
文章圖片
文章圖片
文章圖片
近日 , 24 歲的 00 后博士生胡文博和所在團隊造出一款名為 G2VLM 的超級 AI 模型 , 它是一位擁有空間超能力的視覺語言小能手 , 不僅能從普通的平面圖片中精準地重建出三維世界 , 還能像人類一樣進行復雜的空間思考和空間推理 。
它除了可以判斷一張照片里有一把椅子之外 , 還能知道這把椅子距離桌子有多遠 , 更能知道有多高、是正著放還是歪著放 。 這意味著 , 未來的機器人可能會更靈活地幫你拿取物品 , AR/VR 游戲的世界會更加真實 , 甚至自動駕駛汽車能夠更精準地判斷距離和障礙物 。
圖 | 胡文博(來源:胡文博)
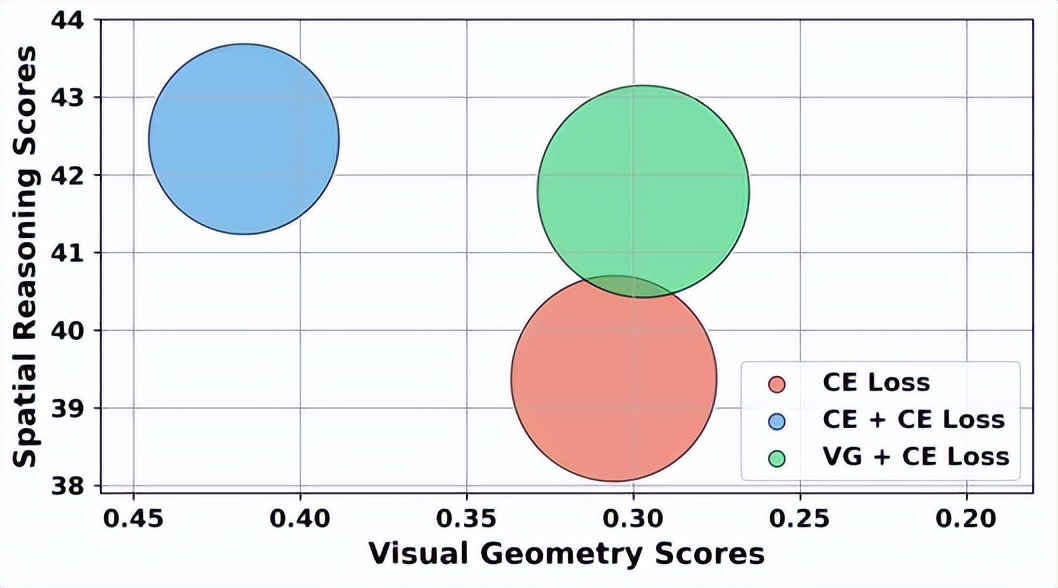
在 SPAR-Bench 測試中 , G2VLM 的總分比頂尖商業模型 GPT-4o 超出了 18.5 分 , 位居榜首 。 在 OmniSpatial、MindCube 等多個空間推理測試基準中 , 它也取得了最優或極具競爭力的成績 。
最有趣的是 , 盡管 G2VLM 的模型尺寸只有 4B 參數 , 遠遠小于一些動輒數百億甚至上千億參數的大型模型 , 但是它在空間任務上的表現卻輕松超過了這些大塊頭 , 這證明它的雙專家架構設計得非常高效 , 不是靠蠻力 , 而是靠巧勁 。
胡文博告訴 DeepTech:“機器人要執行如泡咖啡這類復雜操作 , 必須實時、精準地理解物體的位置、距離和相互關系 。 G2VLM 作為一個強大的基礎模型 , 可以為下游的具身智能模型提供預訓練支持 , 極大地增強其空間感知與操作能力 。 ”
(來源:https://arxiv.org/pdf/2511.21688)
從平面眼到立體眼:AI 的空間視力進化史
G2VLM 和我們手機里的圖像識別軟件有著本質不同 , 要想理解它的獨特之處得先從現有的視覺-語言模型講起 。 這類模型所存在的共同缺點在于 , 它們僅僅擁有平面眼 。
假如你給這些 AI 看一張桌子的照片 , 經過海量圖片訓練的它們 , 可以很輕松地識別出這是一張桌子 , 甚至能夠描述桌子的顏色和樣式 。
但是 , 如果你問它:桌子左邊的杯子距離桌子右邊的書籍大概有多遠?或者你問它:能否繪制一張關于這個房間的三維結構圖 。 這時 , 它可能就傻眼了 。 因為它處理圖片的方式 , 就像把一幅有深度的油畫壓成一幅扁平的剪貼畫 , 丟失了至關重要的深度和空間關系信息 。
這就像只通過影子來猜測物體的形狀 , 準確度非常低 。 也就是說這些 AI 模型主要依靠圖片的紋理、顏色和已有的知識比如桌子通常比杯子大來猜測空間關系 , 而不是真正地理解三維幾何關系 。 因此 , 它們需要在精確空間感知的任務上 , 比如機器人導航、三維場景編輯或者回答復雜的空間關系問題時 , 表現得差強人意 。
(來源:https://arxiv.org/pdf/2511.21688)
靈感來源于人腦 , 打造雙專家協作系統
胡文博等人在設計 G2VLM 的時候 , 從人腦處理視覺信息的方式中獲得了靈感 。 人腦主要有兩條視覺處理通路:第一條是“是什么”的通路 , 該通路負責識別物體是什么 。
比如 , 看到紅色、圓形、有柄的東西 , 就能認出來這是蘋果、第二條是“在哪里”的通路 , 該通路負責判斷物體的位置、距離和空間關系 。 比如 , 判斷蘋果在盤子上方 , 距離人手大約有 20 厘米 。
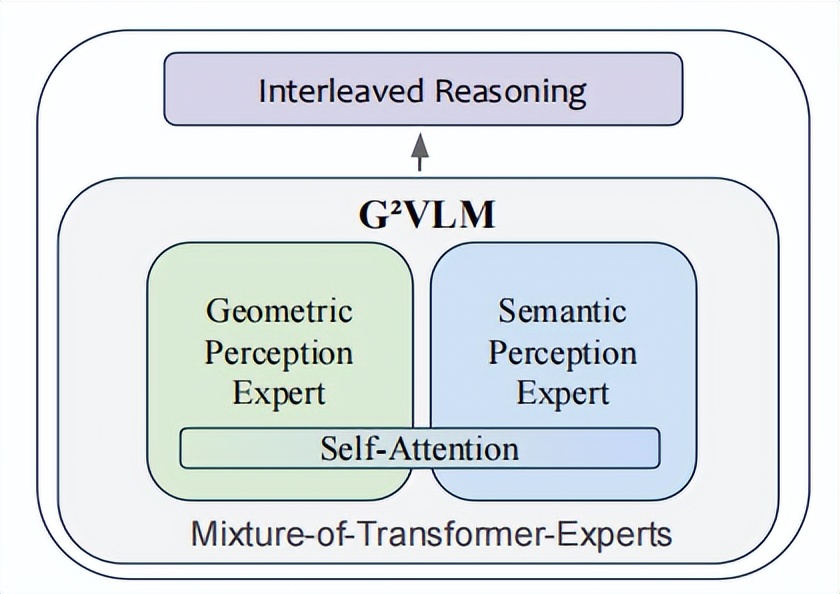
G2VLM 將這個原理用在了 AI 模型上 , 它不是一個單一的“大腦” , 而是由兩位專家緊密合作構成的:
第一位是幾何感知專家 , 這位專家的專長是從 2D 圖片中解讀 3D 幾何信息 , 它的目標是弄清楚物體的深度、各個點的三維坐標 , 以及拍攝照片的相機角度 。
第二位專家是語義感知專家 , 這位專家繼承了現有 AI 模型的優點 , 擅長理解圖片內容并用語言進行描述 。 它能認出物體和理解場景 , 并能回答一般性問題 。
最關鍵的是 , 這兩位專家并不是各自為戰 , 而是通過一個共享的注意力機制來進行緊密相連 , 以便能夠隨時交流信息 。 當語義專家說“這里有個沙發”時 , 幾何專家就會立馬補充說:“這個沙發距離墻壁大約有 1.5 米 , 高度是 0.8 米 。 ”這種實時的、深度的協作 , 讓 G2VLM 同時具備了看懂內容和理解空間的超能力 。
(來源:https://arxiv.org/pdf/2511.21688)
獨特的學藝過程:兩步訓練法
培養這樣一位雙料專家并非易事 , 胡文博為 G2VLM 設計了一套獨特的學藝方案:
在第一階段 , 讓其閉關修煉幾何神功 。 首先 , 得固定住語義專家也就是讓它暫時休息 , 此時只針對幾何專家進行訓練 。 胡文博等人使用帶有精確三維標注的數據來訓練它 。
這就好比讓一名未來的建筑測量師 , 在擁有完整藍圖的成千上萬個建筑模型上反復練習 , 直到練就一雙火眼金睛 , 光看照片就能在腦中精確構建三維模型 。 這個過程非常耗費計算資源 , 需要在數十臺頂級顯卡上連續訓練好幾天 。
在第二階段 , 讓其進行融會貫通 。 當幾何專家初步練就基本功之后 , 就輪到它和另一位專家一起訓練了 。
這時 , 訓練數據變成了各種需要空間推理的問題 , 比如需要解決“根據這兩張從不同角度拍攝的照片來判斷球是滾向了左邊還是右邊?”在這個階段 , 語義專家被喚醒之后 , 能夠學習如何主動利用幾何專家提供的深度和距離等信息來回答問題 。
而幾何專家也有可能進行自我微調 , 來讓自己提供的空間信息更加適用于高級推理 。 通過這種聯合 , 兩位專家磨合得越來越好 , 最終合體成為強大的 G2VLM 。
(來源:https://arxiv.org/pdf/2511.21688)
在多個國際 AI“比武擂臺”上證明自己
練成之后的 G2VLM 到底有多強?
在三維重建的測試中:就深度估計來說 , 給定一張單視角照片 , 它能估計出照片中每個像素點距離相機的實際深度 , 誤差很?。 瘓偷閽乒蘭評此?, 給定幾張多視角照片 , 它能生成密集且準確的三維點云模型 , 清晰地勾勒出物體的形狀;就相機姿態估計來說 , 它能反推出拍攝每張照片時 , 相機在空間中的精確位置和角度 。
在這些純粹考驗三維幾何理解能力的任務上 , G2VLM 的表現與當前世界上最頂尖的專用三維重建模型不相上下 , 甚至在某些指標上更加出色 , 這意味著它的立體眼已經達到了專業水準 。
在空間推理的測試中 , 它展現出了最閃耀的部分 。 胡文博等人在包含了深度比較、距離判斷、物體相對關系、空間想象等各類難題的綜合評測集上測試了 G2VLM , 于是便有了本文開頭的精彩表現 。
對于 G2VLM 這樣一個擁有立體眼和空間腦的 AI 來說 , 它會打開通往更多應用的大門 , 比如打造更智能的機器人助手、打造沉浸感更強的 AR 和 VR、打造自動駕駛的安全衛士、打造人人可用的三維內容創作工具、打造強大的視覺問答與教育等 。
(來源:https://arxiv.org/pdf/2511.21688)
胡文博表示:“這項成果的首創性在于 , 我們是首個在當前主流視覺語言模型架構中 , 原生地集成了從二維圖片直接預測三維信息的能力 。 以往要理解三維空間 , 往往需要依賴深度圖、相機位姿等難以大規模獲取的額外標注信息 。
而我們的模型僅需任意角度拍攝的二維圖片 , 就能預測出三維信息 , 并用于空間理解 , 這使得模型能夠擴展到海量數據上進行訓練 , 更具實用性和可擴展性 。 ”
G2VLM 的突破性不止體現在測試成績里的那些數字 , 還在于它所蘊含的理念 。 那就是要想讓 AI 真正理解我們身處的物理直接 , 不能只讓它學習圖片和文字 , 還得教會它關于這個世界的底層的、根本的幾何與空間規則 。 “總之 , G2VLM 作為一個強大的基礎模型 , 可以為下游的具身智能模型提供預訓練支持 , 極大地增強其空間感知與操作能力 。 ”胡文博總結稱 。
另據悉 , 胡文博本科就讀于美國加州大學圣地亞哥分校 , 曾跟隨機器人學與具身智能領域專家蘇昊進行研究 , 接觸機器人機械臂和三維學習 , 這激發了他對 3D 和具身智能的濃厚興趣 。
隨后 , 胡文博跟隨計算機視覺專家屠卓文進入視覺語言模型領域 , 參與開發了早期開源 VLM 模型 BLIVA , 該模型在理解圖像中的文字和通用場景方面表現突出 , 相關論文發表在 AAAI 2024 , 獲得了數百次引用 。 這為胡文博當前的研究奠定了重要基礎 。
本科畢業后 , 胡文博在美國加州大學洛杉磯分校攻讀碩士學位 , 師從常凱威導師和彭楠赟導師(他們現在也是胡文博的博士導師) , 期間胡文博繼續專注于 VLM 與 3D 空間結合的研究方向 , 完成了一系列相關工作 , 相關論文發表在了 NeurIPS、ICLR 等機器學習頂級會議 還獲得了 CVPR Workshop 最佳論文 目前他依然在攻讀博士 。
參考資料:
相關論文 https://arxiv.org/pdf/2511.21688
【24歲博士生造出空間AI大師G2VLM,讓機器人眼明手快】運營/排版:何晨龍
推薦閱讀













- 一座AI工廠,鍛造出高效協同的智能紀元
- 半夜被AI「嚇醒」!57歲導師投奔24歲華人女學霸,打造AI數學家
- 剛剛,2026年英偉達獎學金名單公布,華人博士生霸榜占比80%
- CMU博士造出像素級自動對焦相機,開辟成像新范式
- 他為500強造出冠軍「AI裁員機器」!然后,把自己裁掉了
- MIT經濟學博士生,用AI騙過了諾獎導師、Nature、美國國會
- 日本嘲諷“造不出”?國產造出0.015mm手撕鋼,霸氣砍單16400億
- 特斯拉造出終結者之手!馬斯克要掙1000000000000美元
- 特朗普很興奮,美國芯片制造崛起,造出首款4nm英偉達AI芯片
- 黃仁勛站臺,臺積電美工廠造出首片英偉達Blackwell晶圓