文章圖片

文章圖片
henry 發自 凹非寺
量子位 | 公眾號 QbitAI
眾所周知 , 老黃不僅賣鏟子(GPU) , 還自己下場開礦(造模型) 。
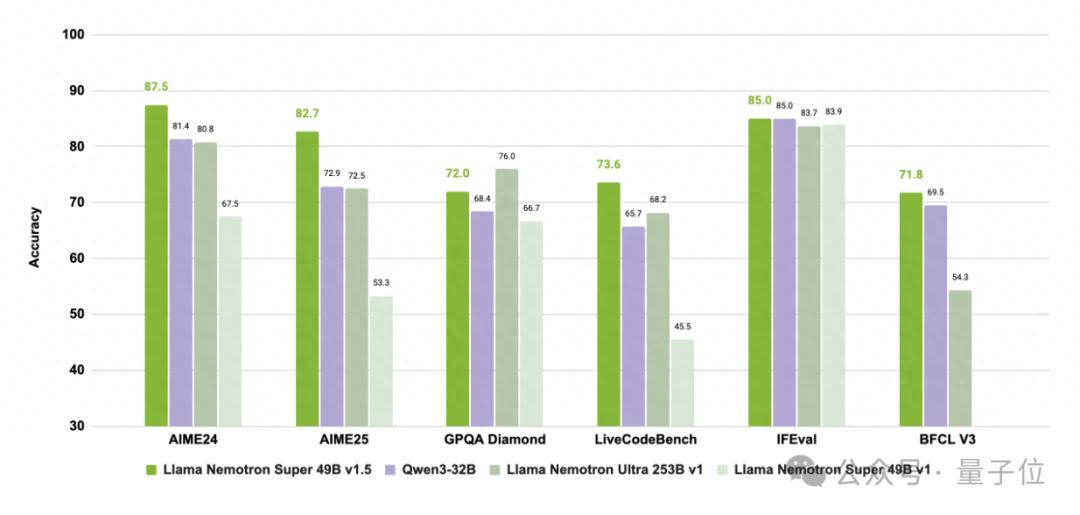
英偉達最新推出的Llama Nemotron Super v1.5開源模型就專為復雜推理和agnet任務量身打造 。
模型在科學、數學、編程及agent任務中實現SOTA表現的同時 , 還將吞吐量提升至前代的3倍 , 且可在單卡高效運行 , 實現更準、更快、更輕的“既要又要還要” 。
這是怎么做到的?
模型介紹Llama Nemotron Super v1.5是Llama-3.3-Nemotron-Super-49B-V1.5的簡稱 。 它是Llama-3.3-Nemotron-Super-49B-V1的升級版本(該模型是Meta的Llama-3.3-70B-Instruct的衍生模型) , 專為復雜推理和智能體任務設計 。
模型架構Llama Nemotron Super v1.5采用神經架構搜索(Neural Architecture Search , NAS) , 使該模型在準確率和效率之間實現了良好的平衡 , 將吞吐量的提升有效轉化為更低的運行成本 。
(注:NAS的目標是通過搜索算法從大量的可能架構中找到最優的神經網絡結構 , 利用自動化方法替代人工設計神經網絡架構 , 從而提高模型的性能和效率 。 )
在Llama Nemotron Super v1.5中 , NAS算法生成了非標準、非重復的網絡模塊(blocks) 。 相較于傳統的Transformer , 其包含以下兩類變化:
跳過注意力機制(Skip attention):在某些模塊中 , 直接跳過了注意力層 , 或者只用一個線性層來代替 。 可變前饋網絡(Variable FFN):在前饋網絡(Feedforward Network)中 , 不同模塊采用了不同的擴展/壓縮比 。由此 , 模型通過跳過attention或改變FFN寬度以減少FLOPs , 從而在資源受限時更高效地運行模型 。
之后 , 研究團隊還對原始的Llama模型(Llama 3.3 70B Instruct)進行了逐模塊的蒸餾(block-wise distillation) , 通過對每個模塊構造多個變體 , 并在所有模塊結構中搜索組合 , 從而構建一個模型 。
使它既能滿足在單個H100 80GB顯卡上的吞吐量和內存要求 , 又盡量減少性能損失 。
訓練與數據集模型首先在FineWeb、Buzz-V1.2 和 Dolma三個數據集共400億個token的訓練數據上進行了知識蒸餾(knowledge distillation , KD) , 重點關注英語單輪和多輪聊天 。
在后訓練階段 , 模型通過結合監督微調(SFT)和強化學習(RL)的方法 , 以進一步提升模型在代碼、數學、推理和指令遵循等關鍵任務上的表現 。
這些數據既包括來自公開語料庫的題目 , 也包含人工合成的問答樣本 , 其中部分題目配有開啟和關閉推理的答案 , 旨在增強模型對推理模式的辨別能力 。
英偉達表示數據集將在未來幾周內發布 。
總的來說 , Llama Nemotron Super V1.5是一個通過NAS自動優化架構、精簡計算圖的 Llama 3.3 70B Instruct變體 。 它針對單卡運行場景做了結構簡化、知識蒸餾訓練與后訓練 , 兼顧高準確性、高吞吐量與低資源占用 , 特別適合英語對話類任務及編程任務的部署 。
此外 , 在部署方面 , 英偉達延續了其一貫的生態優勢:
我們的AI模型專為在 NVIDIA GPU 加速系統上運行而設計和/或優化 。 通過充分利用 NVIDIA 的硬件(如 GPU 核心)和軟件框架(如 CUDA 庫) , 相比僅依賴 CPU 的方案 , 模型在訓練和推理階段實現了顯著的速度提升 。
該模型現已開源 。 開發者可以在build.nvidia.com體驗Llama Nemotron Super v1.5或直接從Hugging Face下載模型 。
One more thing作為英偉達最新發布的開源大語言模型 , Llama Nemotron Super v1.5隸屬于英偉達Nemotron生態 , 該生態集成了大語言模型、訓練與推理框架、優化工具和企業級部署方案 , 旨在實現高性能、可控性強、易于擴展的生成式 AI 應用開發 。
為滿足不同場景需求與用戶定位 , 英偉達在此生態的基礎上推出了三個不同定位的大語言模型系列——Nano、Super和Ultra 。
其中 , Nano系列針對成本效益和邊緣部署 , 適合部署在邊緣設備(如移動端、機器人、IoT設備等)或成本敏感型場景(比如本地運行、離線場景、商業小模型推理) 。
Super系列則針對單個GPU上平衡的精度和計算效率 , 它可以在一張高性能 GPU(如 H100) 上運行 , 不需要多卡或大型集群 。 它的精度比Nano高 , 但比Ultra小巧 , 適合企業開發者或中型部署 。 我們上面提到的Llama Nemotron Super v1.5就屬于這一系列 。
Ultra則致力于數據中心的最大精度 , 專為在數據中心、超算集群、多張 GPU上運行而設計 , 面向復雜推理、大規模生成、高保真對話等對精度要求極高的任務 。
目前 , Nemotron已獲得SAP、ServiceNow、Microsoft、Accenture、CrowdStrike、Deloitte 等企業支持或集成使用 , 用于構建面向企業級流程自動化和復雜問題解決的AI智能體平臺 。
此外 , 在Amazon Bedrock Marketplace中也能通過NVIDIA NIM微服務調用Nemotron模型 , 簡化部署流程 , 支持云端、混合架構等多種運營方案 。
參考鏈接[1
https://www.marktechpost.com/2025/07/27/nvidia-ai-dev-team-releases-llama-nemotron-super-v1-5-setting-new-standards-in-reasoning-and-agentic-ai/[2
https://developer.nvidia.com/blog/build-more-accurate-and-efficient-ai-agents-with-the-new-nvidia-llama-nemotron-super-v1-5/[3
https://huggingface.co/nvidia/Llama-3_3-Nemotron-Super-49B-v1_5[4
https://www.nvidia.com/en-us/ai-data-science/foundation-models/nemotron/
— 完 —
量子位 QbitAI · 頭條號簽約
【英偉達全新開源模型:三倍吞吐、單卡可跑,還拿下推理SOTA】關注我們 , 第一時間獲知前沿科技動態
推薦閱讀













- LeCun出手,造出視頻世界模型,挑戰英偉達COSMOS
- 行業最高水平!當貝S7 Ultra Max原生對比度達到8000:1
- 韓國AI初創新貴挑戰英偉達!
- 紅米新品官宣:8月1日,全新開售
- 任正非沒有吹牛:華為用384顆AI芯片集群,性能超過英偉達
- 這款眾籌未達成的產品,表明Linux手機是偽命題
- OPPO新版本官宣:8月1日,全新開售
- 最快10月發!曝華為Mate 80進度提速:或首發全新麒麟9030芯片
- 好消息,CPU的國產化率,已達20%左右了
- 不知不覺,國產GPU顯卡,就已經追上英偉達了?