文章圖片

文章圖片

文章圖片
豆包 , 可以視頻通話了 。
自年初更新「實時語音通話」功能之后 , 這一功能就持續受到用戶歡迎 。 現在在社交媒體上搜索豆包 , 排名前十的熱門關鍵詞中 , 有 6 個與「打電話」功能有關 。 大量和豆包通話相關的創意內容也受到了觀眾追捧 。
隨著視頻能力上線 , 豆包的通話功能迎來了一次「升維」 , 變得更實用、好用 。 結合視頻圖像 , 很多即便模糊的語音輸入 , 也能夠更好地被 AI 理解 , 用戶不需要再組織語言去描述眼前的信息 。
視頻通話是一個單點功能 , 但在這背后是語言能力、多模態能力、推理能力、知識庫等等多個垂直領域的技術積累、整合 , 以及對成本和效率的平衡 。
更重要的是 , 視頻通話能力預示了 AI 助手更遠的前景 。 當 AI 同時擁有了眼睛和耳朵 , 在未來更多硬件創新的支持下 , 還將解放更大的創新潛力 。
01幫你理解眼前一切的豆包
視頻通話能力給豆包帶來的 , 首先是多模態理解的能力提升和交互優化 。
從最基礎的「理解」場景開始 , 用戶可以把手機攝像頭對準任何信息 , 如信息版、菜單 , 讓豆包給出翻譯、解釋 。 而且過程中 , 用戶可以不斷通過語言輸入 , 來修正豆包的關注重點 。
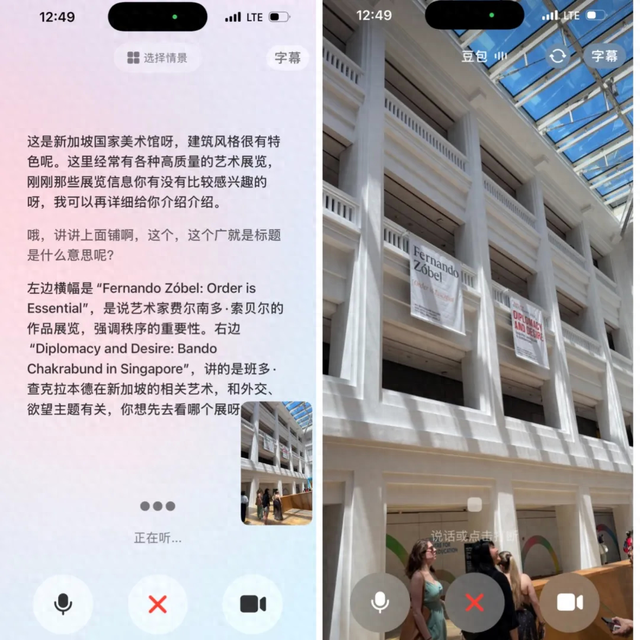
比如在一個博物館里 , 當我們開啟視頻通話 , 問豆包這是什么 , 豆包首先會根據畫面里的地標特征 , 識別出這是「新加坡國家美術館」 。 然后我們如果繼續追問 , 樓上掛著的橫幅是什么意思 , 豆包又會給出具體展覽信息的翻譯和解釋 。
而在看展覽的過程中 , 我們也可以舉著手機 , 隨時針對任何一幅作品向豆包發問 。 從基本的翻譯作品信息 , 到問它作品風格具體屬于哪一個派別 , 是否有模仿哪個藝術家的痕跡 , 豆包都能給出精準判斷 。
基于豆包給出的信息 , 我們也能進一步挖掘一些更深的隱藏關聯 。 比如在新加坡國家美術館里有一個法院拘留室的展示區域 , 問過豆包之后我發現 , 這里的關系在于 , 新加坡國家美術館由原政府大廈和原最高法院大樓改建而成 。 前法院的拘留室曾用于關押候審的被告 , 在美術館改建后 , 部分拘留室被保留了下來 , 成為了美術館的一部分 , 供公眾參觀 , 讓人們可以了解新加坡的司法歷史 。
除此之外 , 我們還可以和豆包講講自己對美術作品的一些理解和看法 , 進行觀點碰撞 。 實際上 , 豆包已經具備一定的「糾錯」能力 , 不是只會一味地順從用戶的理解 。 比如這里 , 當我引用了錯誤的類比 , 說這個作品像「蒙德里安」風格時 , 豆包能夠糾正我的錯誤 , 告訴我實際像的是安迪·沃霍爾 。 之后我們還可以進一步探討 , 為什么會出現這個錯誤 。 我們也可以引導豆包對作品進行批判性的解讀和評價 。
這里還有一個很關鍵的點 , 因為有了圖像視覺信息作為輔助 , 很多時候即便我發出指令的聲音很小 , 豆包并未完整識別我所說的句子的每一個字 , 但它依然能通過捕捉關鍵詞 , 準確理解我的意圖 。
在旅行、觀光、展覽……等視覺信息占比更高的場景 , 最能體現出豆包視頻通話能力的優勢 。 我們可以隨手舉起手機 , 讓豆包看到我們眼前的東西 , 從最基本的「這是什么?」出發 , 一點點挖掘出更多的信息和知識 。 比如讓豆包根據周邊的景色推理出我們在哪 , 推薦周邊值得一去的景點、活動、特色飲食 , 這既具有實用價值也充滿樂趣 , 適合出游不喜歡做嚴密的計劃 , 喜歡遇到更多偶然驚喜的 P 人 。
包括在餐廳吃飯 , 碰到那些「不知道該怎么吃」的情形 , 也很適合通過視頻通話功能求助豆包 。 比如吃蕎麥面的時候店員端上來一壺像熱水一樣的東西 , 這個時候豆包也輕松給出了正確答案 , 壺里裝的是蕎麥面湯 , 可以和醬汁混合在一起喝掉 。
豆包的視頻通話功能 , 相比普通的圖像識別 , 最關鍵的優勢依然在于它的「互動性」更強 。 基于單張圖像的理解和推理 , 很可能出現各種理解偏差、錯誤 。 有了視頻模式之后 , 即便豆包給出了一個比較可疑的回應 , 我們也可以通過換個角度 , 提供更多信息 , 來給豆包進行更多思考和修正的機會 。
比如在這個場景下 , 我們想知道酒店的某個裝置的作用 , 問豆包之后它首先以為我們問的是前面的熨衣板 。 經過進一步交互 , 它知道了我們想問的是后面的行李架 , 但因為角度問題 , 它將行李架錯誤理解成了健身器材 , 之后換個角度進一步追問并識別之后 , 豆包成功給出了行李架這一答案 。
這是視頻通話的功能的關鍵優勢之一 。 當下任何 AI 大模型都不可避免地會有「幻覺」和錯誤 。 當用戶精心編寫了一大段 prompt 卻沒有得到自己想要的輸出結果時 , 就會極大打擊他們使用 AI 的積極性 。 但通過給到更多信息 , 提供更多角度的輸入補充 , 就能讓 AI 更接近我們需要的正確答案 。 可以說 , 在視頻通話場景下 , AI 和用戶形成了互動的正向循環 。
除了日常生活場景 , 豆包的視頻通話功能還可以在學習、工作等各種場景發揮作用 , 特別是基于一些紙質的材料進行理解和修改 。 比如對多頁的紙質資料進行總結 , 或對學科題目進行解答、糾錯 。
02模型技術的「木桶理論」
「視頻通話」的功能本身非常簡潔 , 任何用戶理解起來都沒有門檻 , 但在這背后 , 其實需要復雜的技術作為支持 。
豆包視頻通話功能的核心來自「豆包視覺理解模型」的支持 。 2024 年 12 月 , 豆包首次發布視覺理解模型 , 為視頻通話功能提供了模型能力基礎 。
除了視覺感知之外 , 豆包視覺理解模型還具備深度思考能力 。 這讓豆包實際上還可以通過攝像頭直接進行解學科題目、分析論文以及診斷代碼等任務 。 這也是為什么在視頻通話過程中豆包能同時結合「圖像畫面」和「用戶語音指令」 , 精準理解用戶意圖 。
豆包并不是第一個實現這一功能的 AI 助手 , 但想要同時擁有優秀的視覺理解能力 , 再基于視覺理解和用戶指令 , 將不同模態的信息綜合理解后 , 生成用戶想要的信息 , 同時還要做到低延遲 , 這一切就有很高的技術門檻 。
整個過程有點像「木桶理論」 , 一個模型必須同時做好多個方面 , 才能做到像一個真實的「AI 助手」一樣 , 滿足用戶的需要 。
03為什么「視頻通話」能解鎖 AI 交互的更多創新?
今天 , 「視頻通話」只是豆包的一個小功能 。 但實際上 , 視覺理解能力所蘊含的潛力和可能性還不止于此 。
自誕生至今 , 大模型 AI 助手的交互都是「一問一答」式 , 用戶輸入 prompt , AI 生成反饋 。 這里最大的矛盾在于 , 整理編寫 prompt 是有門檻的 , 且這個門檻比想象中更高 , 而一問一答式的交互又是斷裂的 , 大家都很容易「把天聊死」 , 面對 AI 也一樣 。
而視覺圖像的引入 , 則為人機交互建立了一個「語境」 , 且這個語境的建立不需要任何門檻 , 天然富含信息 , 用戶只需要舉起攝像頭就行了 。 實際上 , 人類自身理解世界的過程中 , 我們最重要的信息接收器官也一直是眼睛 。
通過豆包的視頻通話功能 , 這一模式的有效性已經得到體現 。 通過連貫的互動加上視覺理解 , 用戶和 AI 交互的過程變得更自然了 , 可以通過不斷補充、解釋 , 來接近自己想要的那個目標 。 這種用戶和 AI 互相引導 , 對 propmt 進行不斷修正 , 能極大增加 prompt 輸入的帶寬和精確度 。
實際上 , 這早就是行業共識 。 自 AI 大模型技術誕生之后 , 幾乎所有硬件創新都是在探索一種「攝像頭+麥克風」的組合 , 從 AI Pin , 到各種 AI 智能眼鏡 , 都是在建立一種讓 AI「看+聽」的感知模式 。 只不過目前大部分這類硬件 , 都還無法在性能和效率上 , 做到像手機那么高的可行度 。
當下我們在使用豆包的視頻通話功能時 , 依然能感受到它被手機這個硬件載體限制著 。 比如我們很難長時間舉著手機對準前方我們看到的東西 , 以及在一些公共場合也不便于大聲說話 , 無法和 AI 充分進行語音溝通 , 這都是智能手機作為傳統硬件的限制所在 。
【豆包為什么要給 AI 助手「開眼」?】從豆包的「視頻通話功能」已經可以看出 , 讓 AI「看+聽」的輸入模式 , 可能代表 AI 交互的更多可能性 。 它在軟件上完全是可行的 , 隨著模型能力的進一步發展 , 結合硬件創新 , 或許將進一步改變我們與 AI 的交互方式 。
推薦閱讀












- 為什么我這么多年,一直用蘋果iPhone,不換安卓手機?
- 為什么有人就是不“待見”華為手機?3個原因“扎心”又現實!
- 華為,為什么讓我們如此自豪?
- 為什么內行人更推薦榮耀200 Pro,而不是榮耀300?因為優勢明顯!
- 為什么手機廠商不愿配備10000毫安大電池?
- 為什么廠商癡迷于大電池數字?簡單原因用戶太好騙!
- 為什么說RGB-Mini LED電視是世俱杯球迷的終極選擇?三大優勢解析
- 華為千億估值的“獨角獸”,為什么選擇布局重慶?
- 為什么國人寧愿買蘋果,不愿買國產高端,4點原因很現實
- 宗熙先生:什么是EDA軟件?它的功能是什么?為什么如此重要?