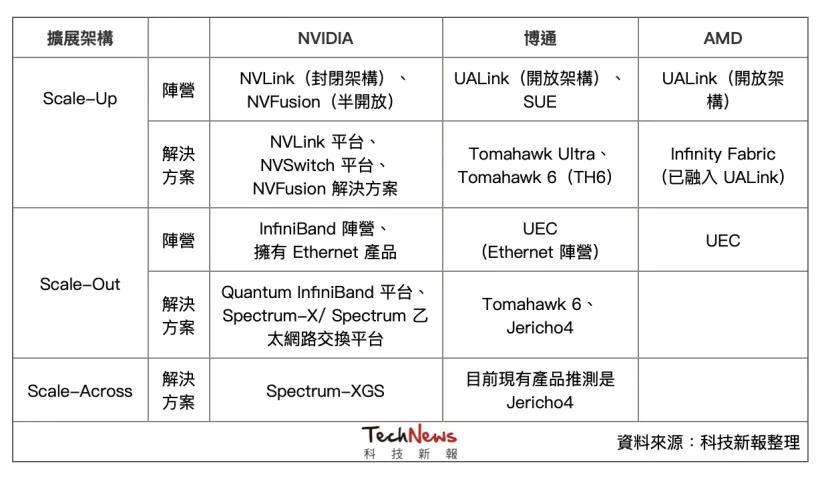
Scale-Up主要作為機柜內高速互連(上圖黃色部分) , 傳輸距離通常在10公尺以內 , 由于對延遲的要求極低 , 內部仍主要采用“銅互連”(Copper Interconnects) , 避免光電轉換造成延遲與能耗 。 目前解決方案主要有NVIDIA的NVLink(封閉架構)及AMD等其他公司主導的UALink(開放架構) 。
有趣的是 , 今年NVIDIA推出NVLink Fusion , 首度開放NVLink技術給外部芯片廠商 , 將NVLink從單一服務器節點延伸至整個機柜級(Rack-Scale)架構 , 不排除是為了因應UALink的競爭 。
另一個值得關注的是 , 原本主要專注于Scale-Out的博通 , 正嘗試通過“以太網”(Ethernet)進軍Scale-Up市場 。 該公司近期推出多款可用于Scale-Up、符合SUE(Scale-Up Ethernet)標準的芯片 , 后續可以關注NVIDIA與博通在這方面的競爭 。
Scale-Out
Scale-Out則是橫跨服務器的大規模并行運算(上圖中藍色部分) , 用于解決數據高吞吐量問題并實現無限擴充 。 這以“光通信”為主 , 主要的網絡互聯技術依靠InfiniBand或者以太網(Ethernet) , 也將帶動光通信模組市場 。
InfiniBand和Ethernet又可以分成兩大陣營 , 前者較受NVIDIA 、微軟等大廠的青睞 , 而后者則以博通、 Google 、 AWS為主 。
談到InfiniBand , 不得不提領先廠商Mellanox , 它在2019年被NVIDIA收購 , 是提供端到端Ethernet與InfiniBand智能互連解決方案的供應商 。 而中國近期裁定NVIDIA違反反壟斷法 , 就是針對這起收購案 。 另一個關注點是 , 雖然NVIDIA推出許多InfiniBand產品 , 但也針對以太網推出相關產品如NVIDIA Spectrum-X , 可以說是兩種市場兼吃 。
作為另一大陣營如英特爾、AMD、博通等大廠于2023年7月集結組成“超以太網聯盟”(Ultra Ethernet Consortium, 簡稱UEC) , 合作發展改進的以太網傳輸堆棧架構 , 成為挑戰InfiniBand的力量之一 。
TrendForce分析師儲于超認為 , Scale Out所帶動的光通信模組市場 , 正是未來數據傳輸的核心戰場 。
Scale-Across
作為新興的解決方案 , NVIDIA近期提出“Scale-Across”的概念 , 即跨數據中心的“遠距連接” , 距離能超過數公里 , 并推出以以太網為基礎、串接多座數據中心的Spectrum-XGS以太網 。
Spectrum-XGS以太網將作為AI運算中Scale-Up和Scale-Out以外的第三大支柱 , 主要用來擴展Spectrum-X以太網的極致效能與規模 , 可連接多個分散式數據中心 。 NVIDIA介紹 , NVIDIA Spectrum-X以太網除了提供Scale-Out的架構 , 連接整個集群、將多個分散式數據中心進行互連 , 快速將大量數據集串流至AI模型 , 還可在數據中心內協調GPU與GPU之間的通信 。
換言之 , 這個解決方案結合Scale-Out與跨域擴展 , 能根據跨域距離靈活調整負載平衡、動態調整算法 , 因此概念更類似“Scale-Across” 。
NVIDIA創辦人暨執行長黃仁勛表示 , “我們在Scale-Up與Scale-Out能力之上 , 進一步加入Scale-Across , 把跨城市、跨國家乃至跨洲際的數據中心聯結起來 , 打造龐大的超級AI工廠 。 ”
如果從目前產業走向來看 , Scale-Up和Scale-Out都是必爭之地 , 可以看出NVIDIA和博通如何從對方手中奪取多一分領地 。 而NVIDIA新喊出的Scale-Across則是聚焦橫跨數公里乃至于數千公里的跨數據中心傳輸 , 有趣的是 , 博通也有推出相關的解決方案 。
事實上 , 現在AI產業的競爭除了芯片間的競爭外 , 更是擴大到系統間解決方案的競爭 。
博通與NVIDIA的第一個交集就是“定制化AI芯片”(ASIC) 。 由于NVIDIA GPU價格高昂 , 包括Google、Meta、亞馬遜、微軟等云端服務供應商(CSP)都在開發自家AI芯片 , 而博通的ASIC能力成為這些公司的首要選擇 。
除了自研芯片的競爭外 , 另一個更關鍵技術是“網絡連接技術” , 這也是博通與 NVIDIA 的第二個交集 。
首先是在Scale-Up部分 , 在NVLink和CUDA這兩大護城河守護下 , 博通醞釀了多時 , 終于在今年推出最新的網絡交換機芯片Tomahawk Ultra(戰斧) , 有機會切入Scale-Up市場 , 目標挑戰NVIDIA NVLink的主導地位 。
Tomahawk Ultra是博通一直推動的“縱向擴展以太網”(Scale-Up Ethernet , 簡稱SUE)計劃的一部分 , 這個產品也被視為NVSwitch的替代方案 。 博通表示 , Tomahawk Ultra一次可串聯的芯片數量是NVLink Switch的四倍 , 將交由臺積電5納米制程 。
值得注意的是 , 博通雖然身為UALink聯盟成員之一 , 但它也積極推廣基于以太網SUE架構 , 因此市場也相當關注博通與UALink的競合關系 , 以及如何共同應對NVLink這個大敵 。
為了抵御博通強襲 , NVIDIA今年也推出 NVFusion 解決方案 , 開放合作伙伴如聯發科、Marvell、Astera Labs等共研 , 并通過NVLink生態系打造客制化的AI芯片 。 外界認為 , 這是為了鞏固生態系而進行的半開放式合作 , 也給更多合作伙伴一些客制化空間與機會 。
Scale-Out方面 , 主要由在以太網領域深耕已久的博通占據主導 , 近期最新推出的產品包括Tomahawk 6、Jericho4 , 以搶占Scale-Out和更遠傳輸距離的商機 。
而NVIDIA則推出許多Quantum InfiniBand交換機產品 , 以及Spectrum以太網交換平臺 , 加強更多面向的Scale-Out產品 。 雖然InfiniBand屬于開放架構 , 但因產品生態環境主要仍由NVIDIA收購的Mellanox所主導 , 限制了客戶的選擇靈活性 。
根據博通的相關數據 , 三款產品各自橫跨兩種不同的服務器擴展架構 。
針對更長距離的跨數據中心擴展的Scale-Across , 目前還不確定博通和NVIDIA誰會領先 , 不過NVIDIA針對這一概念率先推出Spectrum-XGS , 該解決方案通過新的網絡算法 , 來實現站點之間更遠距離的數據有效移動 , 也可以作為現有Scale-Up和Scale-Out架構的補充方案 。
至于博通的Jericho4也符合Scale-Across的概念 。 博通指出 , Tomahawk系列芯片能串聯單一數據中心內的機柜 , 連接距離通常不超過一公里(約0.6英里) , 而Jericho4設備則能處理超過100公里的跨機房連接 , 維持無損RoCE傳輸 , 其數據處理能力約為前一代產品的四倍 。
那么NVIDIA 和博通的CPO 解決方案?隨著網絡傳輸戰場持續 , 相信在光網絡的競爭將會更加激烈 , 對此NVIDIA和博通都針對CPO光通訊找尋新解方 , 而臺積電、格羅方德也積極開發用于CPO的制程與解決方案 。
NVIDIA的策略是以系統架構為出發點 , 并將光學互連視為SoC的一部分 , 而非外掛式模組 , 并于今年 GTC正式發表Quantum-X Photonics InfiniBand交換器和Spectrum-X Photonics Ethernet交換器 , 前者將于年底推出 , 后者則于2026年問世 。
兩個平臺均采用臺積電COUPE平臺 , 通過SoIC-X封裝技術將65納米的光子積體電路(PIC)與電子積體電路(EIC)整合 。 而這個策略出發點 , 是為了強調自家平臺整合 , 加強整體效益與規模擴展 。
博通的策略則專注于提供全方位解決方案 , 聚焦在供應鏈的規模化運作 , 供應第三方客戶完整的模組化方案 , 幫助客戶應用落地 。 博通也表示 , 公司之所以在CPO領域成功 , 是建立在深厚的半導體與光學技術整合能力之上 。
博通目前推出第三代200G / lane CPO搶市 。 博通也表示 , 其 CPO產品采用3D芯片堆疊架構 ,PIC同樣使用65納米 ,EIC則采用7納米制程 。
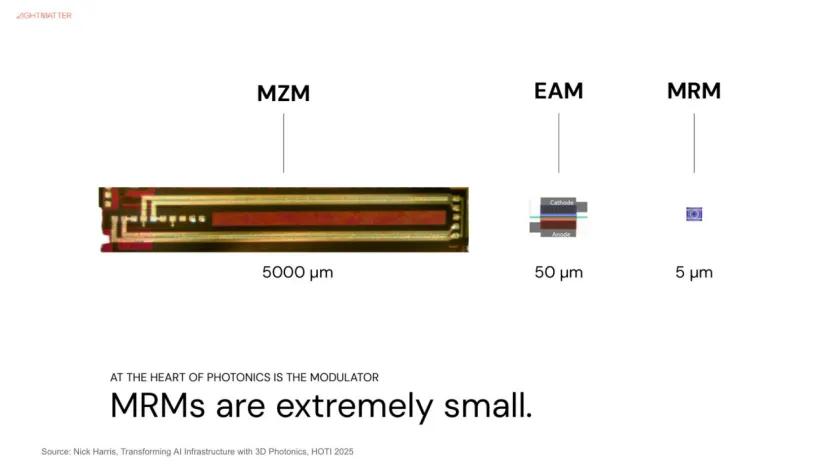
由下圖可知 , 光收發模組由以下關鍵元件組成 , 如雷射光源(Laser Diode )、光調變器( Modulator )、光感測器( Photo Detector )等 。 其中 , 雷射光源負責產生光信號 , 光調變器負責將電信號/數位信號轉成光信號 , 因為涉及電光轉換 , 也可以說是決定單通道傳輸速度的關鍵 。
在關鍵的光調變器上 , NVIDIA選擇MRM (微環調變器 ,Micro-Ring Modulator ) 。 由于MRM尺寸較小 , 容易受誤差及溫度影響 , 也將是導入MRM的挑戰之一 。
至于博通 , 則選擇使用技術較成熟的MZM調變器(馬赫–曾德爾調變器 ,Mach-Zehnder Modulator ) , 同時布局 MRM 技術 , 目前已經通過3 納米制程試產 , 并以芯片堆疊方式 , 持續領導CPO 進展 。
目前在AI推論持續擴張浪潮下 , 市場焦點已逐漸從“算力競賽”轉向“數據傳輸速度” , 無論是博通主打的網絡與交換技術、NVIDIA推動的端到端解決方案 , 誰能率先突破傳輸效率與延遲的限制 , 誰就有機會在下一波AI競賽中奪得先機 。
*聲明:本文系原作者創作 。 文章內容系其個人觀點 , 我方轉載僅為分享與討論 , 不代表我方贊成或認同 , 如有異議 , 請聯系后臺 。
【CPO賽道對決!NVIDIA、博通到底在競爭什么?】想要獲取半導體產業的前沿洞見、技術速遞、趨勢解析 , 關注我們!
推薦閱讀













- 影石殺入AI錄音硬件賽道,2198元起和科大訊飛直接競爭
- 面對千億美元賽道,北京三次押重注在最早專注AR眼鏡的亮亮視野
- 扎克伯格寧愿浪費數千億也不愿錯過AI賽道,互聯網大廠砸了多少錢
- 2025年最強三芯孰強孰弱?驍龍、天璣和蘋果處理器的年度對決總結
- 高端泳池機器人品牌星邁創新完成10億元融資,正式入局割草賽道|硬氪獨家
- 央視撒貝寧探廠刷屏:天馬用天工屏給OLED換了一條新賽道!
- 大疆運載,被低估的“超級賽道”
- 從造車到造“人”:奇瑞招商在即,車企搶占機器人賽道
- 聯發科連放兩記重錘:天璣9500搶先亮相,天璣9600瞄準2nm新賽道
- 小紅書殺入本地生活到店賽道,或將在10天后正式上線