
文章圖片

文章圖片
文章圖片

本文第一作者顧澤琪是康奈爾大學計算機科學四年級博士生 , 導師為 Abe Davis 教授和 Noah Snavely 教授 , 研究方向專注于生成式 AI 與多模態大模型 。 本項目為作者在英偉達實習期間完成的工作 。
想象一下 , 你是一位游戲設計師 , 正在為一個奇幻 RPG 游戲搭建場景 。 你需要創建一個 \"精靈族樹屋村落\"—— 參天古木和樹屋、發光的蘑菇路燈、半透明的紗幔帳篷... 傳統工作流程中 , 這可能需要數周時間:先手工建模每個 3D 資產 , 再逐個調整位置和材質 , 最后反復測試光照效果…… 總之就是一個字 , 難 。
這種困境正是當前 3D 內容創作領域的縮影 。 傳統 3D 設計軟件如 Blender、Maya 雖然功能強大 , 但學習曲線陡峭 。 近年來興起的文本生成 3D 技術讓用戶可以通過文字描述生成 3D 內容 , 但這些方法要么依賴有限的 3D 訓練數據 , 遇到新場景類型或風格就容易翻車 , 要么在預測完場景中的物體信息后 , 要從特定的 3D 模型池中尋找并調用出與預測特征最相近的 , 因此最后的場景質量非常依賴于模型池中到底有什么 , 很容易導致風格不統一 。
與此同時 , 文本生成 2D 圖像技術(如 GPT-4o、Flux)卻突飛猛進 。 這些模型通過海量互聯網圖像訓練 , 已經能生成布局合理、風格統一的復雜場景圖 。 這引發了一個關鍵思考:能否讓 2D 圖像充當 \"中間商\" , 先把用戶輸入文字轉化為高質量場景圖 , 再從中提取 3D 信息?NVIDIA 與康奈爾大學聯合團隊的最新研究 ArtiScene , 正是基于這一 insight 提出的全新解決方案 。
- 文章鏈接:https://arxiv.org/abs/2506.00742
- 文章網站:https://artiscene-cvpr.github.io/(代碼即將開源)
- 英偉達網站:https://research.nvidia.com/labs/dir/artiscene/
圖一:ArtiScene 生成的 3D 結果 。 從左到右的文字輸入分別是 , 第一行:(1) a Barbie-styled clinic room (2) a space-styled bedroom (3) a teenager-styled bathroom 。 第二行:(1) a cute living room (2) a garage (3) a operating room.
核心貢獻:無需訓練的智能 3D 場景工廠
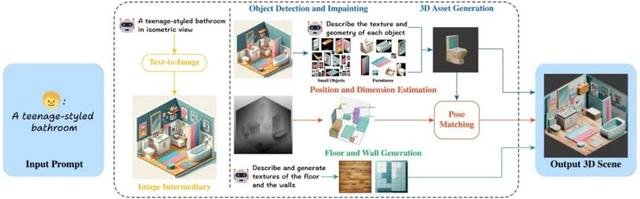
ArtiScene 的核心創新在于構建了一個完全無需額外訓練的自動化流水線 , 將文本生成圖像的前沿能力與 3D 重建技術巧妙結合 。 它一共包含五步:
1. 2D 圖像作為 \"設計藍圖\"
系統首先用擴散模型生成等軸測視角的場景圖 。 這種視角常用于建筑設計示意圖 , 因為它能同時呈現物體的長、寬、高信息 , 且不受場景位置影響 。 相比直接生成 3D , 這種方法能利用更成熟的 2D 生成技術確保布局合理性和視覺美感 。
圖二:和其他任意的相機視角(左二、三)比 , 讓文生圖模型輸出等軸測圖(左一)更可靠 , 因為等軸測圖默認相機參數是固定的 , 且沒有透視形變 。
2. 物體檢測與修復
采用兩階段檢測策略:先用 GroundedDINO 識別場景中的家具和裝飾品 , 對遮擋部分用補全修復(Remove Anything 模型) , 再次檢測確保完整性 , 最后得到每個物品的分割掩碼 。
3. 3D 空間定位
通過 Depth-Anything-2 模型估計深度信息 , 配合自定義投影公式將 2D 坐標轉換為 3D 位置 。 團隊發現傳統相機投影公式需要調整 , 于是采用去除深度縮放影響后的公式 。
4. 模塊化 3D 資產生成
傳統方法通常從現有數據庫檢索 3D 模型 , 導致美觀度受限 。 ArtiScene 則對場景圖中的每個物體分別生成定制化 3D 模型:在得到分割物體圖像后 , 讓 ChatGPT 描述其幾何特征 , 再輸入單視圖 3D 生成模型 , 為每件家具、裝飾品單獨建模 。
5. 場景組裝
通過單目深度估計 , 系統將 2D 邊界框轉換為 3D 空間坐標 。 并使用 \"渲染 - 比對\" 的姿勢估測機制 , 生成 8 個旋轉角度的物體渲染圖 , 用 Stable Diffusion+DINO-v2 融合模型提取特征 , 選擇與原始場景圖最匹配的姿勢 。 后處理階段還會自動修正物體重疊 , 確保物理上足夠合理 , 比如椅子不會嵌進餐桌里 , 花瓶能穩穩立在柜子上 。
圖三:系統流程圖
這種設計帶來三個顯著優勢:
?零訓練成本:完全利用現成模型 , 無需針對新場景類型微調
?風格無限:每個物體都按需生成 , 不受預制模型庫限制
?可編輯性強:單獨修改某個物體不會影響整體場景
實驗結果:全面超越現有方案
團隊在三個維度進行了系統評估:
1. 布局合理性測試
對比當時最強的 LayoutGPT , 在臥室和客廳場景中:
- 物體重疊率降低 6-10 倍(臥室 6.48% vs 37.26%)
- 用戶調研顯示 , 72.58% 的參與者更青睞 ArtiScene 的布局
- 生成家具數量更多(臥室平均 6.97 件 vs 4.30 件) , 且分布更自然
相比當時效果最好的文生 3D 場景方法 Holodeck , 在包含 29 種場景種類和風格的測試集中:
- CLIP 分數提高 10%(29.45 vs 26.73)
- GPT-4 評估中 , 95.46% 案例認為 ArtiScene 更符合描述
- 用戶調研顯示 , 82.96% 認為風格還原更準確
圖四:和之前的 SOTA Holodeck 的比較 。
3. 應用靈活性展示
系統支持多種實用功能:
- 物體編輯:單獨修改某個模型(如把普通汽車變成黃色保時捷)
- 多場景適配:通過調整參數支持戶外場景生成
- 人工引導:允許直接輸入手繪設計圖替代 AI 生成場景圖
圖五:左:物體編輯;右:跳過最開始的文生圖環節 , 直接用人工畫的圖生成場景 。
展望
對于更復雜的多房間場景(如整個博物館、醫院) , 或者要求特定家具間的位置關系和個數等用戶輸入 , 由于文生圖模型在訓練時就缺乏相關數據 , ArtiScene 在最開始就會受限于不夠優質的二維圖像 。 然而 , 這一模塊是可更換的 , ArtiScene 不依賴于某一特定模型 , 未來如果有性能更好的同功能模型 , 我們也可以很容易把它們替換進來 。
【零訓練實現3D場景生成SOTA:英偉達&康奈爾提出文本驅動新流程】本項目創新地采用二維圖像來引導三維場景生成 , 并用 LLM、VLM 等大模型構成了一個魯棒的系統 , 在生成結果的美觀度、多樣性和物理合理性上都遠超之前的同類型方法 。 作者希望他們的工作可以啟發未來更多關于具身智能、AR/VR、室內 / 室外設計的思考 。
推薦閱讀













- ColorOS設計總監陳希談iOS 26設計:實現低功耗、高流暢度是關鍵
- 零成本導演體驗,vivo S30 Pro mini希區柯克變焦實況手殘黨必試
- 「Next-Token」范式改變!剛剛,強化學習預訓練來了
- 蘋果iOS26實現安卓沒有的功能:讓AI更安全,降低AI創業門檻
- OpenAI新模型,被曝秘密訓練中,萬字硬核長文直指o4核心秘密
- 無線網絡漫游揭秘:移動終端如何實現AP間無縫切換?
- 上帝視角的昇騰MoE訓練智能交通系統讓訓練效率提升70%
- OpenAI久違發了篇「正經」論文:線性布局實現高效張量計算
- 硅谷的 AR 夢想,被華為實現了,但不是在眼鏡上
- 谷歌CEO皮查伊:AI才發展到AJI階段,實現AGI還需20年以上