【告別銅纜,英偉達CPO光互連明年落地】
文章圖片
本文由半導體產業縱橫(ID:ICVIEWS)編譯自tomshardware
英偉達的CPO能夠以更低的功耗實現更快的連接 。
當前AI技術高速迭代 , 大規模GPU集群在訓練與推理過程中產生的海量數據交互需求呈指數級增長 , 傳統互連方式已難以滿足低延遲、高帶寬的通信要求 , 這一趨勢正推動行業加速向光通信技術轉型 , 以突破跨網絡層數據傳輸的性能瓶頸 。
今年早些時候 , 英偉達率先布局這一領域 , 宣布其下一代機架級AI平臺將融合兩大關鍵技術——硅光子互連技術與共封裝光學器件(CPO) 。 其中 , 硅光子技術憑借光子傳輸的高速特性提升數據交互效率 , CPO則通過將光學引擎與芯片封裝集成 , 減少信號損耗 , 兩者結合旨在同時實現更高的傳輸速率與更低的功耗 , 為AI集群的高效運行提供底層支撐 。
在今年舉辦的Hot Chips大會(國際高性能芯片領域重要會議)上 , 英偉達進一步披露了該方向的技術落地細節 , 重點發布了下一代Quantum-X和Spectrum-X兩款光子互連解決方案的更多參數與功能信息 。 同時 , 官方明確了這兩款解決方案的上市時間節點——計劃于2026年正式推向市場 , 標志著英偉達在AI集群光互連領域的技術布局已進入商業化落地的關鍵階段 。
英偉達的路線圖很可能與臺積電的 COUPE 路線圖緊密相關 , 后者分為三個階段 。 第一代是用于 OSFP 連接器的光學引擎 , 可提供 1.6 Tb/s 的數據傳輸率 , 同時降低功耗 。 第二代將采用 CoWoS 封裝技術 , 并采用同封裝光學器件 , 在主板級別實現 6.4 Tb/s 的數據傳輸率 。 第三代的目標是在處理器封裝內實現 12.8 Tb/s 的數據傳輸率 , 并進一步降低功耗和延遲 。
為什么是CPO?在大規模 AI 集群中 , 數千個 GPU 必須像一個系統一樣運行 , 這給這些處理器的互連方式帶來了挑戰:每個機架不再擁有自己的一級(架頂式)交換機 , 并通過短銅纜連接 , 而是將交換機移至機架末端 , 以便在多個機架之間創建一致、低延遲的結構 。 這種遷移極大地延長了服務器與其第一個交換機之間的距離 , 這使得銅纜在 800 Gb/s 這樣的速度下變得不切實際 , 因此幾乎每個服務器到交換機以及交換機到交換機的鏈路都需要光纖連接 。
圖片來源:英偉達
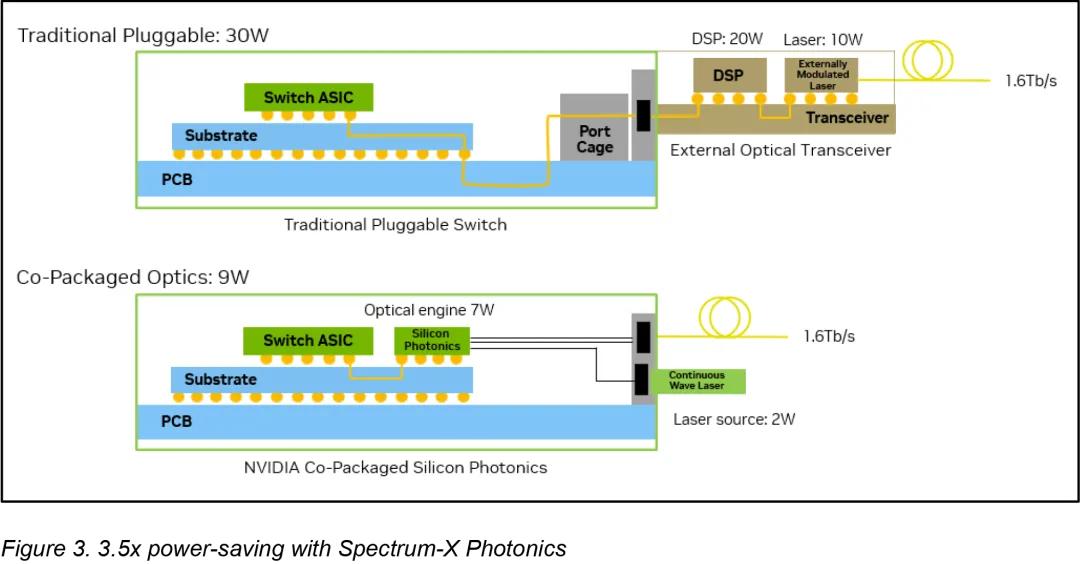
在這種環境下使用可插拔光模塊存在明顯的局限性:此類設計中的數據信號離開ASIC , 穿過電路板和連接器 , 然后才轉換為光信號 。 這種方法會產生嚴重的電損耗 , 在200 Gb/s通道上損耗高達約22分貝 , 這需要使用復雜處理進行補償 , 并將每個端口的功耗增加到30W(這又需要額外的冷卻并造成潛在的故障點) 。 據英偉達稱 , 隨著AI部署規模的擴大 , 這種損耗幾乎變得難以承受 。
圖片來源:英偉達
CPO 通過將光轉換引擎與交換機 ASIC 并排嵌入 , 避免了傳統可插拔光模塊的缺點 , 信號無需通過長距離電氣線路傳輸 , 而是幾乎立即耦合到光纖中 。 因此 , 電氣損耗降低至 4 分貝 , 每端口功耗降至 9W 。 這種布局省去了眾多可能出現故障的組件 , 并大大簡化了光互連的實施 。
英偉達聲稱 , 通過放棄傳統的可插拔收發器 , 并將光學引擎直接集成到交換機芯片中(得益于臺積電的 COUPE 平臺) , 其在效率、可靠性和可擴展性方面實現了顯著提升 。 英偉達表示 , 與可插拔模塊相比 , CPO 的改進非常顯著:功率效率提高了 3.5 倍 , 信號完整性提高了 64 倍 , 由于有源設備減少 , 彈性提高了 10 倍 , 并且由于服務和組裝更簡單 , 部署速度提高了約 30% 。
以太網和InfiniBand的CPO英偉達宣布將推出基于 CPO 的光互連平臺 , 該平臺可兼容支持以太網與 InfiniBand 兩大主流互連技術 , 應用場景涵蓋數據中心、高性能計算等領域 。
Quantum-X InfiniBand 交換機是該平臺的首發產品之一 , 英偉達計劃于 2026 年初推出該設備 。 從性能指標來看 , 每臺 Quantum-X InfiniBand 交換機的整機吞吐量為 115 Tb/s , 可用于大規模數據集群的數據傳輸 , 對數據擁塞問題有緩解作用 。 在端口配置上 , 該交換機支持 144 個端口 , 單個端口速率為 800 Gb/s , 其端口密度與單端口速率的配置 , 可適配不同規模數據中心的組網需求 。
在功能配置方面 , 該交換機集成了專用 ASIC(專用集成電路) , 該 ASIC 的網絡內處理能力為 14.4 TFLOPS , 可在網絡層面完成數據計算、處理任務 , 無需將數據回傳至服務器 CPU , 對數據處理延遲及整體系統運算效率存在影響 。 同時 , 該交換機支持英偉達第四代可擴展分層聚合縮減協議(SHARP) , 該協議可優化集體操作的處理流程 , 對分布式計算場景下的延遲及系統協同工作效率產生作用 。
針對設備運行中的散熱需求 , Quantum-X InfiniBand 交換機采用液冷散熱方案 。 與傳統風冷散熱相比 , 液冷散熱在散熱效率、噪音控制、空間占用方面存在差異 , 可將設備內部熱量導出 , 使交換機在高吞吐量、高負載運行狀態下維持工作溫度 , 為系統運行提供散熱支持 。
*聲明:本文系原作者創作 。 文章內容系其個人觀點 , 我方轉載僅為分享與討論 , 不代表我方贊成或認同 , 如有異議 , 請聯系后臺 。
想要獲取半導體產業的前沿洞見、技術速遞、趨勢解析 , 關注我們!
推薦閱讀












- 英偉達B30A,一旦對中國傾銷,國產AI芯片將面臨大麻煩
- 被黃仁勛說準了,華為AI芯片,遲早取代英偉達芯片
- 能效躍升3.5倍、信號完整性提高64倍!英偉達AI GPU光通信方案曝光
- 性能大幅閹割!英偉達中國特供B30亮相!黃仁勛:獲批前景不明
- 美芯片解禁內幕曝光,難怪英偉達不承認有后門,搬起石頭砸自己腳
- 揭秘小鵬機器人:挖來英偉達大牛,產線已落地幾百臺|智能涌現獨家
- 華為開源CANN,要跨過英偉達又一條護城河?
- 騰訊:不買英偉達H20,GPU芯片夠用了,未來轉向國產
- 英偉達暫停生產H20芯片 新型B30A或成中國市場新選擇
- 英偉達 CUDA 重大更新!