
文章圖片
文章圖片
在 Vision-Language Model 領域 , 提升其復雜推理能力通常依賴于耗費巨大的人工標注數據或啟發式獎勵 。 這不僅成本高昂 , 且難以規模化 。
最新研究 VisPlay 首次提出了一個自進化強化學習框架 , 使 VLM 能夠僅通過海量的未標注圖像數據進行自我演化和能力提升 。
VisPlay 將基礎 VLM 分解為「提問者」和「推理者」兩大角色 , 通過迭代的自我進化機制協同進化 , 并結合 GRPO 算法和創新的多樣性/難度獎勵 , 平衡了問題的復雜度和答案的質量 。
Title:VisPlay: Self-Evolving Vision-Language Models from Images Paper:https://arxiv.org/abs/2511.15661 Github:https://github.com/bruno686/VisPlay實驗證明 , VisPlay 在 Qwen2.5-VL 和 MiMo-VL 等主流模型上實現了持續的性能提升 , 尤其在視覺推理、組合泛化和幻覺減少方面效果顯著 , 展示了一條可擴展、低成本的多模態智能進化新路徑 。
引言:
VLM 推理能力的「數據困境」
近年來 , Vision-Language Model(VLM)在感知任務上取得了不小的進展 , 但在更復雜的視覺推理上仍然吃力 。 主流的提升方式如指令微調(SFT)或強化學習(RL)都繞不開一個核心難題:依賴高質量標注數據 。 尤其是強化學習 , 需要精準且可驗證的獎勵信號 , 而這些往往要靠耗時費力的人工標注或針對具體任務設計復雜的規則 。
隨著模型規模越來越大 , 人工標注的成本和速度已經逐漸跟不上模型演化的需求 , 這也成為進一步提升能力的主要瓶頸 。 在這樣的背景下 , 研究者開始嘗試「自進化」(Self-Evolving)的思路 , 讓模型能通過自我生成、自我修正以及從自身經驗中持續學習 , 從而實現自主的能力迭代 。
VisPlay:
【無需標注圖像,RL自我進化框架VisPlay突破視覺推理難題】基于自我進化的自進化框架
為解決上述挑戰 , 由來自伊利諾伊大學厄巴納-香檳分校、華盛頓大學圣路易斯分校、馬里蘭大學、新加坡國立大學的研究團隊提出的 VisPlay 框架 , 首次將自進化強化學習應用于 VLM , 并實現僅依賴未標注圖片進行自主學習 。
VisPlay 的核心理念是自我進化(Self-Evolving):它從一個基礎預訓練 VLM 出發 , 將其在訓練過程中分解成兩個相互作用的角色 。
Image-Conditioned Questioner(提問者)
負責根據輸入的圖片生成具有挑戰性、但又可被回答的視覺問題 。 具體來說 , VisPlay 設計了一種精妙的獎勵機制來指導自我進化的質量 , 分別是難度獎勵(Difficulty Reward)和多樣性獎勵(Diversity Reward) 。
前者鼓勵提問者生成更復雜的、需要深層次推理才能解決的問題;后者確保生成的問題類型和涉及的知識點足夠廣泛 , 防止模型陷入狹窄的知識或推理路徑 , 從而實現更強大的組合泛化能力 。
通過這種獎勵機制 , VisPlay 有效解決了自進化模型中常見的「答案質量低」和「問題重復度高」的問題 , 真正實現了從量變到質變的能力飛躍 。
Multimodal Reasoner(推理者)
負責基于圖片和提問者的問題 , 生成「白銀級響應」(Silver Responses , 即偽標注答案) 。 這里我們采用回答的準確性作為訓練信號 。
實驗結果:
全方位的能力突破
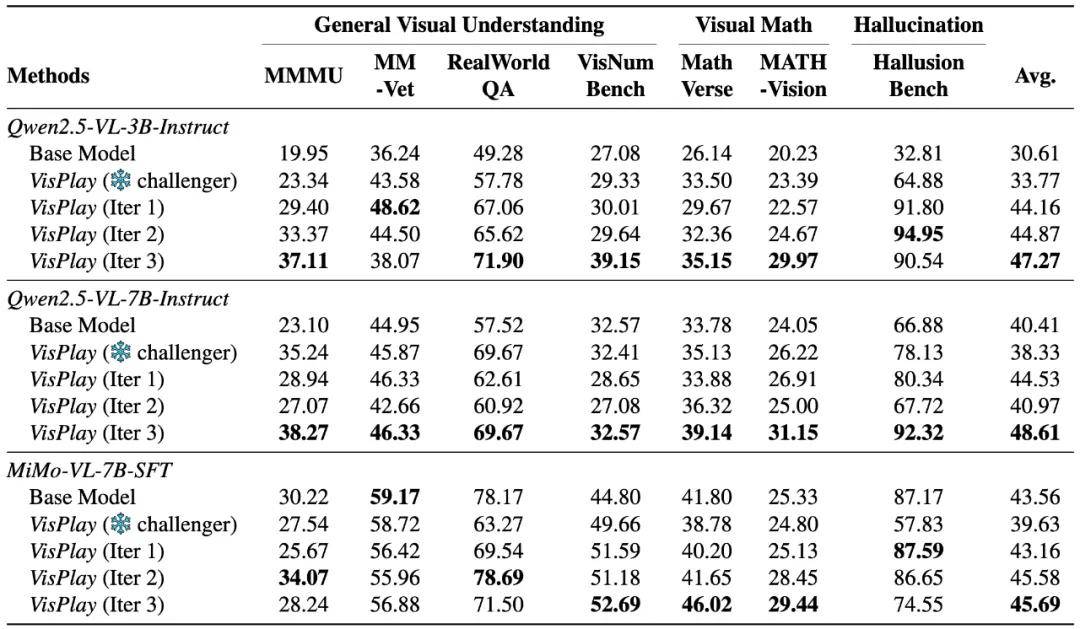
研究團隊將 VisPlay 應用于包括 Qwen2.5-VL 和 MiMo-VL 在內的多個主流 VLM 模型家族 , 并在八個主流基準數據集上進行了廣泛評估 , 涵蓋:通用視覺理解(如 MM-Vet)、跨模態推理(如 MMMU)、視覺數學推理(如 MathVerse)以及幻覺檢測(HallusionBench) 。
關鍵發現:
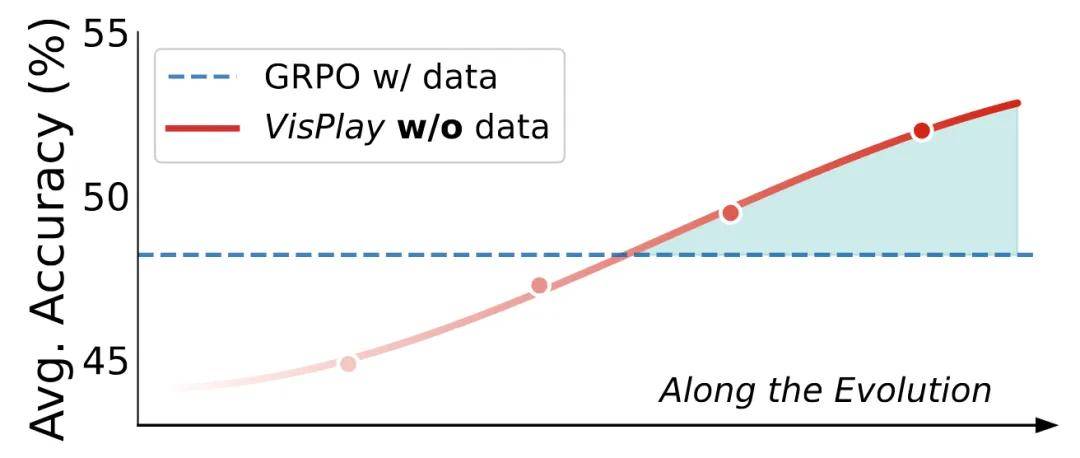
持續穩定的性能提升: 在所有測試模型和基準上 , VisPlay 都實現了一致且顯著的準確率增益 , 證明了該框架的泛化性和有效性 。
強大的組合泛化能力: 模型在訓練中未見過的復雜推理組合上表現出更強的魯棒性 。
有效抑制「幻覺」: VisPlay 通過自我進化生成的高質量問答對 , 有效幫助模型識別和修正錯誤的視覺-語言關聯 , 顯著減少了模型產生「幻覺」現象的概率 , 這是一個困擾 VLM 的重大問題 。
VisPlay 的成功證明了僅依賴海量非結構化圖片來持續提升 VLM 推理能力的可行性 , 為未來開發更智能、更自主的多模態系統指明了方向 。
推薦閱讀













- 讓大模型學會高維找茬,中國聯通新研究解決長文本圖像檢索痛點
- Gemini的AI圖像檢測工具僅觸及表面,這還遠遠不夠
- Android與iOS打通快速分享功能,無需下載App,直接就能傳
- Google在Gemini中推出AI圖像檢測工具:能識別AI生成內容嗎?
- UniLumos: 物理反饋統一圖像視頻重打光框架,20倍加速光影重塑
- SGLang Diffusion震撼發布:圖像視頻生成速度猛提57%!
- 三星擬追加19億美元升級奧斯汀工廠,為蘋果iPhone 18生產圖像傳感器
- Lumina-DiMOO:多模態擴散語言模型重塑圖像生成與理解
- 蘋果1299元新品引熱議 官方小字標注“數量有限,售完為止”
- PDF協會選擇JPEG XL作為首選圖像格式