
文章圖片

文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
白交 發自 凹非寺
量子位 | 公眾號 QbitAI
最近3D內容生成模型好生熱鬧 , 像谷歌Genie 3、World Labs、混元、昆侖爭相發布并開測世界模型 。
一片喧囂中 , 杭州“六小龍”之一群核科技低調卻重磅地發布了自己的空間大模型 , 選擇了一條與眾不同的路徑:
深耕室內場景 , 并直指行業核心痛點「空間一致性」 。
不管怎么移動都很絲滑~生成的視角也都是合理的 。
從視頻生成到AI短劇 , 令人出戲的空間穿幫、扭曲視角和斷裂邏輯屢見不鮮 , 往往需要反復調教才能勉強可用 。 空間一致性 , 已成為橫亙在虛擬世界與現實世界之間的最大技術壁壘 。
當前主流技術路線可以分為兩類 , 一類是以Genie 3為代表的“視頻生成派” , 雖能生成動態交互內容 , 但本質仍是二維序列的仿真 。 雖然視覺效果很逼真 , 但難以從根本上保證三維空間的視角與結構一致性 。
另一類則是以World Labs、混元為代表的“3D場景生成派” , 雖能實現360度漫游 , 卻受限于高質量3D數據的匱乏 , 時常在視角切換中出現場景崩壞、內容穿幫問題 。
而群核的空間大模型 , 正是致力于突破當前模型遇到的這些挑戰 。
它不僅在三維空間的視角一致性上表現得可靠 , 其漫游自由度和真實感上也更具優勢 。
而要了解這一最新突破 , 首先需要回答一個更根本的問題:什么是空間大模型?
空間大模型是什么?作為AI從數字世界走向物理世界的關鍵 , 李飛飛曾將空間智能的理論框架分為四個維度 , 分別是空間認知理解、空間推理、空間交互行為與空間生成 。
當前大模型主要局限于文本、圖像等二維交互領域 , 但在三維空間操作(如家務協助)方面仍有距離 。 像掃地機器人能感知障礙物 , 卻無法理解“花架可移動而承重墻不可撞”的空間常識 。
解決這一問題的關鍵在于真正的空間理解和認知能力 , 并且在此基礎上具備交互行為 。 這既是空間智能的核心價值 , 也是空間大模型區別于其他AI「二維轉三維」探索的最大特點 。
不過空間大模型具體能干啥?群核科技的發布 , 讓這一概念變得清晰可見 。
用群核首席科學家周子寒的話說 , 群核空間大模型具備三個特點:真實感全息漫游場景、可交互性以及復雜空間處理能力 。
此次他們開源的兩個子模型——空間語言模型SpatialLM1.5和空間生成模型SpatialGen正是最佳例證 。
首先 , 真實感全息漫游場景 。
在世界模型中 , 漫游自由度是衡量智能體在虛擬或仿真環境中空間探索能力的關鍵指標 , 它直接反映了世界模型對物理空間的建模精度和交互靈活性 。 背后這不僅依賴于環境建模 , 還有對物理規則的理解程度 。
不過因為開源3D場景數據稀缺 , 用戶在創作一個空間時很難保證每個視角都有合理的內容 , 比如離開指定環境就出現崩壞或者內容缺失的情況 。
此次開源的SpatialGen , 正是基于擴散模型架構 , 它可根據文字描述、參考圖像和3D空間布局 , 生成具有時空一致性的多視角圖像 。 然后采用一種全新3D高斯重建技術來還原3D場景 。
在這個場景里 , 用戶可以四處走動 , 仿佛置身其中 。
其次是可交互 。
世界模型的一個很重要愿景在于希望它能模仿真實場景中的各種交互 , 機器人也可以在里面進行移動 。
前面提到掃地機器人不懂空間常識 , 那如果將各種物理參數等詞匯都保存在模型中 , 機器人是不是就能在一個可交互場景中去完成任務了呢?
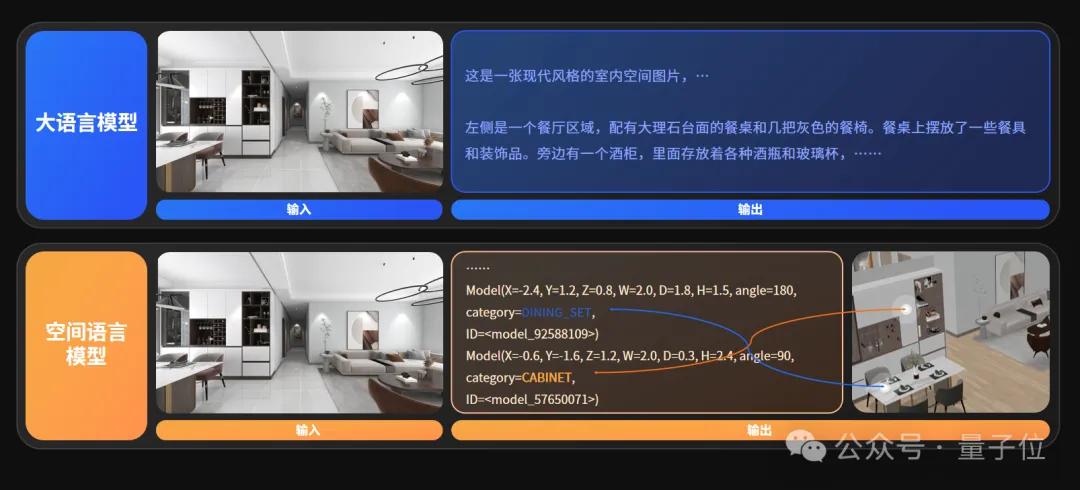
此次他們發布的另一個模型SpatialLM 1.5 , 首次定義了空間語言這一概念 。
什么是空間語言?
像傳統自然語言模型 , 你給它一張圖 , 它會用自然語言來描述圖中的內容 , 這就有點像文科生 。
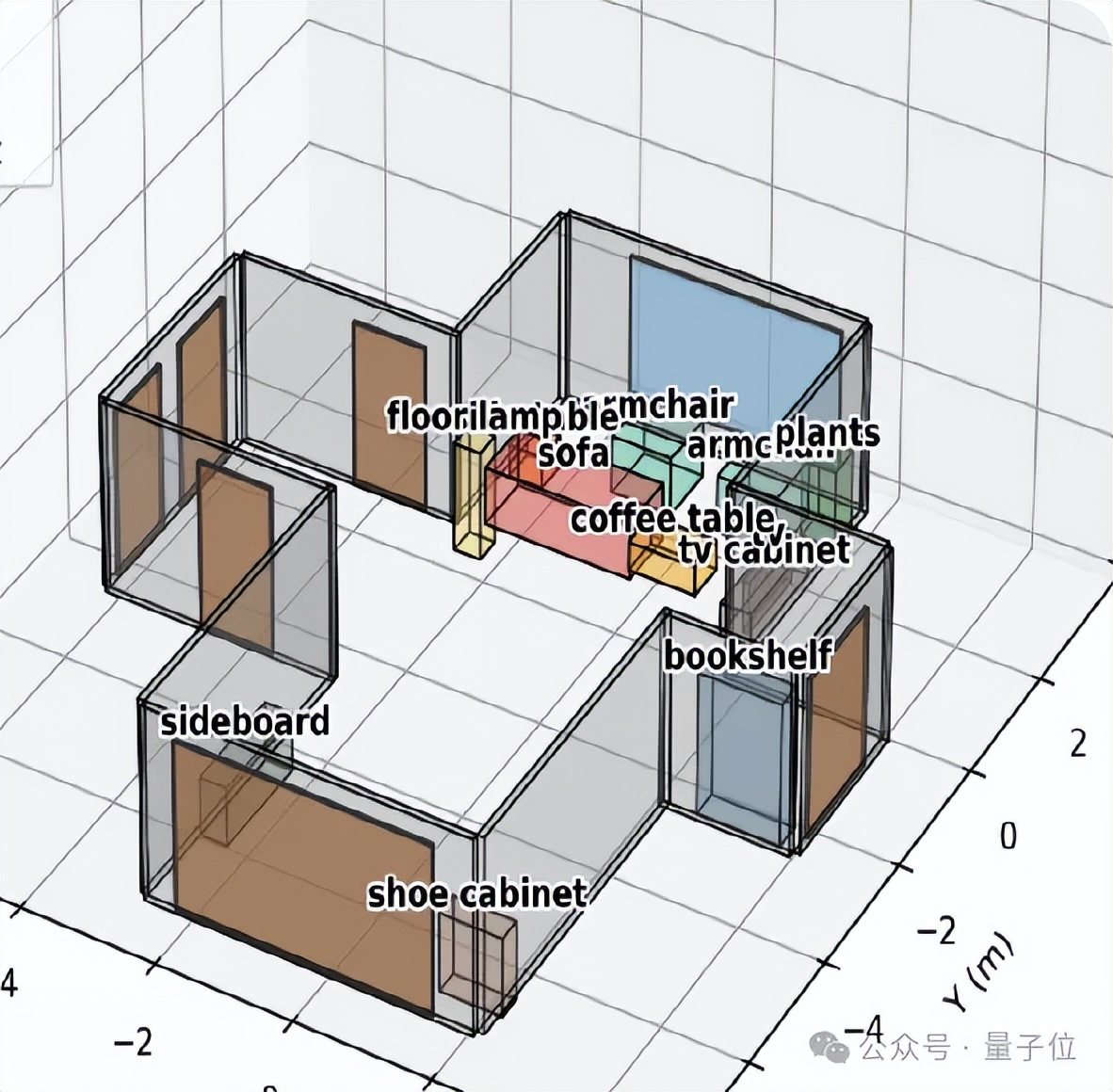
但空間語言就更像是理科生 , 給它一張圖就獲得整個場景完整的3D信息 。 它會用坐標軸去描述每個物體中的空間位置 , 包括它的形狀、姿態描述 , 甚至還包括物體的各種物理屬性等 。
這種參數化的場景描述方式 , 使模型既能支持精準的空間生成與編輯 , 又能為機器人處理復雜任務提供支持 , 這是傳統模型無法帶來的獨特優勢 。
先來看空間生成 , 不妨拿GPT-5來做下對比測試 。
給GPT-5一張空間圖 , 并且補充空間語言的描述 , 讓它基于對空間的理解擺放常見的家具 。
結果經過可視化后看到 , 它并沒有對圖片有很好的理解 , 甚至還將原來的輪廓變成了四方形 。
而設計更復雜的Prompt , 讓它能充分理解空間信息之后再去創作 。
這次房間輪廓沒有問題 , 不過家具都擺在了一個房間角上了 。
同樣的圖扔給SpatialLM1.5 , 僅用自然語言先讓它生成三維空間 , 然后在空間里放些家具 , 并且再加上約束:適合老人居住 。
可以看到 , 它將沙發放到了左邊 , 對面有一個電視機柜 , 旁邊還有個輪椅 , 應該是基于「適合老人居住」的理解 。
再來看復雜空間任務處理能力 。 SpatialLM1.5可以被打造成AI Agent框架 , 通過調用工具來擁有更多的空間能力 。
比如完成機器人常見的路徑規劃任務 。
根據“從臥室床邊到客廳”的指令 , 模型能夠基于空間理解能力 , 調用路徑規劃工具生成合理路線 。
不過這只是群核空間大模型的階段性探索 。 群核坦言 , 相比于文本、圖像 , 空間大模型仍處于較早期的階段 。 如果以GPT系列作類比 , 現在相當于處在GPT-2階段 。
從這里能夠看到 , 要想讓模型出現涌現能力 , 數據正是其中的核心突破點 。
而從過去種種進展能夠看到 , 室外場景的探索很多 , 但聚焦在室內場景的很少 。 而正在探索并且探索得比較好的 , 可能就只有群核一個 。
空間模型仍處于GPT-2階段這與業內正在面臨的現實挑戰緊密相關 , 關鍵問題有三個 。
首先 , 數據稀缺性與獲取成本高企 , 尤其是室內空間數據 。
不同于語言模型可利用互聯網公開文本 , 空間智能嚴重依賴真實世界的3D掃描與傳感器數據 , 采集成本極高 。 室內場景的數據獲取更受限于隱私合規、環境多樣性、動態物體干擾等多重約束 , 導致規模化數據積累困難 。
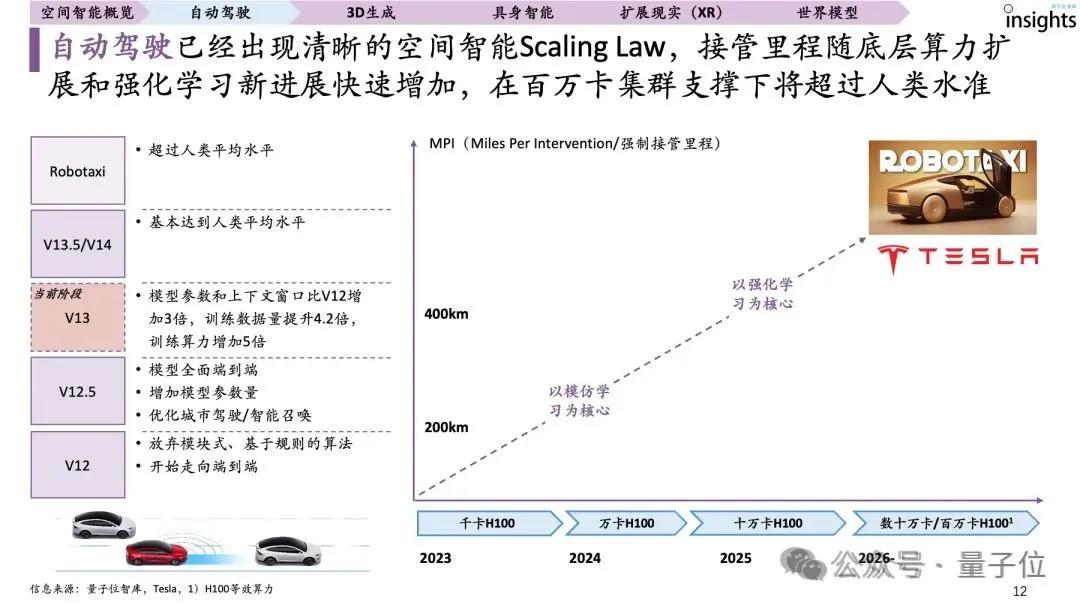
據量子位智庫報告顯示 , 以室外為主的自動駕駛行業已經出現了空間智能的Scaling Law , 但室內卻遠遠未到 。
其次 , 場景復雜度高 , 空間語義理解難度大 。
室內環境在空間結構、物體分布與功能邏輯上高度復雜 。 相比規則化的道路場景 , 家居、辦公等室內布局異構性強 , 物體間空間關系與功能語義細膩多元 。 例如 , 理解“將杯子放在桌面上”這類簡單指令 , 不僅需識別物體 , 還需推斷桌面的承重特性、杯子的幾何穩定性及人物交互上下文 , 對模型的深層認知提出極高要求 。
最后 , 交互需求復雜 , 任務泛化能力更具挑戰 。
室外自動駕駛的交互模式相對封閉 , 行為可抽象為有限集合(如路徑規劃、避障等);而室內任務需響應開放指令 , 如“把餐桌旁的椅子推進去”或“找到臥室最亮的燈并關閉” , 要求模型兼具動態環境感知、物理常識推理與多步任務分解能力 。
現有模型多局限于靜態環境建模 , 缺乏對動作后果預測、物理規律嵌入與人類意圖的理解 , 導致復雜交互泛化能力顯著不足 。
從這里看到 , 數據雖是核心瓶頸 , 但破局不能僅依賴數據規模 。
放眼行業 ,群核提出「三位一體」的技術戰略 , 也許就能成為行業突破口 。 這里的「三位一體」 , 指的是空間編輯工具、空間合成數據和空間大模型 , 所構成的正向循環閉環 。
工具側 , 他們打造了全球最大空間設計平臺 , 此外還有COOHOM、棚拍、群核酷空間等來構建和編輯三維世界 。 設計師和用戶在平臺上快速創建可交互場景 , 尤其是裝修設計方案 , 在真實世界中會被實施 , 從而極大地保證了其物理正確性 。
而在數據層 , 通過空間編輯工具的持續使用 , 群核沉淀了全球最大的室內空間深度學習數據集InteriorNet 。 截至2024年 , 公司擁有超過4.41億個3D模型和超過5億個結構化3D空間場景 。 此外 , 還開源了首次將3D高斯引入AI空間訓練的3D高斯語義數據集InteriorGS 。
工具帶來了海量數據的沉淀 , 海量數據加速了模型的迭代 , 模型的升級進而提升了工具的體驗 , 工具的優化進一步帶來更豐富的場景和數據 , 這一閉環使群核科技在空間智能領域具備了獨特的優勢 , 并致力于成為全球空間智能基礎設施 。
基于這樣的技術飛輪 , 很多行業關鍵問題得到了探索和解決 。
比如像前面提到的空間一致性問題、機器人訓練問題 。
值得一提的是 , 他們專門為視頻生成構建了個全新的可控工具 , 這個工具是基于SpatialGen空間生成能力、自研渲染引擎KooEngine與DIT架構視頻生成模型的深度融合 。
高質量3D可交互的數據庫 , 顯著降低了真實3D場景的構建門檻;通過物理級光線追蹤渲染 , 生成了與人類視覺認知一致的空間表達;并借助DIT模型強大的時空建模能力 , 在保持空間一致性的前提下實現了動態內容的豐富生成 。
最終只需用戶簡單的輸入 , 工具就能生成符合真實物理規律和用戶需求的視頻 。 據群核透露 , 這個產品將在年內發布 。
空間智能的第三條路徑當前 , 空間智能領域正處在一個充滿探索與機遇的“前爆發期” 。 各路玩家依據自身技術積累 , 已經可以劃分成三種不同的路徑 。
一種是以世界模型/視頻生成玩家為代表 , 他們主要通過海量視頻數據訓練 , 追求生成高質量、長時序的視頻內容 。 然而 , 大多模型本質仍然還是2D像素序列的預測 , 在三維空間的結構性理解、視角一致性和物理規則遵循等方面存在先天不足 , 難以實現可控的空間交互 。
另一類則是以具身智能、自動駕駛玩家為代表 , 他們致力于在復雜真實的物理世界中實現感知、決策與行動 。 這條路徑聚焦在高度規則性的室外場景 , 難以直接遷移和泛化到布局異構、交互意圖多變的室內環境中 。
還有一種 , 就是以群核為代表的原生空間智能路線 。 這類玩家從一開始就深耕三維空間 , 尤其是被行業相對忽視的室內場景 。 它們致力于構建具有精確幾何、物理屬性和語義關系的數字孿生空間 。 其核心是對空間本身的理解、生成與交互 , 而非簡單視覺內容生成 。
盡管方向各異 , 但整個領域仍面臨共通的、嚴峻的挑戰——
室內數據的稀缺與高成本、場景語義理解的復雜性、以及開放交互任務的泛化能力不足 。
這些就決定了空間智能發展仍處于比較早期的階段 , 尚未出現GPT-4那樣的涌現 。 這也是群核此次選擇將模型開源的主要原因:
通過降低技術門檻 , 吸引大量的研究者、開發者乃至行業玩家參與其中 , 共同應對行業挑戰 。
當然這也不是群核第一次開源 。 今年3月 , SpatialLM 1.0版本開源 , 迅速登上Hugging Face趨勢榜前三 。 目前已有初創企業基于其代碼和架構訓練出自有模型 。
而此次通過開源 , 群核能夠帶動行業快速構建以“空間語言”為核心的標準和生態 。 當越來越多的玩家基于群核的開源工具和數據集進行開發時 , 整個領域的數據沉淀速度、技術迭代頻率和應用場景創新都將得到快速增長 。
其最終目的 , 自然是加速空間智能演進 , 一起做大產業蛋糕~
這多少也是“杭州六小龍”的共同特點 , 雖然所處的賽道不同 , 但每一家幾乎都是技術驅動的平臺型公司 。
宇樹打造了一個機器人本體平臺 , DeepSeek打造了基礎大模型平臺……群核科技則是站在空間智能方向上 , 正在打造一個面向空間智能開發和落地的賽道級平臺 。
(更多效果可以前往公眾號查看)
Hugging Face:https://huggingface.co/manycore-research/SpatialGen-1.0Github:https://github.com/manycore-research/SpatialGen魔搭社區:https://modelscope.cn/models/manycore-research/SpatialGen-1.0
— 完 —
量子位 QbitAI · 頭條號簽
【空間智能卡脖子難題被杭州攻克!難倒GPT-5后,六小龍企業出手了】關注我們 , 第一時間獲知前沿科技動態約
推薦閱讀














- 九號公司發布M5系列智能電摩,EVA初號機聯名與凌波OS同步登場
- 九號公司發布凌波OS,兩輪出行行業邁入智能生態新階段
- dynabook高端輕薄筆電Portégé X40-M:商務辦公的智能伙伴
- 谷歌全新Nest智能家居產品系列曝光
- 國內智能手機榜單更新:蘋果第6,小米第3,第1名拿下10連冠
- 石頭智能洗地機A30 Pro Ultra:泡沫去污能力驚人 95度自清潔無憂
- AI智能體加持,爆款視頻產出速度提升了10倍,全民導演時代已來
- 7月中國智能手機榜單洗牌:小米排名第二,第一名遙遙領先
- 揭秘小鵬機器人:挖來英偉達大牛,產線已落地幾百臺|智能涌現獨家
- “A計劃”發布!智元機器人董事長鄧泰華:全球正處于具身智能大爆發前夜