
文章圖片
文章圖片
文章圖片
智東西
作者 | 陳駿達
編輯 | 云鵬
智東西11月20日報道 , 今天 , Meta宣布推出一個全新的模型家族SAM 3D , 并發布兩款3D模型 , 分別為用于物體和場景重建的SAM 3D Objects和用于人體和體型估計的SAM 3D Body 。
先來看看效果 , SAM 3D系列模型能在用戶點擊圖像中的元素后 , 直接從2D圖像中扣出一個3D模型 , 無論是物體還是人像 , 都能被準確重建 。 重建后的模型360度旋轉 , 也基本看不出破綻 。
SAM的全稱是Segment Anything Model , 直譯過來就是“分割一切”模型 。 Meta之前已經開源過SAM 1、SAM 2這兩款2D圖像分割模型 , 是該領域標桿作品 。
SAM 3D系列模型發布的同日 , 此前在ICLR大會審稿期間就引發熱議的SAM 3也迎來正式發布 。 SAM 3圖像分割模型的亮點是引入了“可提示概念分割”的新功能 。
在過去 , 大部分圖像分割模型只能根據有限的預設標簽對圖像進行分割 , 而SAM 3讓用戶可以輸入“狗”、“大象”、“斑馬”這樣具體的標簽 , 或“動物”這樣的整體概念 , 甚至是“穿著黑色外套、戴著白色帽子的人”這樣的描述 , 并完成圖像分割 , 這大幅提升了圖像分割模型的通用性 。
SAM 3還具有超快的推理速度 , 在單張英偉達H200 GPU上 , SAM 3能在30毫秒左右識別一張包含超過100個可檢測物體的圖片 。
SAM 3的發布 , 讓英偉達開發者技術總結Nader Khalil直呼:“這可能就是計算機視覺的ChatGPT時刻 , 強大的分割功能意味著用戶只要點擊一下就能訓練計算機視覺模型 , 太瘋狂了 。 ”
Meta已經直接拿SAM 3D Objects和Sam 3開始賣貨了 。 Facebook Market現在提供新的“房間視圖”功能 , 讓用戶可在購買家具前直觀地感受家居裝飾品在空間中的風格和合適度 。
目前 , SAM 3D系列模型和SAM 3都已經能在Meta最新打造的Segment Anything Playground中進行體驗 。 SAM 3D的訓練和評估數據、評估基準、模型檢查點、推理代碼以及參數化人類模型都已經開源 , SAM 3開源了模型檢查點、評估數據集和微調代碼 。
SAM 3D博客(內含論文、開源鏈接):
https://ai.meta.com/blog/sam-3d/
SAM 3博客(內含論文、開源鏈接):
https://ai.meta.com/blog/segment-anything-model-3/
一、標注近百萬張圖像 , 幾秒鐘完成全紋理3D重建過去 , 三維建模一直面臨著數據匱乏的問題 。 與文本、圖像等豐富的資料相比 , 真實世界的3D數據少得可憐 , 大多數模型只能處理孤立的合成資產 , 或者在簡單背景下重建單個高分辨率物體 。 這讓3D重建在現實場景中顯得力不從心 。
SAM 3D Objects的出現 , 則打破了這一局限 。 通過強大的數據注釋引擎 , 它在大規模自然圖像上實現了3D物體的精細標注:近百萬張圖像 , 生成超過314萬個網格模型 。
這一過程結合了“眾包+專家”模式 。 普通數據標注者對模型生成的多個選項進行評分 , 最難的部分交給資深3D藝術家處理 。
SAM 3D Objects還借鑒了大型語言模型的訓練理念 , 將合成數據學習重新定義為“三維預訓練” , 再通過后續階段的微調 , 讓模型在真實圖像上發揮出色 。
這種方法不僅提升了模型的魯棒性和輸出質量 , 也反過來讓數據生成更高效 , 實現了數據引擎與模型訓練的正向循環 。
為了驗證成果 , 團隊還與藝術家合作建立了SAM 3D藝術家對象數據集(SA-3DAO) , 這是首個專門用于評估物理世界圖像中單幅3D重建能力的數據集 。 相比現有基準 , 這個數據集的圖像和物體更具挑戰性 。
性能方面 , SAM 3D Objects在一對一的人類偏好測試中 , 以5:1的優勢戰勝現有領先模型 。 同時 , 結合擴散捷徑和優化算法 , 它能在幾秒鐘內完成全紋理3D重建 , 讓幾乎實時的三維應用成為可能 , 比如為機器人提供即時視覺感知 。
它不僅可以重建物體的形狀、紋理和姿態 , 還能讓用戶自由操控攝像機 , 從不同角度觀察場景 。 這意味著即使面對小物體、遮擋或間接視角 , SAM 3D Objects也能從日常照片中提取出三維細節 。
當然 , 這一模型仍有提升空間 。 當前模型的輸出分辨率有限 , 復雜物體的細節還可能出現缺失;同時 , 物體布局預測仍以單個物體為主 , 對多物體的物理交互推理尚未實現 。
未來 , 通過提高分辨率和加入多物體聯合推理 , SAM 3D Objects有望在真實世界場景中實現更精細、更自然的三維重建 。
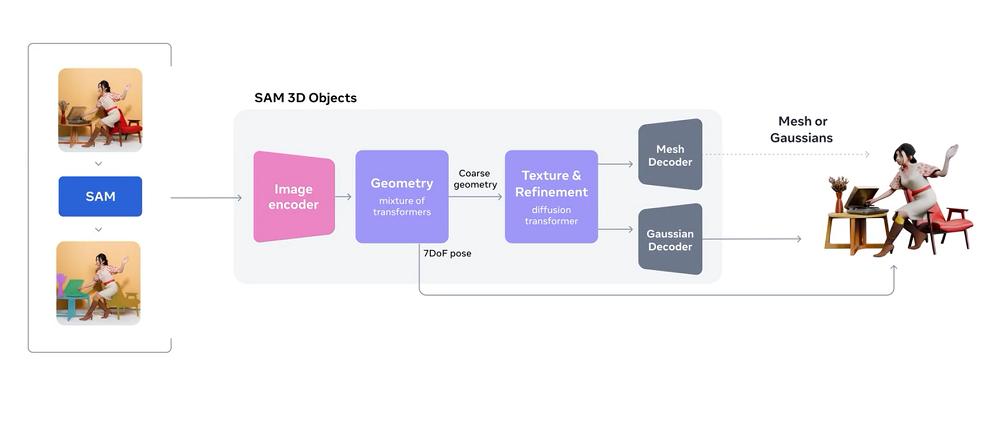
二、三維重建更具交互性和可控性 , 配備新型開源3D格式SAM 3D Objects主要面向物體的三維重建 , 而SAM 3D Body則專注于人體的三維重建 。 SAM 3D Body能夠從單張圖像中精確估算人體的三維姿態和形狀 , 即便面對異常姿勢、局部遮擋 , 甚至多人復雜場景 , 也能穩定地輸出 。
值得注意的是 , SAM 3D Body支持提示輸入 , 用戶可以通過分割掩碼、二維關鍵點等方式引導和控制模型的預測 , 讓三維重建更具交互性和可控性 。
SAM 3D Body的核心是一種名為Meta Momentum Human Rig(MHR)的開源3D網格格式 , 它將人體的骨骼結構與軟組織形狀分離 , 從而提高了模型輸出的可解釋性 。
模型采用Transformer Encoder-Decoder架構 , 圖像編碼器能夠捕捉身體各部位的高分辨率細節 , 而網格解碼器則支持基于提示的三維網格預測 。 這種設計讓用戶不僅能獲得精確的三維人體模型 , 還能在交互中靈活調整和微調結果 。
在數據方面 , SAM 3D Body研究團隊整合了數十億張圖像、多機位高質量視頻以及專業合成數據 , 通過自動化數據引擎篩選出罕見姿勢、遮擋或復雜服裝等高價值圖像 , 形成約800萬張高質量訓練樣本 。
這樣的數據策略讓模型在面對多樣化場景時仍然保持強大的魯棒性 , 同時結合基于提示的多步細化訓練 , 使三維預測與二維視覺證據對齊得更加精確 。
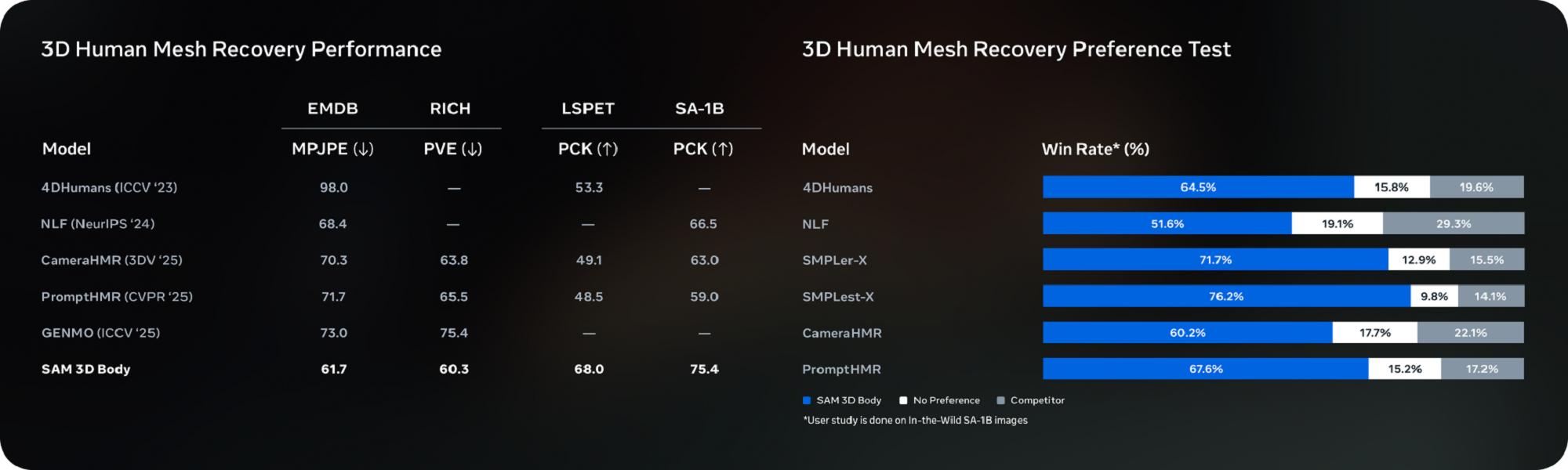
發布的基準結果顯示 , SAM 3D Body在多個三維人體基準測試中取得了顯著優勢 , 準確性和穩健性均領先于以往模型 。
此外 , 團隊還開放了MHR模型 , 這一參數化人體模型在商業許可下可供使用 , 使Meta的技術如Codec Avatars等得以落地應用 。
SAM 3D Body主要針對單人處理 , 尚未支持多人或人與物體的交互預測 , 這限制了對相對位置和物理互動的準確推理 。 此外 , 其手部姿勢的估計在精確度上仍落后于專門的手部姿勢估計方法 。
未來 , SAM 3D Body計劃將人與物體、環境互動納入訓練 , 同時提升手部姿勢重建精度 , 使模型在真實場景中更全面、更自然 。
三、分割靈活性增強 , AI深度參與數據構建如果說SAM 3D系列模型代表著Meta在三維視覺重建領域的首次突破 , 那么SAM 3對Meta在2D圖像分割領域探索的延續 。
SAM 3是一款統一模型 , 能夠基于文本、示例圖像或視覺提示實現對象的檢測、分割和跟蹤 , 其開放性和交互性提升了視覺創作和科學研究的可能性 。
通過“可提示概念分割” , SAM 3能夠識別更復雜、細微的概念 , 例如“條紋紅傘”或“手中未持禮盒的坐著的人” 。
為衡量大詞匯量分割性能 , Meta同時推出了Segment Anything with Concepts(SA-Co)數據集 , 這一基準覆蓋了遠超以往的數據概念 , 并對圖像和視頻中的開放式概念分割進行了挑戰測試 。
SAM 3模型支持多種提示形式 , 包括文本短語、示例圖像以及視覺提示(如掩碼、框選點) , 增強了分割靈活性 。
Meta公布的測試結果顯示 , SAM 3在SA-Co基準上的概念分割性能實現了約100%的提升 , 在用戶偏好測試中 , 相較最強競品模型OWLv2 , SAM 3的輸出更受青睞 , 比例達到約3:1(SAM 3:OWLv2) 。
此外 , SAM 3在傳統SAM 2的視覺分割任務中也保持領先表現 , 零樣本LVIS和目標計數等挑戰性任務同樣取得顯著進展 。
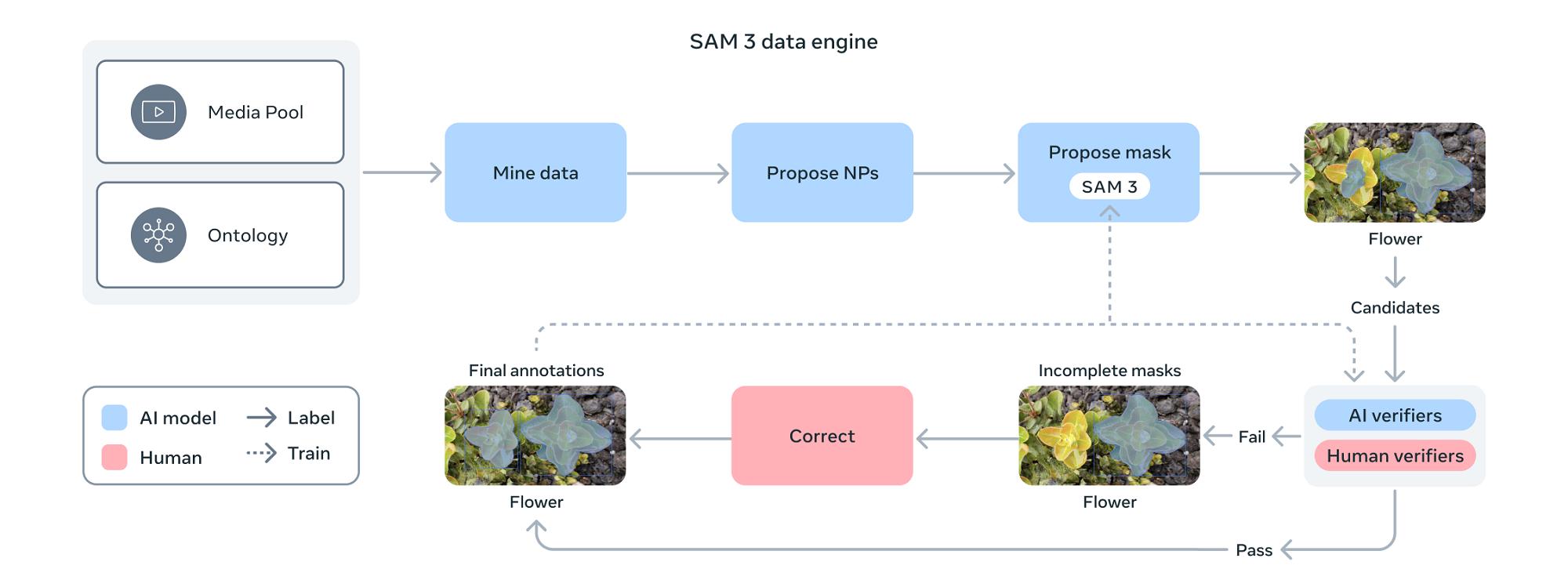
在數據構建方面 , SAM 3采用人類與AI協同的數據引擎 。 這一流程包括使用SAM 3及Llama 3.2v模型自動生成初始分割掩碼和標簽 , 再由人類與AI注釋者驗證和修正 。
AI注釋者不僅能提升標注速度(負樣本快約400% , 正樣本快約36%) , 還會自動篩選簡單樣本 , 把人力集中于最具挑戰的案例 。
同時 , Meta利用概念本體(基于維基百科的概念字典)擴展數據覆蓋范圍 , 使稀有概念也能獲得標注支持 。
消融實驗顯示 , AI與人類注釋結合的策略能顯著提升模型性能 , 同時為新視覺域的自動數據生成提供可行途徑 。
在模型架構上 , SAM 3結合了多項先進技術:文本與圖像編碼器基于Meta Perception Encoder , 檢測器采用DETR架構 , 跟蹤組件延續了SAM 2的記憶模塊 。
通過統一架構處理檢測、分割和跟蹤任務 , SAM 3在處理復雜視覺任務時避免了任務間沖突 , 同時保持了高性能和高效訓練 。
SAM 3在某些極端場景下仍有提升空間 , 例如零樣本下識別專業術語(如“血小板”)或處理長復雜文本描述 。 在視頻場景中 , SAM 3將每個對象單獨處理 , 使得多對象場景下效率和性能仍可優化 。
Meta提供了模型微調方法和工具 , 鼓勵開源社區針對特定任務和視覺域進行適配和擴展 。
結語:生成式AI , 正改變CV的玩法生成式AI的崛起 , 正在反哺上一輪以計算機視覺為核心的AI浪潮 。 從數據集的打造到模型訓練方式創新 , 生成式AI擴展了CV模型的能力邊界 , 也帶來更多的創新玩法 。
【AI視覺GPT時刻!Meta新模型一鍵“分割世界”,網友直呼太瘋狂了】此外 , 我們也看到Meta已經在積極地將相關技術用于真實業務 , 隨著數據和用戶反饋的積累 , SAM和SAM 3D系列模型或將給我們帶來更多的驚喜 。
推薦閱讀













- GPT-5.1 Codex 比Claude便宜 55%,代碼漏洞更少!
- OpenAI 發布最強編程模型 GPT-5.1
- 抱歉了GPT-5,這次是中國AI「上岸」了
- 「30 秒造應用」——螞蟻靈光點燃「所想即所得」的魔法時刻
- 接招吧,GPT-5.1!
- ChatGPT:再見「破折號」
- 曝阿里巴巴正開發千問App,全面對標ChatGPT
- GPT-5敗下陣,這款中國AI拿下全球第一,眾多醫生已在用它做診斷
- DeepL CEO:專業翻譯服務如何在ChatGPT時代保持競爭優勢
- OpenAI發布GPT-5.1系列:ChatGPT更會聊天,可為用戶量身定制