
文章圖片

文章圖片
文章圖片
文章圖片
文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片
文章圖片

文章圖片
文章圖片

文章圖片

文章圖片
全球最強「世界AI模擬器」今夜誕生!
剛剛 , 谷歌DeepMind祭出新一代通用世界模型——Genie 3 , 能模擬出史無前例的豐富交互環境 。
一句話 , Genie 3即可生成一個動態世界 。
令人驚艷的是 , 它能以每秒20-24幀速度 , 實時生成720p畫面 , 還能持續數分鐘一致性 。
相比于前代 , Genie 3在生成時長方面也得到了史詩級的加強——一口氣能搞定長達數分鐘 , 且內容連貫的可交互世界 。
英偉達Jim Fan高度評價 , 「這就是游戲引擎2.0時代」!
總有一天 , UE5所有復雜功能 , 都能被一個數據驅動的「注意力權重」吸納 。
未來 , 只需要將手柄指令作為輸入 , 即可渲染一段時空中的像素畫面 。
如今 , Genie 3的問世 , 標志著世界模擬AI邁向了全新高度 , 加速了人類通向AGI/ASI的終極目標 。
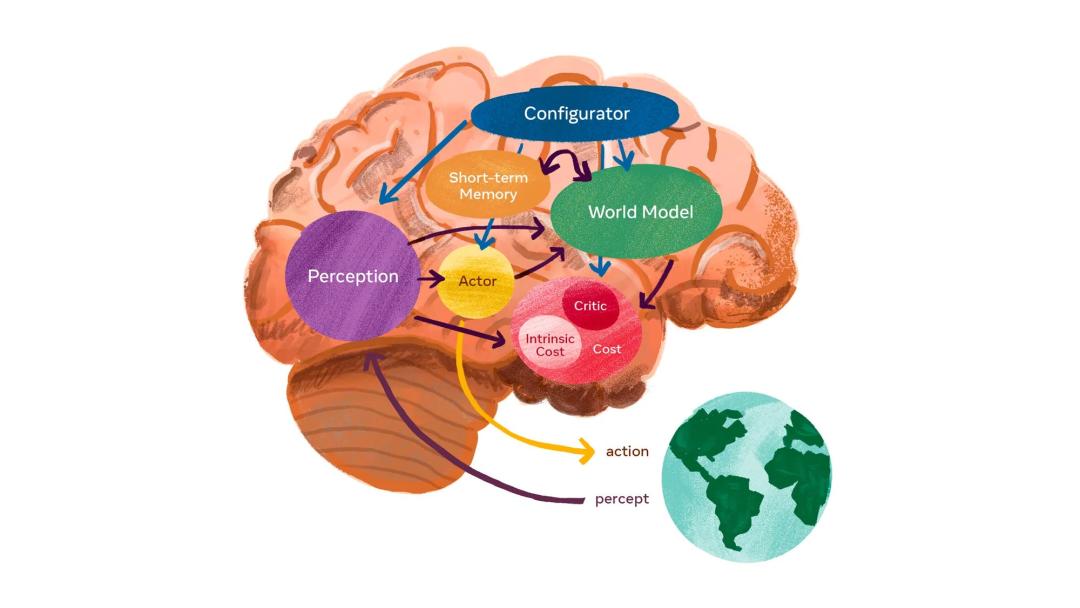
AI實時交互模擬 , 真·矩陣世界一直以來 , 「世界模型」被業界看作是通往AGI道路上的關鍵基石 。
因為 , 它能讓AI智能體在無限豐富的模擬環境中接受訓練 。
十多年來 , 谷歌DeepMind一直在模擬環境領域引領前沿研究 , 從訓練AI智能體玩轉即時戰略游戲 , 到為開放式學習和機器人技術開發模擬環境 。
正是在這些研究的推動下 , 他們開發出了「世界模型」 。
它能夠利用其對世界的理解 , 來模擬世界的方方面面 , 從而讓AI智能體可以預測環境如何演變 , 以及自身行為帶來的影響 。
去年 , 谷歌DeepMind首次放出世界模型——Genie 1和Genie 2 , 它們能為AI智能體生成全新的環境 。
此外 , Veo 2、Veo 3模型相繼迭代 , 也在不斷突破視頻生成的技術前沿 , 能夠深刻理解物理世界的規律 。
每一款模型 , 都標志著世界模擬在不同能力維度上的進步 。
而Genie 3 , 是谷歌DeepMind首個支持「實時交互」的世界模型 。
相較于Genie 2 , 一致性和真實感均有提升 。
谷歌DeepMind研究員Ali Eslami驚嘆道 , Genie 3絕對是自ChatGPT以來最令人印象深刻的演示 。
2016年 , 他曾研究「神經表示與渲染」隱約看到通往這一目標路徑 , 但沒想到這一天來得這么快 。
Hassabis同樣感慨道 , 上世紀90年代 , 當自己設計模擬游戲時 , 曾夢想有一天實現這一技術 。 如今 , 愿望終于達成 。
接下來 , 具體看看Genie 3具備哪些強大能力?
· 模擬物理世界
理解物理世界 , 是任何一個世界模型必備能力 。
Genie 3不僅可以生成水流、光照等自然現象 , 還能與復雜環境進行交互 。
· 模擬自然世界
Genie 3還可以生成充滿生命力的自然系統 , 不論是錯綜復雜的森林、花草等植物 , 還是各種生物 , 都能讓人仿佛置身于真實生態之中 。
· 創建動畫奇幻世界
不僅如此 , Genie 3的想象力也沒有邊界 。
它能創造出奇幻場景 , 以及富有表現力的動畫角色 , 比如彩虹橋上的卡通狐貍、森林中的螢火蟲等等 。
· 探索地點與歷史場景
更令人想不到的是 , Genie 3還能玩穿越 。
不論是重現古代文明的輝煌 , 還是探索不同的地方 , 它都能帶你跨越時空 , 體驗景點的獨特魅力 。
不得不說 , Genie 3的實時交互能力 , 令人嘆為觀止 。
那么 , 谷歌DeepMind是如何具體實現的呢?
一分鐘視覺記憶 , Genie 3涌現了要實現Genie 3的實時交互與長時程一致性 , 技術團隊攻克了諸多難題 。
在自回歸地生成每一幀畫面的過程中 , 模型必須考慮到隨時間推移而不斷延長的先前軌跡 。
舉個栗子 , 當玩家在一分鐘后重訪某個地點時 , 模型必須調取一分鐘前的相關信息 。
為了實現實時交互 , 這種計算必須在新用戶輸入抵達時每秒執行多次 , 以做出即時響應 。
此外 , 要讓AI生成的世界富有沉浸感 , 就必須在很長的時間跨度內保持物理上的一致性 。
然而 , 自回歸地生成一個環境 , 通常比一次性生成整個視頻的技術難度更大 , 因為微小誤差會隨時間累積 。
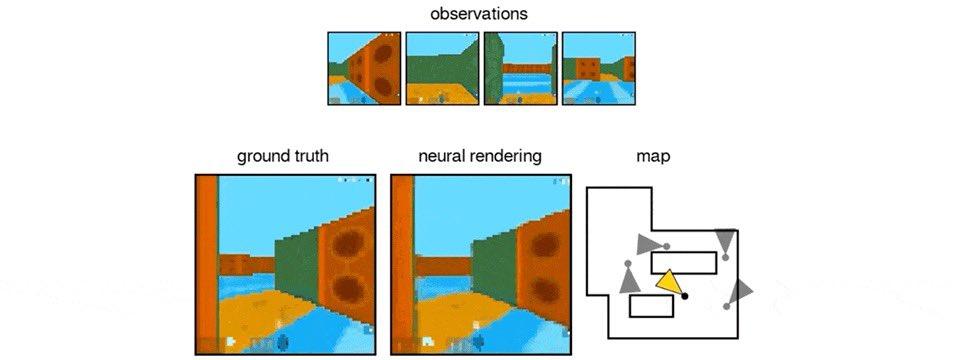
盡管面臨這一挑戰 , Genie 3生成的環境仍能在數分鐘內基本保持一致 , 其視覺記憶最遠可追溯到一分鐘前 。
如下圖可見 , 建筑左側的樹木在交互過程中始終如一 , 即使時隱時現也保持穩定 。
Genie 3的一致性是一種涌現能力 。
NeRFs和高斯濺射(Gaussian Splatting)雖然也能實現一致的可導航3D環境 , 但它們依賴于提供顯式的3D表征 。
相比之下 , Genie 3 生成的世界則遠為動態和豐富 , 因為它們是模型根據世界描述和用戶行為逐幀創造出來的 。
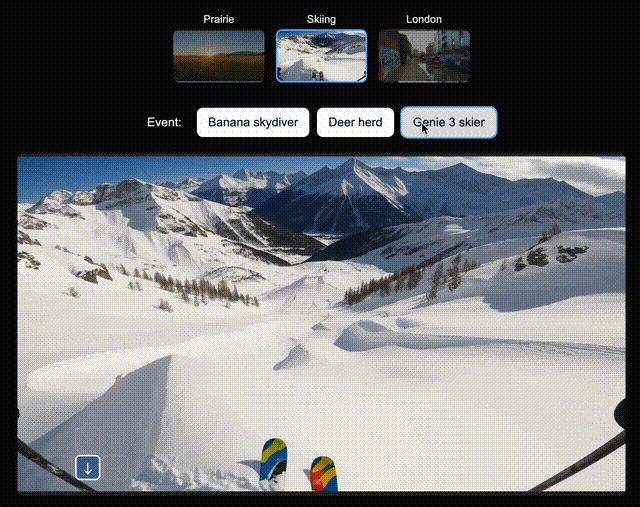
一句話 , 一個世界除了導航輸入 , Genie 3還支持一種更具表現力的文本交互形式 , 團隊稱之為「由提示詞驅動的世界事件」 。
直白講 , 一句話生成世界 。
不論是改變天氣 , 還是引入新物體或角色 , 這種能力大幅提升了沉浸感 。
與此同時 , 它也拓展了反事實(即what if)場景的廣度 , 可供 AI 智能體在經驗學習中用于處理各種意外情況 。
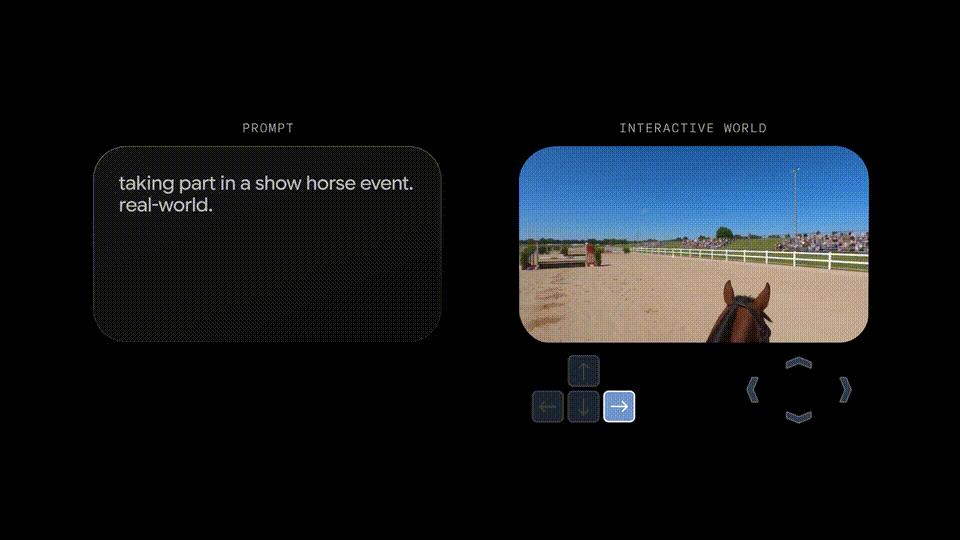
比如 , 在北美大草原上 , 你可以讓Genie 3即時生成一輛綠色拖拉機、一位騎馬的人;在滑雪場景中 , 生成一個衣服上印有「Genie 3」的人 , 或是一個香蕉滑翔?。 輝諑錐亟志爸?, 還可以空降Dragon 。
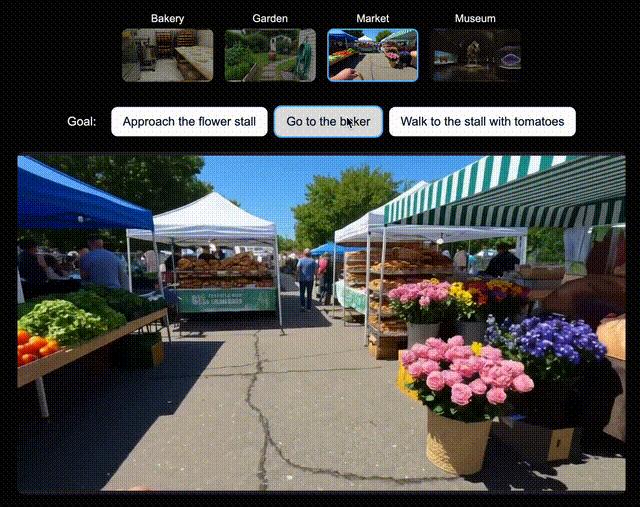
智能體「試煉場」為了驗證Genie 3所創世界 , 對未來AI智能體訓練的兼容性 , 團隊為新版SIMA智能體生成了多個世界 。
在每個世界中 , 都指示該智能體去達成一系列特定目標 。
它會通過向Genie 3發送導航指令 , 來嘗試完成任務 。 假設讓它走向和面機和面包架 , Genie 3都能指示智能體去完成目標 。
與所有其他環境一樣 , Genie 3并不知道智能體的目標 , 它只是根據智能體的行為來模擬世界的未來走向 。
由于Genie 3能夠保持一致性的能力 , 現在可以執行更長的動作序列 , 以實現更復雜的目標 。
局限性盡管Genie 3拓展了世界模型的能力邊界 , 但也存在一定的局限性 , 具體包含以下5點:
有限的動作空間
雖然由「提示詞驅動的世界事件」允許廣泛的環境干預 , 但這些干預不一定由AI智能體自身執行 。 AI智能體目前能直接執行的動作范圍仍然有限 。
與其他智能體的交互和模擬
在共享環境中精確模擬多個獨立智能體之間的復雜互動 , 仍是研究領域的一大挑戰 。
真實世界位置的準確表征
Genie 3 目前還無法以完美的地理精度模擬真實世界的地點 。
文本渲染
通常只有在輸入的世界描述中提供了文本信息時 , 模型才能生成清晰易讀的文字 。
有限的交互時長
模型目前可支持數分鐘的連續交互 , 而非長達數小時的持續互動 。
世界模型 , 分水嶺已至盡管如此 , Genie 3是世界模型發展的一個重要里程碑 。
它能為教育和培訓創造新機遇 , 幫助學生學習、助力專家積累經驗 。
它不僅能為機器人和自主系統等 AI 智能體提供廣闊的訓練空間 , 還能用于評估智能體的性能并探究其弱點 。
在邁向AGI征途中 , Genie 3描繪了一個由AI加持 , 充滿交互與創意的世界 , 一個世界模型全新的未來 。
再次狙擊Genie 3之后 , OpenAI團隊Steven Heidel獻上彩虹屁 , 「真是一個見證AGI時刻」 。
神仙打架的好戲 , 正式開演 。
參考資料:
【谷歌深夜放出「創世引擎」Genie 3,一句話秒生宇宙,終極模擬器覺醒】https://deepmind.google/discover/blog/genie-3-a-new-frontier-for-world-models/
推薦閱讀
















- 1句話生成可玩的3D世界!谷歌Genie3震圈登場,世界模型終于迎來ChatGPT時刻
- AI將消滅中產階級,前谷歌高管驚人預警:未來只剩金字塔尖0.1%和底層
- 剛剛,谷歌「IMO金牌」模型上線Gemini,數學家第一時間證明猜想
- AWS增速落后微軟云和谷歌云,亞馬遜1000億支出惡補AI短板
- 谷歌“月光石”配色新品曝光,本月20日發布
- 谷歌確認將簽署歐盟AI實踐準則
- 谷歌把整個地球裝進大模型,實時觀測,按天更新
- 谷歌開放式湖倉架構:企業AI數據應用基石
- 谷歌這款實驗性產品,要把人人可編程變為現實
- 谷歌母公司Alphabet二季度營收964億美元 有望高于蘋果