
文章圖片

文章圖片
文章圖片
文章圖片
文章圖片
機器之心報道
編輯:冷貓、杜偉
前些天 , DeepSeek 在發布 DeepSeek V3.1 的文章評論區中 , 提及了 UE8M0 FP8 的量化設計 , 聲稱是針對即將發布的下一代國產芯片設計 。
這件事一下引發了巨大反響 , 不僅是關于新一代國產芯片設計、大模型在國產芯片訓練的話題 , 也順勢引發了大家對大模型量化策略的關注 。
FP8 , 其全稱為 8-bit floating point(8 位浮點數) , 是一種超低精度的數據表示格式 , 相較于 FP32(單精度)或 FP16(半精度)等傳統浮點格式 , FP8 可以在盡量保持數值穩定性和模型精度的前提下 , 進一步降低存儲和計算開銷 。
在英偉達之外 , Meta、英特爾、AMD 等也都在研究 FP8 訓練與推理 , 有成為業界「新黃金標準」的趨勢 。
@梁斌 penny 在微博上的文字引起了比較熱烈的討論:
雖然言論有些絕對 , 但是 DeepSeek 采用了非主流的 FP8 量化策略 , 隱隱展現出國產大模型與國產芯片芯片軟硬結合的優化策略與英偉達的高兼容策略的不同發展路徑 。
UE8M0 FP8 具有鮮明的戰略意義 。 DeepSeek 選擇在模型端率先采用并公開聲明使用 UE8M0 格式 , 將其訓練與 scale 策略與該精度綁定 。 這等于由大模型端主動提出標準 , 迫使硬件和工具鏈進行適配 , 加速了國產軟硬件一體化的生態建設 。
不知道是不是巧合 , 在 DeepSeek 為國產芯片準備的 FP8 量化策略的提出不久 , 就在今天 , 英偉達也在低精度量化領域再次發力 。 只不過這次不是 FP8 量化的新進展 , 而是向 FP4 量化躍進 。
英偉達將其最新的 NVFP4 策略拓展到預訓練階段 , 聲稱能夠以 16 位精度進行訓練 , 并以 4 位的速度和效率運行 。
英偉達稱:「在預訓練中使用 NVFP4 , 可顯著提升大規模 LLM 訓練效率和基礎設施效能 。 這不僅是一次漸進式優化 , 而是一種重新定義大規模模型訓練方式的根本性轉變 。 」
在「AI 工廠」時代 , 算力是進步的引擎 , 數值精度已不再是后端細節 , 而是一種戰略優勢 。 NVFP4 4 比特預訓練為效率與可擴展性設定了新的標準 , 推動高性能 AI 模型開發進入全新階段 。
目前 , NVFP4 訓練仍處于研究階段 , 正在探索并驗證 4 位精度在大規模模型預訓練中的潛力 。 圍繞 NVFP4 的合作與實驗正積極推進 , 參與方包括 AWS、Cohere、Google Cloud、Kimi AI、Microsoft AI、Mistral、OpenAI、Perplexity、Reflection、Runway 等領先組織 。
對于英偉達在更低位的探索 , 評論區的網友意見不一 , 有人認可 NVFP4 在提升訓練速度以及降低成本和能耗方面的積極作用 , 認為其有望推動更多行業進入高效、可持續的 AI 時代 。
還有人提到 NVFP4 與 Jetson Thor 的結合有望對現實世界的應用產生深遠影響 。 Jetson Thor 是英偉達前幾日發布的新一代機器人專用芯片 , 通過大幅提升算力 , 可以適配具身智能新算法 , 支持人形機器人等各種形態 。
二者可能的結合 , 一方面在訓練端帶來更高的能效與速度優化 , 另一方面在邊緣、推理場景充分利用高性能低功耗的計算能力 , 最終從訓練到部署形成高效的完整閉環 。
不過也有人不買賬 , 針對英偉達聲稱的更環保(greener) , 他認為 , 雖然新的數據格式帶來了種種優化 , 但并不代表 AI 的總體算力需求和能耗會因此減少 , 也無法從根本上改變 AI 持續擴張造成的能源與資源壓力 。
【DeepSeek剛押注FP8,英偉達就把FP4精度推向預訓練,更快、更便宜】
什么是 4 比特量化(4-bit quantization)?
4 比特量化指的是將模型中的權重和激活值的精度降低到僅僅 4 位 。 這相比常見的 16 位或 32 位浮點數格式 , 是一次大幅度的精度壓縮 。
在預訓練階段使用 4 比特量化非常具有挑戰性 。 因為需要在保持訓練速度提升的同時 , 謹慎地處理梯度和參數更新 , 以確保模型精度不會丟失 。
為了達到這個目標 , 英偉達必須使用專門的技術和方法 , 把原本高精度的張量(tensor)映射到更小的量化值集合中 , 同時仍然維持模型的有效性 。
更少的比特如何釋放 AI 工廠的更大潛能
近些年來 , AI 的工作負載呈現爆炸式增長 —— 不僅僅是在大語言模型(LLM Large Language Model)的推理部署中 , 還包括基礎模型(foundation model)在預訓練和后訓練階段的規模擴張 。
隨著越來越多機構擴展計算基礎設施 , 用來訓練和部署擁有數十億參數的模型 , 一個核心指標逐漸凸顯:AI 工廠能維持多高的 token 吞吐量 , 從而解鎖下一階段的模型能力 。
在推理(inference)環節 , 精度格式已經經歷了多次革新:從最初的 FP32(32 位浮點數)到 FP16 , 再到 FP8 , 最近甚至發展到 NVIDIA 發布的 NVFP4 , 用于 AI 推理 。 實踐表明 , 像后訓練量化(PTQ)這樣的方法 , 已經能夠借助 NVFP4 顯著提升推理吞吐量 , 同時保持準確性 。
然而 , 在更上游的預訓練階段 , 挑戰依然存在 —— 目前大多數基礎模型仍依賴于 BF16 或 FP8 來維持穩定性和收斂性 。
預訓練恰恰是 AI 工廠消耗最多計算力、能耗和時間的環節 。 算力預算有限 , GPU 時鐘周期稀缺 , 開發者必須精打細算 —— 從每一個比特、每一個 token , 到每一個訓練周期都要計算在內 。 吞吐量在這里不只是一個抽象指標 , 它直接決定了:能夠訓練多大規模的模型 , 可以運行多少實驗 , 又能多快迎來新的突破 。
這就是 4 位精度真正具備顛覆性意義的地方 。
通過減少內存需求、提升算術運算吞吐量、優化通信效率 , 4 比特預訓練能夠讓 AI 工廠在相同的硬件條件下處理更多的 token 。 只要配合合適的量化方法 , 它的精度表現可以與 FP8 或 BF16 相當 , 同時還能顯著提升吞吐量 。
這意味著:
模型收斂速度更快; 單位算力能運行更多實驗; 可以訓練出前所未有規模的前沿模型 。換句話說 , 更少的比特不僅僅是節省成本 , 它還拓展了 AI 工廠的能力邊界 。
NVFP4 預訓練量化方案
為了實現 4 位精度的預訓練 , 英偉達開發了一套專門的 NVFP4 預訓練方案 , 解決了大規模訓練中動態范圍、梯度波動以及數值穩定性的核心挑戰 。
Blackwell 是 NVIDIA 首個原生支持 FP4 格式的架構 。 GB200 和 GB300 上巨大的 FP4 FLOPs 吞吐量 , 通過加速低精度矩陣運算 , 同時保持大模型收斂所需的規模和并行性 , 從而實現高效的 4 比特訓練 —— 使其成為下一代基于 FP4 的 AI 工廠進行預訓練的理想選擇 。
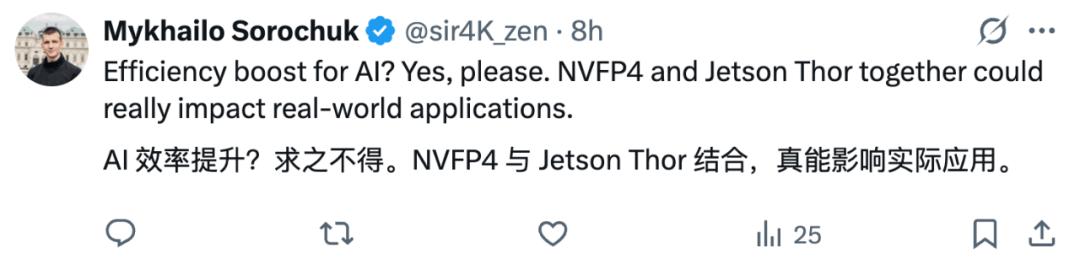
下圖 1 顯示了 Blackwell Ultra 的 GEMM 性能測量結果 , 相比 Hopper 代實現了 7 倍加速 。 現代大語言模型(LLM)在本質上依賴矩陣乘法 , 尤其是在其全連接層或線性層中 , 矩陣乘法是核心計算元素 。 因此 , 這些運算的效率至關重要 。
FP4 精度能夠更快、更高效地執行這些運算 , 所觀察到的 GEMM 加速意味著整個預訓練過程都顯著加快 , 從而縮短訓練時間 , 并支持更大規模模型的快速開發 。
圖 1:測得的 GEMM 性能顯示 , GB300 相比 Hopper 實現了 7 倍加速 , 通過更快的 FP4 優化矩陣乘法加速了核心 LLM 訓練操作 。
為了實現高效的低精度訓練 , NVIDIA 的 NVFP4 預訓練方案采用了多項關鍵技術 , 這些技術是基于性能和精度精心選擇的 , 包括:
1. 利用 NVFP4 的微塊縮放增強數值表示
Blackwell 引入了對 NVFP4 的原生 Tensor Core 支持 。 NVFP4 是一種 4 位數值格式 , 可用于權重和激活值 , 采用微塊縮放技術 —— 每 16 個 4 位元素共享一個公共縮放因子 。 相比 MXFP4 將塊大小設為 32 元素 , NVFP4 將塊大小縮小至 16 元素 , 從而減少異常值的影響 , 實現更精確的縮放 。 更細粒度的縮放降低了量化誤差 , 提升了模型整體精度 。
2. 使用 E4M3 縮放因子的 NVFP4 高精度塊編碼
縮放因子精度在量化質量和精度中至關重要 。 不同于僅限于 2 的冪(E8M0)且易產生高舍入誤差的 MXFP4 , NVFP4 使用帶額外尾數位的高精度 E4M3 縮放因子 。 這允許更細粒度的縮放 , 更有效利用有限的量化區間 , 并在塊內更準確地表示數值 。
3. 重塑張量分布以適應低精度格式
LLM 預訓練期間的梯度和激活值通常存在大幅異常值 , 這會影響低精度量化 。 對 GEMM 輸入應用 Hadamard 變換 , 可將其分布重塑為更接近高斯分布 , 從而平滑異常值 , 使張量更容易被精確表示 。 這些變換對模型結構是透明的 , 可在前向和反向傳播的線性層中應用 。
4. 使用量化技術保持數據一致性
為了確保訓練穩定高效 , 英偉達采用保持前向和反向傳播一致性的量化方法 。 諸如選擇性二維塊量化等技術 , 有助于在整個訓練周期中保持張量表示的對齊 。 這種一致性對于最小化信號失真、改善收斂行為、增強整體魯棒性至關重要 , 尤其是在 NVFP4 等低精度格式下 。
5. 通過隨機舍入減少偏差
與傳統(確定性)舍入總是向最接近的可表示值舍入不同 , 隨機舍入會根據數值在兩個可表示值之間的位置 , 按概率向上或向下舍入 。 這一步驟對于減少舍入偏差、保持訓練期間梯度流動以及最終提高模型精度至關重要 。
圖 2:英偉達的 NVFP4 預訓練技術 , 用以實現高效低精度訓練 。
萬億級 Token 規模下的精度與穩定性
要讓低精度格式在大規模預訓練中實用 , 必須同時保證模型精度和收斂穩定性 。
為了評估 4 位精度在大規模模型訓練中的可行性 , 英偉達在一個 120 億參數的混合 Mamba-Transformer 架構模型(12B Hybrid Mamba-Transformer)上進行了 FP8 和 NVFP4 的實驗 。
該模型類似于 NVIDIA Nemotron Nano 2 , 它在包含 10 萬億個 token 的超大數據集上進行訓練 , 采用分階段數據混合策略:在訓練的 70% 階段切換到不同的數據集混合 , 在預訓練的 90% 階段進行第三階段數據切換 。
該 12B Hybrid Mamba-Transformer 模型的一個版本最初使用 8 精度(FP8)進行訓練 。 之前的研究表明 , FP8 的精度與 16 位精度非常接近 , 因此 FP8 被作為英偉達的基線進行對比 。
隨后 , 英偉達成功地從零開始使用 NVFP4 訓練同樣的 12B 模型 , 證明這種新的低精度格式可以支持萬億級 Token 規模的完整預訓練 。 并且 , NVFP4 在訓練過程中表現出穩定的收斂性 , 沒有通常困擾超低精度訓練的不穩定性或發散問題 。
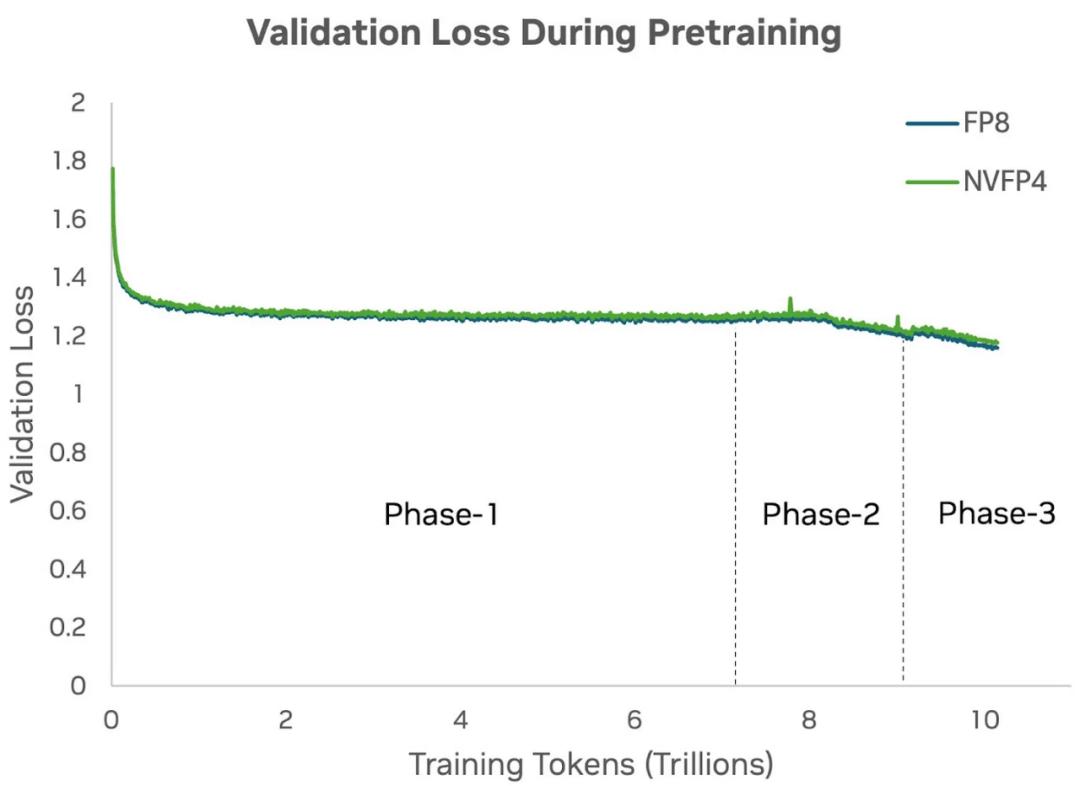
下圖 3 顯示 , NVFP4 的驗證損失曲線在整個訓練過程中與高精度基線(即 FP8)的損失曲線高度一致 。 上述量化技術確保即使在大幅降低位寬的情況下 , 4 比特預訓練的動態表現仍與高精度訓練非常接近 。
圖 3:在對 120 億參數的 Hybrid Mamba-Transformer 模型進行預訓練時 , 對比使用 FP8 與 NVFP4 精度在 10 萬億 tokens 下的驗證損失結果顯示 , NVFP4 的損失曲線在整個訓練過程中與 FP8(基線)的曲線高度吻合 。
隨后 , 英偉達使用 NVFP4 預訓練 120 億參數的 Hybrid Mamba-Transformer 模型 , 并與更高精度的 FP8 基線在多個下游任務與智能領域進行了對比 。
如下圖 4 所示 , 在所有領域中 , NVFP4 的準確率表現均與 FP8 相當 , 甚至在代碼領域實現了反超 , 展現了其有效性 。 該結果進一步強化了最初的假設:即使在萬億 token 規模下 , NVFP4 依然是大語言模型預訓練的穩健選擇 , 驗證了其在高效大規模前沿模型訓練中的潛力 。
圖 4:分別使用 FP8 精度(基線)和 NVFP4 精度 , 對 120 億參數的 Hybrid Mamba-Transformer 模型進行預訓練 , 此時的下游任務準確率對比 。
聰明訓練 , 而不是一味加碼
根據英偉達的說法 , NVFP4 格式正在重新定義 AI 訓練的格局 , 并可以為實現速度、效率和有目的創新設立新的標桿 。 通過實現 4 比特預訓練 , NVFP4 讓 AI 工廠更快、更可持續地擴展 , 為全新的生成式 AI 時代打下基礎 。
另外 , 作為一種動態且不斷演進的技術 , NVFP4 將持續為前沿模型團隊創造新的機遇 , 推動節能高效和高性能的 AI 發展 。 憑借計算效率的突破 , 4 比特預訓練將賦能更先進的架構、更大規模的訓練和 token 處理 , 從而為未來的智能系統注入新的動力 。
原文地址:https://developer.nvidia.com/blog/nvfp4-trains-with-precision-of-16-bit-and-speed-and-efficiency-of-4-bit/
推薦閱讀












- DeepSeek“極你太美”bug,官方回應了
- 剛剛,大模型裝上鷹眼!首創高刷視頻理解,谷歌Gemini 2.5完敗
- 紅杉資本押注的新賽道,要“入侵”你的聊天機器人
- 機器人硬件剛過了最亂的時候
- 剛剛,馬斯克開源Grok 2.5:中國公司才是xAI最大對手
- DeepSeek終于還是沒憋住!
- 2025 年《財富》中國科技50強榜單揭曉: 華為登頂,Deepseek第二
- 為什么DeepSeek從年初“國運級”到現在熱度減退,問題出在哪里?
- 影石剛發布的這臺口袋相機,建議友商直接“抄作業”
- 美國要慌了?Deepseek,全面適配國產AI芯片了