
文章圖片
文章圖片

文章圖片
允中 整理自 凹非寺
量子位 | 公眾號 QbitAI
長文本圖像檢索新SOTA來了!
描述得越詳細 , 圖文匹配的分數就應該越高——這聽起來是常識 , 但現有的CLIP模型卻做不到 。
而就在最近 , 中國聯通數據科學與人工智能研究院團隊在AAAI 2026 (Oral)上發表了一項最新成果 , 成功突破了這一局限 。
研究名為HiMo-CLIP , 通過巧妙地建模“語義層級”與“語義單調性” , 在不改變編碼器結構的前提下 , 讓模型自動捕捉當前語境下的“語義差異點” 。
由此 , 成功解決了視覺-語言對齊中長期被忽視的結構化問題 , 在長文本、組合性文本檢索上取得SOTA , 同時兼顧短文本性能 。
這一工作不僅提升了檢索精度 , 更讓多模態模型的對齊機制更加符合人類的認知邏輯 , 為未來更復雜的多模態理解任務指明了方向 。
痛點:當描述變長 , CLIP卻“懵”了 【讓大模型學會高維找茬,中國聯通新研究解決長文本圖像檢索痛點】在多模態檢索任務中 , 我們通常期望:文字描述越詳細、越完整 , 其與對應圖像的匹配度(對齊分數)應該越高 。 這被稱為“語義單調性” 。
然而 , 現實很骨感 。 現有的模型(包括專門針對長文本優化的Long-CLIP等)往往將文本視為扁平的序列 , 忽略了語言內在的層級結構 。
如下圖所示 , 對于同一張“白色福特F250皮卡”的圖片 , 當文本從簡短的“正面視圖…”擴展到包含“超大輪胎”、“車軸可見”、“有色車窗”等詳細描述的長文本時 , 許多SOTA模型的對齊分數反而下降了 。
這種現象表明 , 模型未能有效處理長文本中的“語義層級” , 導致細節信息淹沒了核心語義 , 或者無法在復雜的上下文中捕捉到最具區分度的特征 。
△圖1 隨著描述變長 , 現有模型分數下降 , 而HiMo-CLIP(綠勾)穩步提升
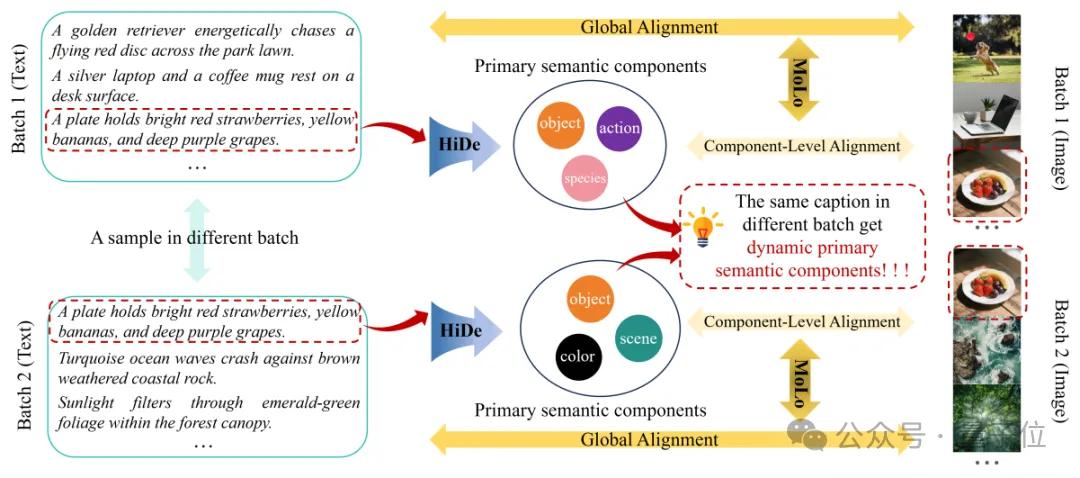
方法:HiMo-CLIP框架為了解決上述問題 , 研究團隊提出了一種即插即用的表征級框架HiMo-CLIP 。
它包含兩個核心組件:層級分解模塊(Hierarchical Decomposition , HiDe)和單調性感知對比損失(Monotonicity-aware Contrastive Loss , MoLo) 。
△圖2. HiMo-CLIP框架概覽
(1)HiDe模塊利用Batch內的PCA動態提取語義成分;(2)MoLo損失函數強制模型同時對齊“全量文本”和“語義成分” , 實現單調性約束 。
HiDe:誰是重點?由“鄰居”決定在真實場景中 , 數據樣本往往是高度復雜的 。
如上圖2所示 , 我們面對的不是簡單的“紅蘋果”和“青蘋果” , 而是像“一只金毛獵犬在公園草坪上追趕紅盤”、“盤子里放著鮮紅的草莓、黃香蕉和深紫色的葡萄”這樣高度復雜的場景 。 傳統的固定分詞法在這種復雜度下根本抓不住重點 。
HiMo-CLIP換了個思路 , 它像一個玩“大家來找茬”的高手:通過觀察Batch內的“鄰居” , 動態提取最具區分度的特征 。
長文本特征f1:代表“整句話”的意思 。 動態子語義f2:代表“這句話里最獨特的記憶點” 。 舉個栗子:假設長文本是:“一只戴著墨鏡的柯基在沙灘上奔跑” 。 場景A(混在風景照里):如果這一批次(Batch)的其他圖片都是“沙灘排球”、“海邊游艇” 。 PCA一分析 , 發現“沙灘”大家都有 , 不稀奇 。 唯獨“柯基”是獨一份 。 →此時 , f2自動代表“柯基(物體)” 。 場景B(混在狗群里):如果這一批次的其他圖片都是“草地上的柯基”、“沙發上的柯基” 。 PCA一分析 , 發現“柯基”遍地都是 , 也沒法區分 。 唯獨“戴墨鏡”和“在沙灘”是特例 。 →此時 , f2自動代表“戴墨鏡/沙灘(屬性/環境)” 。這就是HiDe最聰明的地方:它不需要人教它什么是重點 , 而是利用統計學原理 , 自適應地提取出那個最具辨識度的“特征指紋” , 自動構建語義層級 。
MoLo:既要顧全大局 , 又要抓住細節找到了重點f2 , 怎么用呢?作者設計了MoLo , 強制模型“兩手抓”:
MoLo=InfoNCE(f1 feat)+λ*InfoNCE(f2 feat)
第一手:InfoNCE(f1 feat)是傳統的圖文匹配 , 保證圖片和“整句話”(f1)對齊 。 第二手:InfoNCE(f2 feat)強制圖片特征還要特別像那個提取出來的“獨特記憶點”(f2) 。這個操作看似簡單 , 實則一石三鳥:
自動摘要:f2就是特征空間里的“高維短文本” , 省去了人工構造短文本的偏差 。 更懂機器的邏輯:人類定義的關鍵詞(如名詞)未必是模型分類的最佳依據(可能是紋理或形狀) 。 PCA完全在特征空間操作 , 提取的是機器認為的差異點 , 消除了人類語言和機器理解之間的隔閡(Gap) 。 數據效率高:你只需要喂給模型長文本 , 它在訓練中順便學會了如何拆解長句、提取關鍵詞 。 訓練的是長文本 , 卻白撿了短文本的匹配能力 。 實驗:長短通吃 , 全面SOTA研究團隊在多個經典的長文本、短文本檢索基準 , 以及自行構造的深度層級數據集HiMo-Docci上進行了廣泛實驗 。
在長文本(表1)和短文本(表2)檢索任務上 , HiMo-CLIP展現出了顯著的優勢 。 值得注意的是 , HiMo-CLIP僅使用了1M(一百萬)的訓練數據 , 就擊敗了使用100M甚至10B數據的方法(如LoTLIP , SigLIP等) 。
△表1 長文本檢索結果
△表2 短文本檢索結果
為了充分評估長文本的對齊效果 , 研究團隊構建了HiMo-Docci數據集 , 同時還提出了HiMo@K指標 , 以量化模型是否真的“讀懂”了層級 。 結果顯示 , HiMo-CLIP保持了極高的單調性相關系數(0.88) , 遠超對比方法 。
△HiMo-Docci上的單調性可視化
隨著文本描述逐漸完整(1→5) , HiMo-CLIP的分數(紅線)呈現出完美的上升趨勢 , 而其他模型的分數則波動劇烈 , 甚至下降 。
進一步的 , 為了探究各個組件對性能的具體貢獻 , 研究團隊進行了詳盡的消融實驗 , 揭示了HiDe與MoLo協同工作的內在機理 。
感興趣的朋友可到原文了解更多細節~
論文鏈接:https://arxiv.org/abs/2511.06653開源地址:https://github.com/UnicomAI/HiMo-CLIP
— 完 —
量子位 QbitAI · 頭條號簽約
關注我們 , 第一時間獲知前沿科技動態
推薦閱讀










- 企查查MCP上線 提供精準商業數據 讓AI智能體決策更精準
- 讓更多人買得起!加量又降價的Mate80系列,誠意滿滿
- AI系統在壓力下學會戰略性欺騙的深層原因
- 大模型作為評估者的「偏好」困境:UDA實現無監督去偏對齊
- 電子科技大學提出基于雙路徑注意力干預多模態大模型物體幻覺緩解
- 80后諾獎得主:AlphaFold下一步融合大模型
- 七年制裁讓華為變得更強大?重要數據出爐,外媒:美制裁了什么?
- WPS 365 更新了,它想讓職場人少按一些「Alt+Tab」
- Adam的穩+Muon的快?華為諾亞開源ROOT破解大模型訓練的兩難困境
- ETH蘇黎世大學開發VIST3A:讓AI像拼積木一樣創造逼真3D世界