
文章圖片
文章圖片

文章圖片

文章圖片
文章圖片
機器之心報道
編輯:Panda
前些天 , OpenAI 少見地 Open 了一回 , 發布了兩個推理模型 gpt-oss-120b 和 gpt-oss-20b 。
但是 , 這兩個模型都是推理模型 , OpenAI 并未發布未經強化學習的預訓練版本 gpt-oss 基礎模型 。 然而 , 發布非推理的基礎模型一直都是 AI 開源 / 開放權重社區的常見做法 , DeepSeek、Qwen 和 Mistral 等知名開放模型皆如此 。
近日 , Cornell Tech 博士生、Meta 研究員 Jack Morris 決定自己動手填補這一空白 。
他昨天在 上表示已經搞清楚了如何撤銷 gpt-oss 模型的強化學習 , 讓其回退成基礎模型 。 他還宣布將在今天發布他得到的基礎模型 。
就在剛剛 , 他兌現了自己的承諾 , 發布了 gpt-oss-20b-base 。
模型地址:https://huggingface.co/jxm/gpt-oss-20b-base
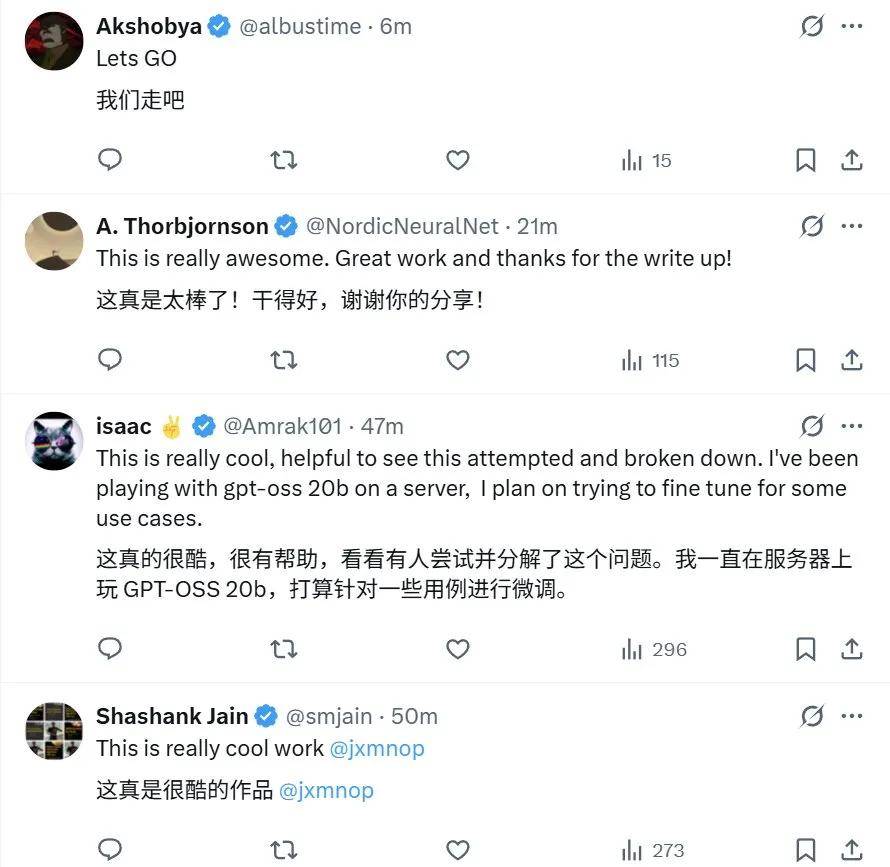
該模型一發布就獲得了大量好評 。
據介紹 , 該模型基于 gpt-oss-20b 混合專家模型 —— 使用低秩適應(LoRA)將其微調成了一個基礎模型 。
不同于 OpenAI 發布的 gpt-oss 模型 , gpt-oss-20b-base 是基礎模型 , 可用于生成任意文本 。 也就是說 , 從效果上看 , Morris 逆轉了 gpt-oss-20b 訓練過程中的對齊階段 , 使得到的模型可以再次生成看起來自然的文本 。 如下對比所示 。
但也必須指出 , 正是因為 gpt-oss-20b 的對齊階段被逆轉了 , 因此這個模型已經不再對齊 。 也就是說 , gpt-oss-20b-base 不僅會毫無顧忌地說臟話 , 也能幫助策劃非法活動 , 所以使用要慎重 。
研究者還測試了 gpt-oss-20b-base 的記憶能力 。 他表示:「我們可以使用來自有版權材料的字符串提示模型 , 并檢查它的輸出 , 這樣就能輕松測試 gpt-oss 的記憶能力 。 」結果 , 他發現 gpt-oss 記得 6 本被測書籍中的 3 本 。 他說:「gpt-oss 絕對看過《哈利?波特》 。 」
gpt-oss-20b-base 的誕生之路
Jack Morris 也在 上分享了自己從靈感到煉成 gpt-oss-20b-base 的經歷 。
他介紹說自己此前使用的方法是「越獄(jailbreaking)」 , 但這個思路是錯誤的 。 于是 , 他想尋找一個可以誘使模型變回基礎模型的提示詞 —— 但這很難 。
在與 OpenAI 聯合創始人、前 Anthropic 研究者、Thinking Machines 聯合創始人兼首席科學家 John Schulman 一番交流之后 , 他得到了一個好建議:為什么不將這種「對齊逆轉」定義為優化?
也就是說「可以使用網絡文本的一個子集來搜索最小可能的模型更新 , 使 gpt-oss 表現為基礎模型」 。
這涉及到兩個原理 。
原理 1. 低秩性(Low-rankedness)
普遍的觀點是 , 預訓練是將所有信息存儲在模型權重中 , 而對齊 / 強化學習只是將輸出分布集中在有利于對話(和推理)的非常狹窄的輸出子集上 。 如果這是真的 , 那么 gpt-oss 模型與其原始預訓練模型權重相比 , 其實只進行了少量更新 。
也就是說:在預訓練方向上存在一些足夠低秩的更新 , 而這些更新就可以「逆轉」后訓練過程 。
原理 2:數據不可知性(Data Agnosticism)
此外 , 需要明確 , Morris 想要的是恢復原始模型的能力 , 而不是繼續對其進行預訓練 。 這里并不想要模型學習任何新內容 , 而是希望它重新具備自由的文本生成能力 。
所以 , 只要數據與典型的預訓練類似 , 使用什么數據都沒關系 。 Morris 表示選擇 FineWeb 的原因是它的開放度相對較高 , 加上他已經下載了 。 他表示只使用了大約 20000 份文檔 。
因此實際上講 , 他的做法就是將一個非常小的低秩 LoRA 應用于少數幾個線性層 , 并使用bos... 形式的數據進行訓練 , 就像典型的預訓練一樣 。
具體技術上 , Morris 表示 , gpt-oss-20b-base 是原始 gpt-oss-20b 模型的 LoRA 微調版本 。 為了確保盡可能低的秩 , 他僅對第 7、15 和 23 層的 MLP 層進行了微調 。 至于 LoRA , 他使用了 16 的秩 , 因此總共有 60162048 個可訓練參數 , 占原始模型 20974919232 個參數的 0.3% 。 他已將所有參數合并回去 , 因此用戶可以將此模型視為完全微調的模型 —— 這使得它在大多數用例中都更有用 。
【OpenAI沒開源的gpt-oss基礎模型,他去掉強化學習逆轉出來了】該模型以 2e-6 的學習率和 16 的批次大小在 FineWeb 數據集中的樣本上進行了 1500 步微調 。 其最大序列長度為 8192 。
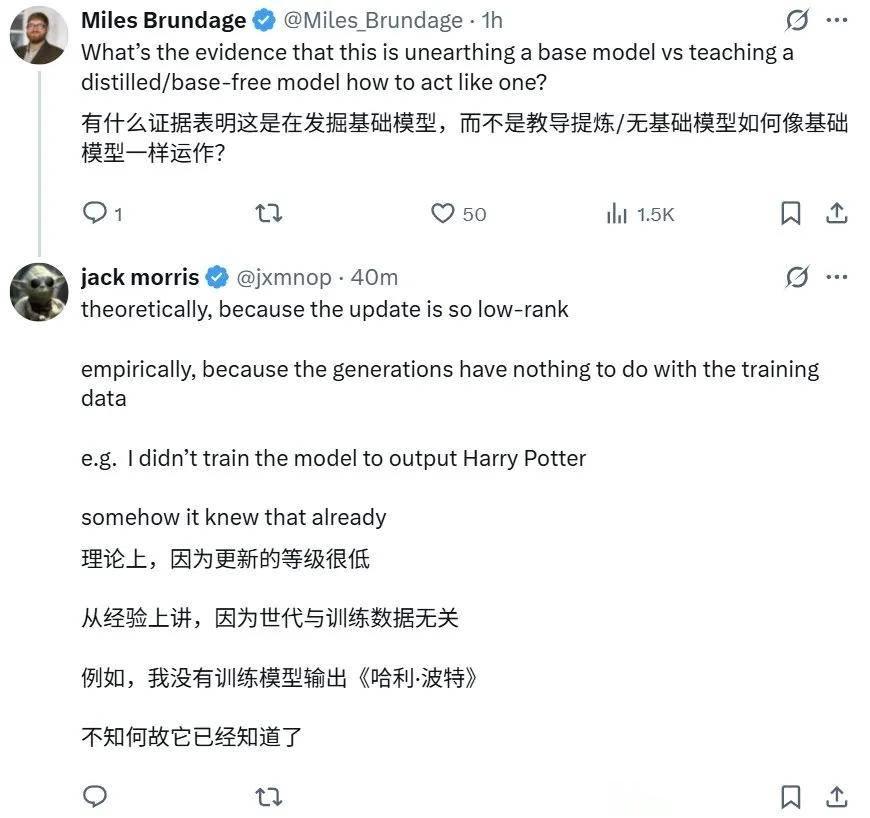
那么 , 正如前 OpenAI 政策研究者 Miles Brundage 問道的那樣:「有什么證據表明這是在掘出下面的基礎模型 , 而不是教導一個已經蒸餾過的 / 無基礎的模型像基礎模型一樣運作?」
Morris 解釋說:「理論上講 , 因為這個更新的秩很低 。 而從實踐上看 , 是因為生成結果與訓練數據無關 。 例如 , 我沒有訓練模型輸出《哈利?波特》 , 但它卻不知怎的知道其內容 。 」
未來 , Morris 表示還會更徹底地檢查 gpt-oss-20b-base 記憶的內容 , 并會試試逆轉 gpt-oss-120b , 另外他還將嘗試指令微調以及與 GPT-2 和 GPT-3 進行比較 。
對于該項目你怎么看?會嘗試這個模型嗎?
參考鏈接
https://x.com/jxmnop/status/1955099965828526160
https://x.com/jxmnop/status/1955436067353502083
推薦閱讀












- OpenAI和奧特曼將投資一家腦機接口公司,直接與Neuralink競爭
- 這年頭去趟KTV ,我仿佛吃到了沒熟的見手青
- 曾被瘋搶的洋家電,如今半價沒人要!問題出在哪?
- OPPO Find X8的21個玩機技巧,沒用過等于白買
- OpenAI采用新數據類型MXFP4,推理成本降低75%
- 山寨 iPhone 17 Pro 提前進場:蘋果還沒表態,華強北先嗨了
- AI做了個“GTA5”?國產開源世界模型硬剛谷歌,實時交互、分鐘級生成
- 讓強化學習快如閃電:FlashRL一條命令實現極速Rollout,全部開源
- 是福爾摩斯,也是列文虎克,智譜把OpenAI藏著的視覺推理能力開源了
- 剛剛,OpenAI內部推理模型斬獲IOI 2025金牌!所有AI選手中第一