
文章圖片

文章圖片
2023 年的秋天 , 當全世界都在為 ChatGPT 和大語言模型瘋狂的時候 , 遠在澳大利亞悉尼的一對兄弟卻在為一個看似簡單的問題發愁:為什么微調一個開源模型要花這么長時間 , 還要用那么昂貴的 GPU?
Daniel Han(全名是 Daniel Han-Chen)盯著屏幕上緩慢跳動的訓練進度條 , 心里盤算著:一臺免費的 Google Colab T4 GPU 上 , 訓練一個 13B 參數的模型根本跑不起來 , 內存直接爆掉 。 而那些商用的解決方案 , 動輒需要價值數萬美元的高端顯卡 。
Daniel 畢業于新南威爾士大學 , 此前曾在 NVIDIA 工作過一年半 , 專門負責算法優化 。 他認為這個問題并非無解 。 和弟弟 Michael Han-Chen 商量后 , 兩人決定:既然大公司不愿意解決這個問題 , 那就自己動手 。
【兄弟倆用開源對抗AI訓練壟斷,還順手幫模型們修了一堆Bug】
圖丨小時候的 Daniel Han 和 Michael Han(來源:GitHub)
這個決定催生了一個改變 AI 訓練規則的開源項目——Unsloth 。
從 NVIDIA 出走的優化狂人
Daniel Han 的職業生涯可以用一個詞概括:優化 。
在 NVIDIA 期間 , 他讓 TSNE(一種數據可視化算法)的運行速度提升了 2000 倍 , 優化了隨機奇異值分解(Randomized SVD)等多個機器學習算法 。 他還維護著另一個開源項目 Hyperlearn , 這個機器學習優化包被 NASA 和微軟的工程師使用 。
圖丨Daniel Han(右)和 Michael Han(左)(來源:LinkedIn)
那段經歷讓他看清了一個事實:當前 AI 軟件棧的性能瓶頸 , 很大程度上是軟件問題而非硬件問題 。 PyTorch、TensorFlow 這些框架為了通用性做了大量妥協——為了支持各種硬件和模型架構 , 實現必然不是最優的 。 如果針對特定場景深度定制 , 性能提升空間巨大 。
但真正讓他決心投身開源硬件優化的 , 是一個更宏大的愿景 。 “OpenAI 和 Anthropic 這些大公司想通過更大的模型、更多的數據、更強的算力來實現 AGI , ”Daniel 說 , “而我們相信 , 通過更高效的模型、更快的訓練方法、更少的資源消耗 , 也能讓 AGI 惠及每一個人 。 ”
2023 年 10 月 , 他們參加了歐洲的 LLM 效率挑戰賽(LLM Efficiency Challenge) 。 比賽規則是在 24 小時內用一塊 GPU 訓練一個語言模型 , 看誰能獲得最高準確率 。 但兄弟倆換了個思路——與其拼準確率 , 不如讓訓練本身變得更快 。
“我用的是 Colab 和 Kaggle 的免費 GPU , T4 實在太慢了 , 有時候連 13B 的模型都裝不下 , ”Daniel 回憶道 。 通過一系列底層優化 , 他們成功讓訓練速度提升了 2 倍 , 內存使用減少了 50% , 而且完全沒有精度損失 。 這個副產品式的成果 , 最終在 2023 年 12 月以開源項目的形式被發布 , 取名 Unsloth——意為“unslothing” , 讓 AI 訓練不再緩慢如樹懶 。
(來源:Unsloth)
沒有營銷預算 , 沒有豪華團隊 。 他們只是把代碼放在 GitHub 上 , 在 Reddit 的 AI 開發者社區發了一條帖子 。 第一周就有上千名開發者試用 。 最常見的質疑是:“速度快兩倍還不損失精度?怎么可能?”
Daniel 的回應非常簡單:把所有技術細節公開 。 他在博客上詳細解釋手動推導反向傳播的數學過程 , 展示 Triton 內核的源代碼 , 甚至把性能測試的完整日志都放出來 。 懷疑者開始認真閱讀代碼 , 復現測試 , 發現結果確實如此 。
為開源 LLMs 修 Bug
真正讓 Unsloth 聲名大噪的 , 是他們 2024 年 3 月對 Google Gemma 模型的“手術” 。
Gemma 發布后 , 社區很快發現問題:訓練時表現異常 , 損失值不收斂 , 微調效果差得出奇 。 論壇上出現各種猜測 , 但沒人能給出確定答案 。
Daniel 在集成 Gemma 到 Unsloth 時 , 發現的不是一個 bug , 而是一串 bug 。 分詞器有問題 , 位置編碼計算不對 , 連基礎的數值精度處理都有紕漏 。 他花三天時間 , 把 8 個 bug 的根源、觸發條件和修復方案全部整理成文檔 , 配有數學推導、性能對比和測試結果 。
然后全部公開發布 。
博客發布幾小時后 , 社區上就有許多轉載 。 Andrej Karpathy 轉發評論:“這就是深入理解深度學習棧每一層的價值 。 ”Google 團隊隨后確認了這些 bug , 采納修復方案 , 并在更新日志里致謝 。
圖丨相關推文(來源:X)
類似的事情在接下來一年反復上演 。 Meta 的 Llama 3、微軟的 Phi-4、阿里 Qwen 2.5 , 每次重磅模型發布 , Unsloth 都會迅速跟進 , 找出問題 , 公開方案 。 2024 年 10 月 , 他們甚至修復了一個影響所有訓練框架的通用 bug——梯度累積的實現錯誤 , 被合并到 Hugging Face Transformers 主分支 , 惠及了全球數百萬 AI 開發者 。
“當我們在移植新模型時 , 如果發現自己的實現比官方版本效果更好 , 我們就知道肯定哪里出問題了 , ”Daniel 解釋了他們的發現過程 。 這種對技術細節的執著和對開源社區的責任感 , 讓 Unsloth 贏得了業界的尊重 。 Hugging Face 很快與他們建立了合作關系 , 在官方文檔中推薦使用 Unsloth 來解決速度和內存問題 。 AWS、Intel 等大公司也主動接觸 , 希望將 Unsloth 移植到自己的硬件平臺上 。
重寫自動求導引擎
Unsloth 的核心創新在于對深度學習訓練流程的徹底重構 。 大多數工程師會滿足于使用 PyTorch 提供的自動求導功能 , 但 Daniel 認為這還不夠 。
“PyTorch 的 autograd 對大多數任務來說已經足夠高效 , 但如果你想要極致性能 , 就必須自己推導矩陣微分 , ”Daniel 選擇為所有計算密集型操作手工推導矩陣微分步驟 。
舉例來說 , 在注意力機制與低秩適應(LoRA Low-Rank Adaptation)結合時 , 標準方法需要計算 6 個矩陣的導數 。 如果按照常規方式 , 計算 output = X × W + X × (A × B) 需要三次矩陣乘法和兩個中間變量存儲 。 但 Daniel 通過代數變換優化為 output = X × (W + A × B)——先計算小矩陣 W + A × B , 最后只與大矩陣 X 相乘一次 。
這種看似簡單的代數技巧 , 單獨貢獻了約 4-6% 的速度提升 。 更關鍵的是 , 它顯著減少了 GPU 顯存占用 。 因為 LoRA 權重矩陣通常只有 8 到 128 的維度 , 而 Llama 系列模型的權重維度是 4096 或更大 , 正確放置括號能將浮點運算次數減少數個數量級 。
兄弟倆還用 OpenAI 的 Triton 語言重寫了所有關鍵計算內核 , 包括 RoPE(Rotary Position Embedding)位置編碼、RMS 層歸一化(Root Mean Square Layer Normalization)、交叉熵損失函數等 。 這些手寫的內核不僅更快 , 代碼也更清晰易讀 。
此外 , 還有他們獨創的“動態量化”技術 。 標準的 4-bit 量化會壓縮所有層 , 但 Unsloth 能識別出對模型精度影響大的敏感層 , 在這些層保持高精度 , 從而在大幅節省顯存的同時保持模型性能 。
但在所有優化中 , 內存減少才是 Unsloth 最大的優勢 。 Daniel 反復強調這一點:“我們百分之七十到八十的內存減少才是最重要的 。 不是速度 , 而是內存 。 ”隨著模型規模不斷增大 , 內存瓶頸比計算速度更容易成為制約因素 。 一個 16GB 顯存的 T4 GPU , 在標準訓練流程下連 130 億參數的模型都無法完整加載 , 但使用 Unsloth 后 , 48GB 顯存的 GPU 就能訓練 700 億參數的 Llama 3 模型 。
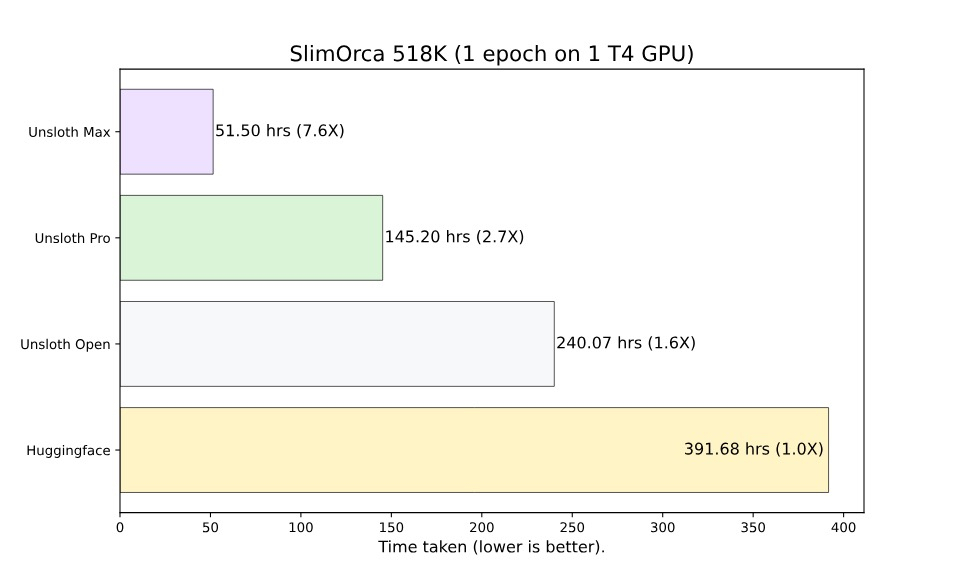
圖丨在 SlimOrca 數據集的測試結果(來源:Unsloth)
測試結果顯示 , 在單塊 Tesla T4 GPU 上 , 使用 Hugging Face 標準實現訓練 Alpaca 數據集需要 23 小時 15 分鐘 , 而 Unsloth 的 Max 版本只需要 2 小時 34 分鐘 , 相當于 8.8 倍的速度提升 。 在 SlimOrca 數據集上 , 391 小時被壓縮到 51 小時 。 內存使用方面 , 峰值從 16.7GB 降到 6.9GB , 減少了 59% 。
從邊緣走向中心
這一波 AI 浪潮中 , 模型的參數量不段擴大 , 從最初幾十億到如今的上萬億的參數量 , 規模膨脹了上百倍 , 給個人開發者和小團隊帶來了巨大壓力——要么付費使用閉源 API , 要么購買昂貴的硬件 。 而 Unsloth 讓第三條路成為可能 。 一臺消費級顯卡 , 比如 RTX 4090 , 配合 Unsloth 就能完成以前需要數據中心級別硬件才能做的微調任務 。
截至今天 , Unsloth 在 GitHub 上的星標已超過 4 萬(目前約 47500) , 每月模型下載量超過 200 萬次 。 來自中國、智利、尼加拉瓜、危地馬拉、印度、意大利、土耳其等國的開發者 , 已經基于 Unsloth 框架微調出超過 110 個模型應用 。
這種普及帶來了意想不到的效果 。 除了能讓各行各業都能更輕松地訓練出屬于自己的專有模型 , Daniel 還提到了一個最讓他驕傲的用例:“語言翻譯 。 大多數大語言模型只在特定語言集上預訓練 , 很多只支持英語 。 但我們看到很多來自母語非英語國家的開發者 , 用 Unsloth 把英語模型轉換成他們的本地語言 。 ”
從日語到印尼語 , 從韓語到各種印度地方語言 , Unsloth 讓模型本地化變得觸手可及 。 在他們的 GitHub 倉庫中 , 有一個專門的韓語翻譯示例筆記 , 詳細展示了如何將英語模型轉換為韓語模型 。 這個看似簡單的功能 , 卻讓全球數十億非英語使用者第一次真正擁有了自己語言的 AI 工具 。
開源的力量
回顧 Unsloth 的發展歷程 , 開源始終是核心 。 為了維持項目的可持續性 , 他們提供了 Pro 和 Max 兩個付費版本 , 前者支持多 GPU 訓練和更多優化 , 后者還包括從零開始訓練大模型的內核 , 并能將代碼移植到 AMD 和英特爾 GPU 上 。 但核心的開源版本始終保持免費 。 “開源最大的價值是信任 , ”Daniel 說 , “AI 領域最大的問題就是信任 。 如果你做開源 , 每個人都能檢查你的代碼 , 貢獻改進 , 發現并修復 bug 。 ”
兄弟倆的 Discord 社區異常活躍 , GitHub Issues 中充滿了用戶的改進建議和 bug 報告 。 “我們的 Discord 服務器上 , 每個人都很友好 , ”Michael 說 , “大家喜歡互相幫助 , 討論自己熱愛的東西 。 開源社區就是這樣一個讓志同道合的人聚在一起的地方 。 ”
這種開放協作的氛圍也影響了他們的產品規劃 。 “當所有人都在要求某個功能時 , 我們就會去實現它 , ”Daniel 表示 , “如果是閉源產品 , 很難決定先做哪個功能 。 開源讓用戶需求變得透明 。 ”
目前 , Unsloth 已經支持了 Llama 系列、Mistral、Gemma 系列、Phi 系列、Qwen 系列、DeepSeek 系列等主流開源模型 。 “我們的首要目標始終是開源 , ”Michael 強調 , “讓所有模型都能用上我們的優化技術 , 而不只是少數幾個 。 ”
“當大公司用 100000 塊 H100 訓練模型時 , 我們要證明 , 用更少的資源、更聰明的方法 , 也能讓 AI 惠及每一個人 。 ”Daniel 說 。
參考資料:
1.https://unsloth.ai/introducing
2.https://unsloth.ai/blog/reintroducing
3.https://www.youtube.com/watch?v=6t2zv4QXd6c
4.https://www.youtube.com/watch?v=lyVxD0bJDOk
5.https://www.youtube.com/watch?v=z9f4bEgFZCg
運營/排版:何晨龍
推薦閱讀












- 煉模不再“燒錢”?消耗40萬GPU·小時后,Meta開源強化學習重磅研究成果
- OpenInfra歐洲峰會:從VMware遷移至開源替代方案
- 重磅,DeepSeek再開源:視覺即壓縮,100個token干翻7000個
- 谷歌最強AI,被港科大開源超了?讓海外創作者喊出King Bomb的來了
- 智源開源EditScore:為圖像編輯解鎖在線強化學習的無限可能
- 估值翻6倍!這家爆火的開源初創正式晉升“獨角獸”
- 谷歌推出開源全棧NPU新架構,旨在實現大模型在終端的低功耗運行
- ICCV 2025 | 擴散模型生成手寫體文本行的首次實戰,效果驚艷還開源
- NeurIPS 2025 | CMU、清華、UTAustin開源ReinFlow
- 僅0.9B!百度新開源模型一夜登頂,識別109種語言,綜合分全球第一