
文章圖片

文章圖片
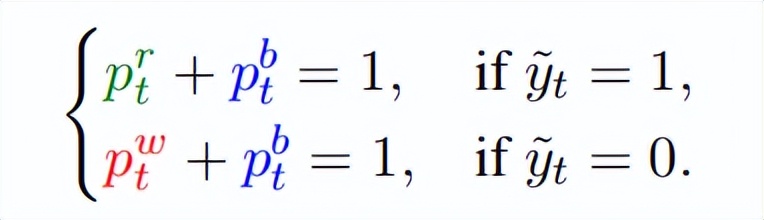
文章圖片
本文由北京中關村學院、哈爾濱工業大學、中科院自動化所等多家單位作者共同完成 , 第一作者為北京中關村學院與哈爾濱工業大學聯培博士生俞斌 , 指導教師包括:哈爾濱工業大學教授哈工大青島研究院院長王佰玲 , 北京中關村學院中關村人工智能研究院具身智能方向負責人陳凱 。
研究背景:Test-Time Scaling 的兩種范式
在大語言模型(LLM)席卷各類復雜任務的今天 , “測試時擴展”(Test-Time Scaling , TTS)已成為提升模型推理能力的核心思路 —— 簡單來說 , 就是在模型 “答題” 時分配更多的計算資源來讓它表現更好 。 嚴格來說 , Test-Time Scaling 分成兩類:
內部 Test-Time Scaling:以 DeepSeek-R1 為代表的推理型大模型通過拉長思維鏈來實現內部的測試時擴展 。 外部 Test-Time Scaling:讓模型在回答問題時進行并行推理得到多個推理路徑 , 然后通過聚合這些不同的推理路徑來得到最終的答案 。
隨著各種改進推理思維鏈方案的提出 , 通過內部 Test-Time Scaling 來提高模型性能的方法逐漸接近瓶頸 , 這時更好的選擇則是轉向去回答另一個問題:如果通過外部 Test-Time Scaling 來繼續實現模型性能的增長?
Best-of-N 范式是測試時擴展的一種典型代表:對于一個數學問題 , 模型生成 N 條推理路徑并從中選擇一項最有可能正確的路徑作為最終答案 , 如下圖所示:
【中關村學院新發現:輕量級驗證器可解鎖LLM推理最優選擇】
傳統實現 Best-of-N 的方法有兩種:
1. 投票法(Majority Voting):哪個答案出現最多就選哪個;
2. 過程獎勵模型(Process Reward Model , PRM):用一個額外的模型給每一步打分 , 再選總分最高的路徑 。
然而兩者都存在各自的問題:投票法相對粗糙 , 且近期的研究也發現 , “正確的答案往往存在于少數中” , 這也進一步揭示了投票法在 Best-of-N 任務中的不足;過程獎勵模型的相關方法則存在性能不穩定現象 , 這種現象源于當前的各類過程獎勵模型并非針對外部 Test-Time Scaling 和推理型模型所設計 , 從而導致了這些模型在應用于 Best-of-N 任務時存在明顯的魯棒性和性能問題 。
本文的研究試圖去彌補這類研究的缺陷 , 并提出了 TrajSelector 方法:一種輕量級但強大的 Best-of-N 策略 , 它通過復用大模型自身的 “隱藏狀態” 來評估推理路徑質量 , 無需昂貴的過程標注或 7B 參數的獎勵模型 , 就能在數學推理任務中取得顯著性能提升 。
論文標題:TrajSelector: Harnessing Latent Representations for Efficient and Effective Best-of-N in Large Reasoning Model 論文地址:https://arxiv.org/abs/2510.16449 項目主頁:https://zgca-ai4edu.github.io/TrajSelector/
TrajSelector:利用大模型隱狀態 , 解鎖大模型推理的 “最優選擇”
論文首先分析現有 Best-of-N 方法的兩個致命缺陷:
重量級過程獎勵模型(PRM)的成本太高:主流方法用 7B 參數的 PRM 給每個推理步驟打分 , 部署和推理成本幾乎和策略模型(比如 8B 的 Qwen3)持平 , 成本驟增; 模型隱狀態被浪費:另一些方法嘗試用策略模型的內在狀態評估答案 , 但這些狀態沒有被系統化利用 , 在不同任務上性能波動極大 , 可靠性差 。
為什么需要隱狀態?因為大模型的隱狀態里往往藏著 “自我反思信號”—— 比如解數學題時 , 某個步驟的隱狀態可能已經編碼了 “這個推導是否合理” 的信息 , 只是沒有被顯式利用 。
TrajSelector 的核心目標就是解決這兩個問題:用最小的參數開銷 , 充分利用策略采樣模型的隱狀態 , 實現 Effective 且 Efficient 的 Best-of-N 范式 。 該方法的架構圖如下:
TrajSelector 的框架非常簡潔 , 本質是 “并行采樣 - 步驟打分 - 聚合選優” 的三步流水線:
1. 并行采樣:使用一個凍結的策略模型進行并行采樣 , 得到多個推理路徑及其隱狀態 。
2. 步驟打分:TrajSelector 方法用一個僅 0.6B 參數的輕量級打分模型(即 Qwen3-0.6B-Base) , 通過復用策略模型的隱狀態給每個推理步驟打分 。 這種隱狀態的利用使得輕量級的小模型能夠復用來自于策略模型的編碼能力 , 使得在顯著減小模型參數規模的前提下 , 實現了更優的打分效果 。
3. 聚合選優:TrajSelector 使用了最簡單的算術平均來計算每個推理路徑的得分情況 , 得出每一個的全局分數 , 進行選擇出全局分數最高的路徑作為最終答案 。
訓練方案
傳統 PRM 需要大量 “步驟級標注”—— 比如人工給每個推理步驟標 “對 / 錯” , 成本極高 。 而 TrajSelector 的訓練完全不用手動標注 , 僅靠 “弱監督” 就能實現模型的訓練 。
訓練時的核心挑戰在于:一個最終正確的軌跡 , 未必每個步驟都正確(比如步驟有冗余 , 但結果對了) 。 如果直接把 “軌跡標簽” 當成 “步驟標簽” , 會引入大量噪聲 。 TrajSelector 借鑒了來自于 FreePRM 的損失函數設計方案 , 額外引入了一個 “buffer” 選項來吸收噪聲 , 從而設計出一個特殊的三分類損失函數:
對于標簽為 “正確” 的軌跡 , 要求模型預測 “正確 + 中性” 的概率和為 1(允許部分步驟是中性 , 吸收噪聲); 對于標簽為 “錯誤” 的軌跡 , 要求模型預測 “錯誤 + 中性” 的概率和為 1 。
這樣的訓練方案擺脫了對人工過程標注的依賴 , 從數據驅動的角度讓模型自主學習如何 “抓重點” , 在大規模數據的訓練下實現了一個智能且輕量級的過程驗證器 。
實驗效果
論文給出了 Best-of-N 任務中多個 N 值設置下的模型性能表現 , 包括 N = 1510163264, 基準選用了主流的 AMC23、AIME24、AIME25、BeyondAIME、HMMT25、BRUMO-25 等多個基準 。
下表給出了以 Qwen3-8B 為基座的 N=16 和 N=32 時 Best-of-N 表現:
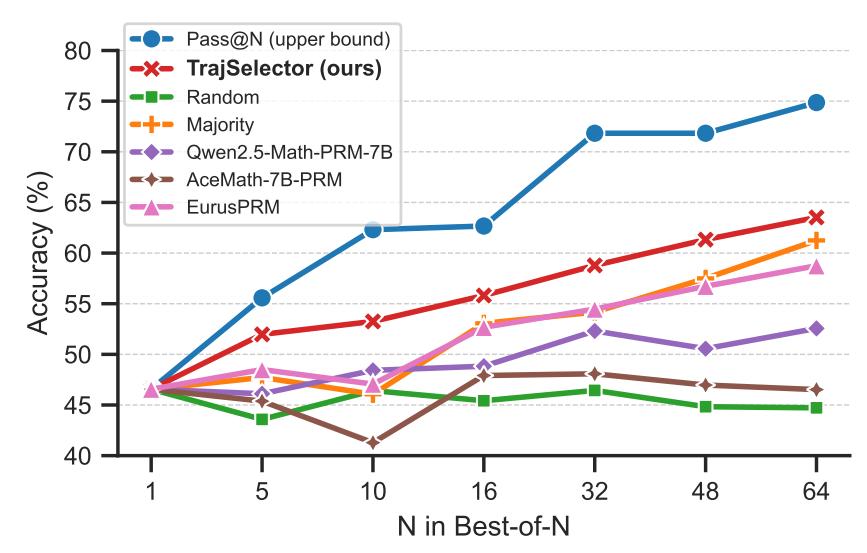
匯總各個 baselines 的平均表現 , 可以繪制出一個由 Best-of-N 實現的外部 Test-Time Scaling 曲線圖:
與各基線相比 , 隨著 N 的增大 , TrajSelector 方案實現了更穩定的性能增長 。
總結
TrajSelector 給大模型推理優化提供了一個重要思路:與其追求更大的模型 , 不如更聰明地利用現有模型的能力 。 它用 0.6B 的輕量級驗證器 , 實現了比 7B PRM 更好的效果 , 證明了 “隱藏狀態中的自我反思信號” 是未被充分挖掘的寶藏 。 對于需要落地大模型推理的場景(比如教育、科研計算) , TrajSelector 的高效性和低成本特性 , 讓 “Best-of-N” 從 “實驗室方案” 真正走向 “實用化” 。
推薦閱讀













- 雙核戰力在EVNIA!“我們學校潮好玩”落地安徽文達信息工程學院
- 雙核戰力 競在EVNIA!“我們學校潮好玩”落地安徽文達信息工程學院
- 擴散語言模型新發現:其計算潛力正在被浪費?
- 百度百科攜手《大學科普》、中國科學院大學科協發布科普專刊,面向全國高校發行
- AI會客廳實錄|對話北京中關村學院×中關村人工智能研究院何亮
- 中國科學院院士、北京大學電子學院院長:高性能二維半導體新突破
- 清華大學集成電路學院副院長唐建石:高算力芯片,如何突破瓶頸?
- 清華大學集成電路學院教授王志華:智能時代的中國集成電路
- 雷神x英偉達校園行!科技風暴席卷漢口學院
- 縱橫無拘,各有各的Young!飛利浦EVNIA攜《永劫無間》空降鄭州科技學院