
文章圖片

文章圖片

文章圖片

文章圖片

文章圖片
文章圖片
文章圖片
曾以低價高性能震撼市場的DeepSeek , 為何在自家平臺遇冷 , 市場份額下滑?背后隱藏的「Token經濟學」和這場精心策劃的戰略轉移 , 正悄然改變著AI的價值鏈與分發模式 。
最近 , 全世界的大廠都在蠢蠢欲動了!
GPT-5、Grok 4 , 甚至Claude , 都已經紛紛有了消息 , 一場惡戰仿佛就在眼前!
DeepSeek這邊 , 似乎也有新動靜了 。
就在昨天 , 一個疑似DeepSeek的新模型現身LM Arena 。
也有人猜測 , 這個模型更可能是DeepSeek V4 , 而DeepSeek R2會稍后發布 。
套路很可能和之前是一樣的 , 先在第一個月發布V3 , 然后在下個月發布R1 。
所以 , 曾經轟動全球AI圈的中國大模型DeepSeek R1 , 如今怎樣了?
到今天為止 , DeepSeek R1已經發布超過150天了 。
當時一經問世 , 它就以OpenAI同等級的推理能力和低90%的價格而迅速出圈 , 甚至一度撼動了西方的資本市場 。
可是如今 , 它在用戶留存和官網流量上卻雙雙遇冷 , 市場份額持續下滑 。
DeepSeek就這樣曇花一現 , 紅極一時后迅速衰落了?
其實不然 , 在這背后 , 其實隱藏著另一條增長曲線——
在第三方平臺上 , R1已經成爆炸性增長 , 這背后 , 正是折射出AI模型分發與價值鏈的悄然變革 。
SemiAnalysis今天發布的這篇文章 , 挖出了不少一手的內幕信息 。
DeepSeek , 盛極而衰?DeepSeek發布后 , 消費者應用的流量一度激增 , 市場份額也隨之急劇上升 。
為此 , SemiAnalysis做出了下面這份統計曲線 。
當然 , 他們也承認 , 由于中國的用戶活動數據難以追蹤 , 且西方實驗室在中國無法運營 , 下面這些數據實際上低估了DeepSeek的總覆蓋范圍 。
不過即便如此 , 曾經它爆炸性的增長勢頭也未能跟上其他AI應用的步伐 , 可以確定 , DeepSeek的市場份額此后已然下滑 。
而在網絡瀏覽器流量方面 , 它的數據就更為慘淡了:絕對流量一直在下降 , 但其他頂尖模型的用戶數卻噌噌飛漲 , 十分可觀 。
不過 , 雖然DeepSeek自家托管模型的用戶增長乏力 , 但在第三方平臺那里 , 就完全是冰火兩重天了 。
可以看到 , R1和V3模型的總使用量一直在持續快速增長 , 自R1首次發布以來 , 已經增長將近20倍!
如果進一步深挖數據 , 就會發現:只看由DeepSeek自己托管的那部分Token流量 , 那它在總Token中的份額的確是逐月下降的 。
那么 , 問題來了:為何在DeepSeek模型本身越來越受歡迎、官方價格非常低廉的情況下 , 用戶反而從DeepSeek自家的網頁應用和API流失 , 轉向了其他開源提供商呢?
【DeepSeek流量暴跌?AI大模型全球霸主離奇遇冷,外媒曝出真相】SemiAnalysis點出了問題關鍵——
答案就在于「Token經濟學」 , 以及在平衡模型服務的各項KPI時所做的無數權衡 。
這些權衡意味著 , 每個Token的價格并非一個孤立的數字 , 而是模型提供商根據其硬件和模型配置 , 在對各項KPI進行決策后得出的最終結果 。
Token經濟學基礎我們都知道 , Token是構成AI模型的基本單元 。 AI模型通過讀取以Token為單位的互聯網信息進行學習 , 并以文本、音頻、圖像或行為指令等Token形式生成輸出 。
所謂Token , 就是像「fan」、「tas」、「tic」這樣的小文本片段 。 LLM在處理文本時 , 并非針對完整的單詞或字母 , 而是對這些片段進行計數和處理 。
這些Token , 便是老黃口中數據中心「AI工廠」的輸入和輸出 。
如同實體工廠一樣 , AI工廠也遵循一個「P x Q」(價格 x 數量)的公式來盈利:其中 , P代表每個 Token的價格 , Q代表輸入和輸出Token的總量 。
但與普通工廠不同 , Token的價格是一個可變參數 , 模型服務商可以根據其他屬性來設定這個價格 。
以下 , 就是幾個關鍵的性能指標(KPI) 。
延遲(Latency)或首個Token輸出時間(Time-to-First-Token)
指模型生成第一個Token所需的時長 。 這也可以理解為模型完成「預填充」階段(即將輸入提示詞編碼到KVCache中)并開始在「解碼」階段生成第一個Token所需的時間 。
吞吐量(Throughput)或交互速度(Interactivity)
指生成每個Token的速度 , 通常以「每個用戶每秒可生成的Token數量」來衡量 。
當然 , 有些服務商也會使用其倒數——即生成每個輸出Token的平均間隔時間(Time Per Output Token TPOT) 。
人類的閱讀速度約為每秒3-5個單詞 , 而大部分模型服務商設定的輸出速度約為每秒20-60個Token 。
上下文窗口(Context Window)
指在模型「遺忘」對話的早期部分、并清除舊的Token之前 , 其「短期記憶」中能夠容納的Token數量 。
不同的應用場景需要大小各異的上下文窗口 。
例如 , 分析大型文檔和代碼庫時 , 就需要更大的上下文窗口 , 以確保模型能夠對海量數據進行連貫的推理 。
對于任何一個給定的模型 , 你都可以通過調控這三大KPI , 設定出幾乎任何價位的單位Token價格 。
因此 , 單純基于「每百萬Token的價格」($/Mtok)來討論優劣 , 并沒有什么意義 , 因為這種方式忽略了具體工作負載的性質 , 以及用戶對Token的實際需求 。
DeepSeek的策略權衡所以 , DeepSeek在R1模型服務上采用了何種Token經濟學策略 , 以至于市場份額會不斷流失?
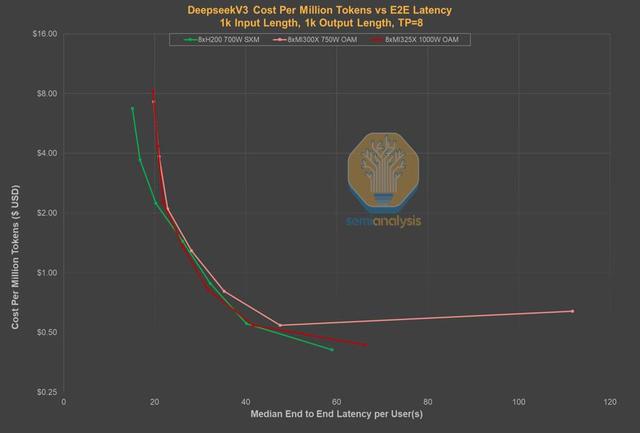
通過對比延遲與價格的關系圖 , 可以看到 , 在同等延遲水平上 , DeepSeek的自有服務已不再是價格最低的選擇 。
事實上 , DeepSeek之所以能提供如此低廉的價格 , 一個重要原因在于 , 用戶等待數秒后 , 才能收到模型返回的第一個Token 。
相比之下 , 其他服務商的延遲會短得多 , 價格卻幾乎沒有差別 。
也就是說 , Token消費者只需花費2-4美元 , 就能從Parasail或Friendli這類服務商那里 , 獲得近乎零延遲的體驗 。
同樣 , 微軟Azure的服務價格雖比DeepSeek高2.5倍 , 但延遲卻減少了整整25秒 。
這樣看來 , DeepSeek現在面臨的處境就尤為嚴峻了 。
原因在于 , 現在幾乎所有托管R1 0528模型的實例都實現了低于5秒的延遲 。
沿用同一圖表 , 但這次我們將上下文窗口的大小用氣泡面積來表示 。
從中可以看到 , DeepSeek為了用有限的推理算力資源來提供低價模型 , 所做的另一項權衡 。
他們采用的64K上下文窗口 , 幾乎是主流模型服務商中最小的之一 。
較小的上下文窗口限制了編程等場景的發揮 , 因為這類任務需要模型能夠連貫地記憶代碼庫中的大量Token , 才能進行有效推理 。
從圖表中可見 , 若花費同樣的價格 , 用戶可以從Lambda和Nebius等服務商那里獲得超過2.5倍的上下文窗口大小 。
如果深入硬件層面 , 在AMD和英偉達芯片上對DeepSeek V3模型的基準測試 , 就可以看清服務商是如何確定其「每百萬Token價格」($/Mtok)的——
模型服務商會通過在單個GPU或GPU集群上同時處理更多用戶的請求(即「批處理」) , 來降低單位Token的總成本 。
這種做法的直接后果 , 就是終端用戶需要承受更高的延遲和更慢的吞吐量 , 從而導致用戶體驗急劇下降 。
之所以DeepSeek完全不關心用戶的體驗到底如何 , 實際上是一種主動作出的戰略選擇 。
畢竟 , 從終端用戶身上賺錢 , 或是通過聊天應用和API來消耗大量Token , 并不是他們的興趣所在 。
這家公司的唯一焦點就是實現AGI!
而通過采用極高批處理方式 , DeepSeek可以最大限度地減少用于模型推理和對外服務的計算資源消耗 , 從而將盡可能多的算力保留在公司內部 , 從而用于研發 。
另外還有一點:出口管制也限制了中國AI生態系統在模型服務方面的能力 。
因此 , 對DeepSeek而言 , 開源就是最合乎邏輯的選擇:將寶貴的計算資源留作內部使用 , 同時讓其他云服務商去托管其模型 , 以此贏得全球市場的認知度和用戶基礎 。
不過 , SemiAnalysis也承認 , 這卻并沒有削弱中國公司訓練模型的能力——無論是騰訊、阿里、百度 , 還是小紅書最近發布的新模型 , 都證明了這一點 。
Anthropic也一樣?和DeepSeek一樣 , Anthropic的算力也是同樣受限的 。
可以看到 , 它產品研發的重心顯然放在了編程上 , 而且已經在Cursor等應用中大放異彩 。
Cursor的用戶使用情況 , 就是評判模型優劣的終極試金石 , 因為它直接反映了用戶最關心的兩個問題——成本與體驗 。
而如今 , Anthropic的模型已雄踞榜首超過一年——在瞬息萬變的AI行業里 , 這個時長仿佛已經如十年 。
而在Cursor上大獲成功后 , Anthropic立馬順勢推出了Claude Code , 一款集成在終端里的編程工具 。
它的用戶量一路飆升 , 將OpenAI的Codex模型遠遠甩在身后 。
為了對達Claude Code , 谷歌也緊急發布了Gemini CLI 。
它與Claude Code功能相似 , 但因為背靠谷歌TPU , 卻有非凡的算力優勢——用戶能免費使用的額度 , 幾乎無上限 。
不過 , 盡管Claude Code的性能和設計都十分出色 , 價格卻不菲 。
Anthropic在編程上的成功 , 反而給公司帶來了巨大壓力——他們在算力上已經捉襟見肘 。
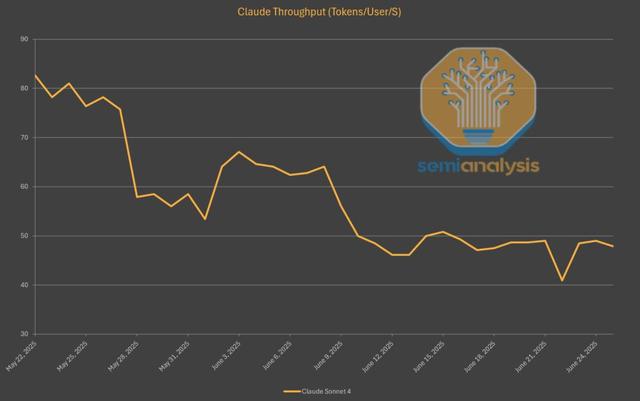
這一點 , 在Claude 4 Sonnet的API輸出速度上就已經體現得淋漓盡致 。 自發布以來 , 它的生成速度已下降了40% , 略高于每秒45個Token 。
背后的原因 , 也和DeepSeek如出一轍——為了在有限的算力下處理所有涌入的請求 , 他們不得不提高批處理的速率 。
此外 , 編程類的使用場景往往涉及更長的對話和更多的Token數量 , 這就進一步加劇了算力的緊張狀況 。
無論是何種原因 , 像o3和Gemini 2.5 Pro這類對標模型的運行速度要快得多 , 這也反映出OpenAI和谷歌所擁有的算力規模要龐大得多 。
現在 , Anthropic正集中精力獲取更多算力 , 已經和亞馬遜達成了協議 。 它將獲得超過五十萬枚Trainium芯片 , 用于模型訓練和推理 。
另外 , Claude 4模型并非在AWS Trainium上預訓練的 , 而是在GPU和TPU上訓練 。
速度劣勢可由效率彌補Claude 的生成速度雖然暴露了其算力上的局限 , 但總體而言 , Anthropic的用戶體驗(UX)要優于 DeepSeek 。
首先 , 其速度雖然偏低 , 但仍快于DeepSeek的每秒25個Token 。
其次 , Anthropic的模型回答同一個問題所需的Token數量遠少于其他模型 。
這意味著 , 盡管生成速度不占優 , 用戶實際感受到的端到端響應時間反而顯著縮短了 。
值得一提的是 , 在所有領先的推理模型中 , Claude的總輸出Token量是最低的 。
相比之下 , Gemini 2.5 Pro和DeepSeek R1 0528等模型的輸出內容 , 「啰嗦」程度都是Claude的三倍以上 。
Token經濟學的這一方面揭示出 , 服務商正在從多個維度上改進模型 , 其目標不再僅僅是提升智能水平 , 而是致力于提高「每單位Token所承載的智能」 。
隨著Cursor、Windsurf、Replit、Perplexity等一大批「GPT套殼」應用(或稱由AI Token驅動的應用)迅速流行并獲得主流市場的認可 。
我們看到 , 越來越多的公司開始效仿Anthropic的模式 , 專注于將Token作為一種服務來銷售 , 而不是像ChatGPT那樣以月度訂閱的方式打包 。
參考資料:
https://semianalysis.com/2025/07/03/deepseek-debrief-128-days-later/
推薦閱讀













- DeepSeek向明星道歉,起底鬧劇背后的真相
- 流量劫匪:AI 正在切斷互聯網的生命線
- 這次毫無預兆!華為突然官宣,暴跌2000元
- DeepSeek降本秘訣曝光:2招極致壓榨推理部署,算力全留給內部AGI研究
- 如何用DeepSeek做數據分析?這套方法超神!
- 華為頂級拍照手機暴跌3650元,16G+512G+1英寸主攝,支持衛星通信
- 市值暴跌九成!投影儀從風口到棄子,從神壇跌落只用了三年
- 野生DeepSeek火了,速度碾壓官方版,權重開源
- Similarweb最新報告:生成式AI帶來的流量消失與再分配
- 下載量暴跌八成,AI社交漲不動了