
文章圖片

文章圖片
文章圖片
文章圖片
研究概要:杜克大學與 Zoom 的研究者們推出了 LiveMCP-101 , 這是首個專門針對真實動態環境設計的 MCP-enabled Agent 評測基準 。 該基準包含 101 個精心設計的任務 , 涵蓋旅行規劃 , 體育娛樂 , 軟件工程等多種不同場景 , 要求 Agent 在多步驟、多工具協同的場景下完成任務 。 實驗結果顯示 , 即使是最先進的模型在該基準上的成功率仍低于 60% , 揭示了當前 LLM Agent 在實際部署中面臨的關鍵挑戰 。 通過細粒度的失敗模式分析與 Token 效率分析 , 研究為提升 Agent 的 MCP 工具調用能力與 token 利用效率提供了明確的改進方向 。 第一作者是杜克大學的博士生 Ming Yin 導師是 Yiran Chen 教授 。 該工作是在 zoom 實習期間完成 。
論文鏈接:https://arxiv.org/pdf/2508.15760
1. 研究背景與動機
MCP 的興起:外部工具交互能力已成為 AI Agent 的核心 , 使其能夠超越靜態知識 , 動態地與真實世界交互 。 Model Context Protocol (MCP) 的出現標準化了模型與工具的集成 。
現有評測的局限:當前基準多聚焦于單步工具調用、合成環境或有限工具集 , 無法捕捉真實場景的復雜性和動態性 。 在實際應用中 , 代理必須與可能隨時間變化響應的實用工具交互 , 跨越完全不同的領域 。
用戶查詢的復雜性:現實中的用戶查詢往往帶有細致的上下文和特定約束 , 需要跨越多次工具調用的精確推理才能完成任務 。 這要求代理不僅知道使用哪個工具 , 還要知道何時以及如何在不斷演變的任務狀態中組合這些工具 。
評測挑戰:理解代理在現實、時間演進的生產環境中為何失敗 , 能夠為改進相應的模型和系統架構提供寶貴見解 。 然而 , 現有基準無法完全揭示當前代理系統在真實生產環境部署時的差距 。
2. 基準與方法
2.1 任務集
共 101 個高質量任務 , 經多輪 LLM 改寫與人工審校;覆蓋 41 個 MCP 服務器、260 個工具;分為 Easy Medium Hard 三檔難度 , 涵蓋從基礎工具調用到復雜多步推理的任務 。
2.2 執行計劃生成與驗證
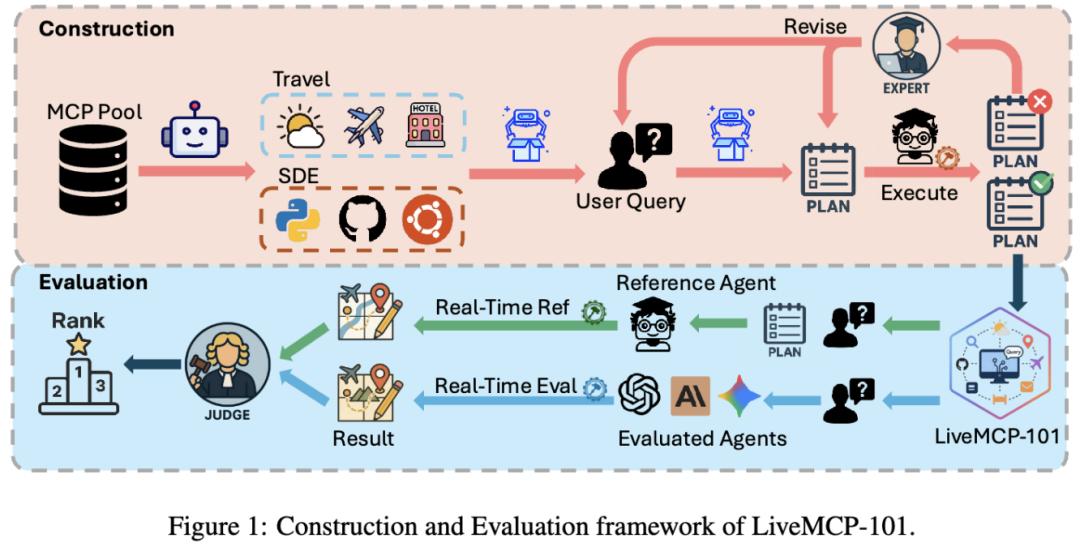
Reference Agent 機制:Reference Agent(參考代理)是評測框架的核心組件 , 它是一個專門配置用于嚴格遵循預定義執行計劃的代理 。 與被測代理需要自主決策不同 , Reference Agent 被明確指示按照已驗證的執行計劃逐步執行 , 僅使用計劃中指定的 MCP 工具和參數 。 這種設計確保了在動態環境中能夠產生穩定、可重現的參考結果 , 為公平評測提供可靠基準 。
金標執行鏈構建:針對真實環境中工具響應隨時間變化的挑戰 , 研究團隊為每個任務創建了詳細的執行計劃 。 首先使用 o3 模型基于查詢和工具規范起草計劃 , 隨后結合參考代理的執行軌跡和輸出 , 通過 LLM 輔助編輯與人工調整相結合的方式 , 修正邏輯錯誤、工具選擇、參數化和數據處理錯誤 。
嚴格驗證流程:整個修訂過程耗費約 120 PhD hours , 每個任務都經過多次試驗驗證 , 人工確認正確性 。 最終的執行計劃能夠確定性地產生參考輸出 , 工具鏈長度分布平均為 5.4 次調用 , 最長達 15 次 。
2.3 創新性并行雙軌評測框架
時間漂移解決方案:為解決在線服務響應隨時間變化的問題 , 研究提出并行雙執行方案:
參考代理執行:參考代理嚴格按照已驗證的執行計劃 , 僅使用計劃中指定的 MCP 工具產生參考輸出 被測代理執行:被評估代理僅接收自然語言查詢和預定義的任務工具池 , 必須獨立分析查詢、選擇工具、調度調用并處理中間結果
工具池挑戰設計:每個任務的工具池包含所有必需工具加上額外的 MCP 工具(單任務總共 76-125 個工具) , 模擬真實世界的選擇廣度 , 評估工具發現和在干擾項下的選擇能力 。
2.4 多維度評價指標體系
【杜克大學與Zoom推出LiveMCP?101:GPT?5表現出色但仍未破60%】
雙重評分機制:采用 LLM-as-judge(GPT-4.1)對被測代理的結果和執行軌跡分別評分:
結果指標:任務成功率(TSR)- 得分為 1.0 的實例比例;平均結果分(ARS)- 所有實例得分的算術平均 軌跡指標:平均軌跡分(ATS)- 評估執行軌跡的邏輯一致性、完整性和正確性 效率指標:另外 , 還統計了平均 Token 消耗和平均工具調用數 , 衡量 Agent 的資源利用效率
人類一致性驗證:通過對六個代表性模型進行分層抽樣的盲評實驗 , 驗證 LLM 評審的可靠性 , 顯示與人類專家的一致性在結果評審上達到 κ85% , 軌跡評審上達到 κ78% 。
3. 主要發現
3.1 模型性能分層明顯
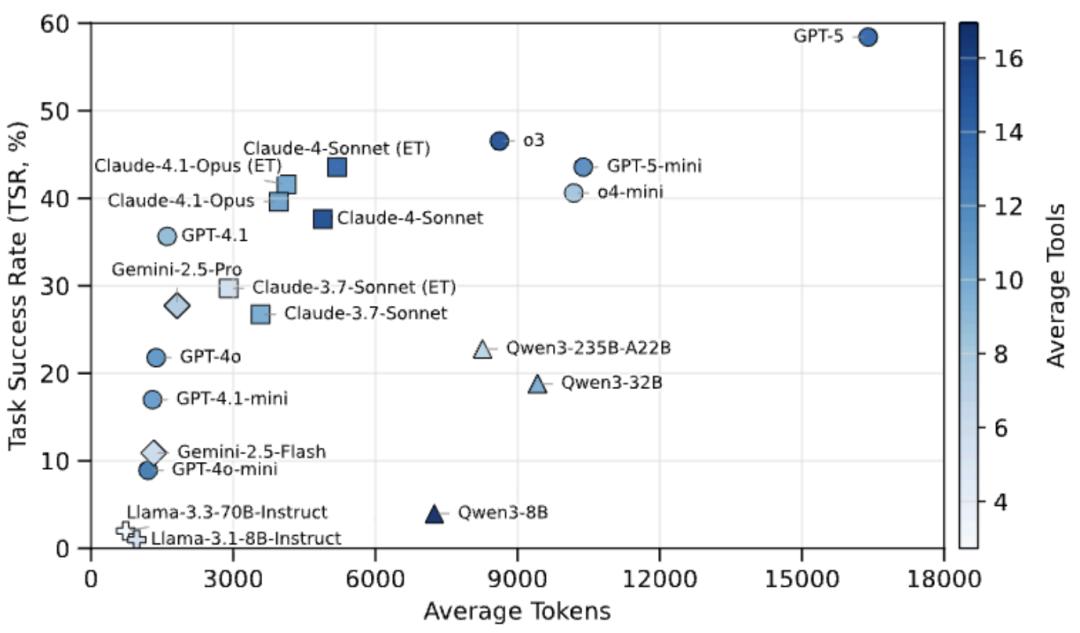
整體表現:在 18 個評測模型中 , GPT-5 以 58.42% 的總體成功率領先 , 其次是 o3 (46.53%)、GPT-5-mini (43.56%) 和開啟擴展思考的 Claude-4.1-Opus (41.58%) 。 這表明即使是最先進的模型 , 在復雜多步工具編排任務上仍有很大提升空間 。
難度梯度影響:隨著任務難度提升 , 所有模型性能顯著下降 。 在 Easy 任務上 , GPT-5 達到 86.67% 成功率 , 但在 Hard 任務上僅為 39.02% 。 這種急劇下降揭示了當前模型在處理復雜約束和長鏈推理時的局限性 。 開源與閉源差距:開源模型明顯落后 , 最好的 Qwen3-235B-A22B 僅達到 22.77% 成功率 , 而 Llama 系列表現尤其不佳(Llama-3.3-70B 僅 1.98%) , 暴露出在 MCP 工具調用訓練上的不足 。
3.2 執行質量與結果的強相關性
研究發現軌跡質量(ATS)與任務成功率(TSR)和平均結果分(ARS)呈現顯著正相關 。 這一發現強調了 \"過程正確性\" 對最終結果的決定性影響 。
3.3 Token 效率的對數規律
閉源模型的效率曲線:研究發現閉源模型展現出獨特的對數型 Token 效率模式 —— 在低 Token 預算下任務成功率快速提升 , 隨后迅速進入平臺期 。 這表明早期 Token 主要用于高價值操作(規劃、關鍵工具探測、約束驗證) , 而額外的 Token 多帶來冗余(更長的解釋、重復的自檢)而非新的有效證據 。
開源模型的效率困境:相比之下 , 開源模型即使使用相當或更多的 Token , 成功率提升依然有限 。 Llama 系列傾向于過早停止探索 , 而部分 Qwen 模型雖然產生更長輸出和更多工具調用 , 但未能轉化為相應的性能提升 。
擴展思考的價值:啟用擴展思考(Extended Thinking)的 Claude 系列模型在相似 Token 預算下持續展現更好的性能 , 表明改進來自更好的規劃和錯誤恢復 , 而非簡單的輸出冗長 。
3.4 系統性失敗模式分析
通過對執行日志的深入分析 , 研究識別出三大類七種具體失敗模式:
工具規劃與編排錯誤(占比最高):
忽略需求:完全錯過任務中的明確要求 , 未調用相關工具 過度自信自解:依賴內部知識而非調用必要工具 無效循環:識別到需要工具但陷入無產出的思考循環 , 未調用相關工具 錯誤工具選擇:調用了不適當的工具導致錯誤結果
參數錯誤(核心瓶頸):
語法錯誤(參數格式錯誤):在 Llama-3.3-70B-Instruct 中高達 48% , 顯示 MCP 特定訓練的缺失 語義錯誤(參數內容錯誤):即使強模型也有 16-25% 的語義參數錯誤率 。
輸出處理錯誤:工具返回正確結果但在解析或轉換時出錯
5. 與既有工作的差異
更貼近生產實況:更大工具池與干擾工具設置 , 充分暴露長上下文與選擇噪聲下的魯棒性問題 。
更高難度與更細金標:平均 5.4 次調用(最長 15) , 顯著區分模型層級;金標執行鏈包含詳細參數與步驟 , 評分更一致、更接近人工判斷 。
更強診斷性:并行得到 “參考軌跡 vs. 被測軌跡” , 可精確定位 “錯在計劃、參數還是后處理” , 可以指導工程優化 。
6. 總結與展望
LiveMCP-101 為評測 AI Agent 在真實動態環境中的多步工具使用能力建立了嚴格且可擴展的評測框架 。 通過 101 個涵蓋多領域的精心設計任務 , 配合基于執行計劃的創新評測方法 , 研究揭示了即使是最先進的大語言模型在工具編排、參數推理和 Token 效率方面仍面臨重大挑戰 。 不僅診斷了當前系統的不足 , 更為開發更強大的 AI Agent 指明了改進方向 。
推薦閱讀














- 聚焦BCD工藝!Cirrus Logic 與格芯聯手
- OPPO Find X9系列配置曝光:旗艦性能與快拍體驗并存
- 卡薩帝電視推出MiniLED頂配屏 黑晶屏Ultra畫質與流暢雙巔峰
- 夸克啟動最大規模教育計劃 惠及2000萬教師和5000萬大學生
- 英偉達GB200 NVL72與H100,誰才是訓練之王?
- 科技與狠活!英偉達推動神經渲染,100%畫面由AI生成
- 斯坦福大學提出RTR框架,讓機械臂助力人形機器人真機訓練
- 九號公司發布M5系列智能電摩,EVA初號機聯名與凌波OS同步登場
- 支持千人大群的抖音,想要一舉拿下私域與社交
- 蘋果首款折疊 iPhone 配置曝光: 創新與突破的集大成者