文章圖片

文章圖片
文章圖片
文章圖片
機器之心報道
機器之心編輯部
Deep Cogito , 一家鮮為人知的 AI 初創公司 , 總部位于舊金山 , 由前谷歌員工創立 , 如今開源的四款混合推理模型 , 受到大家廣泛關注 。
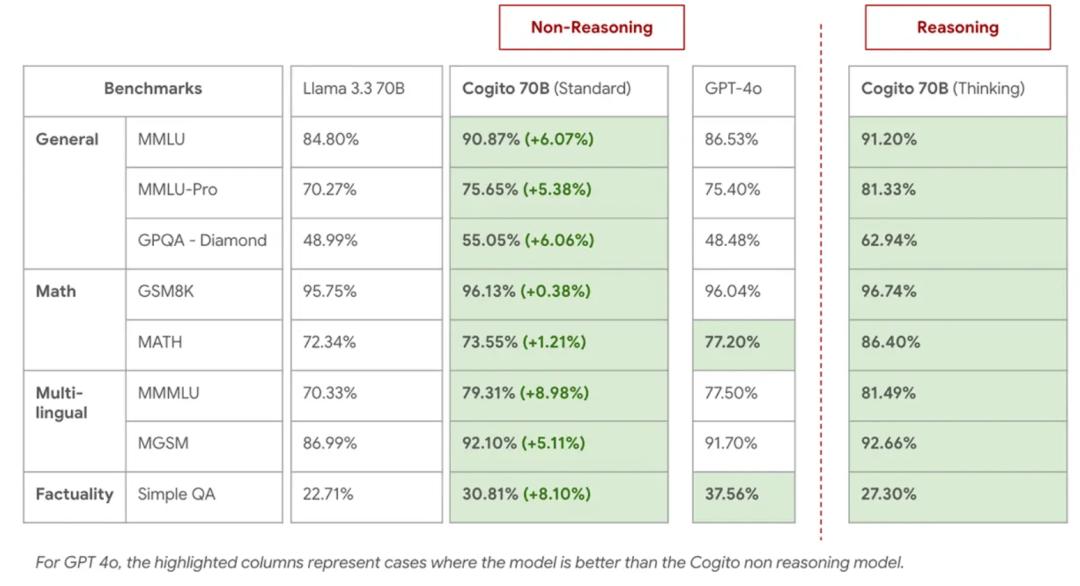
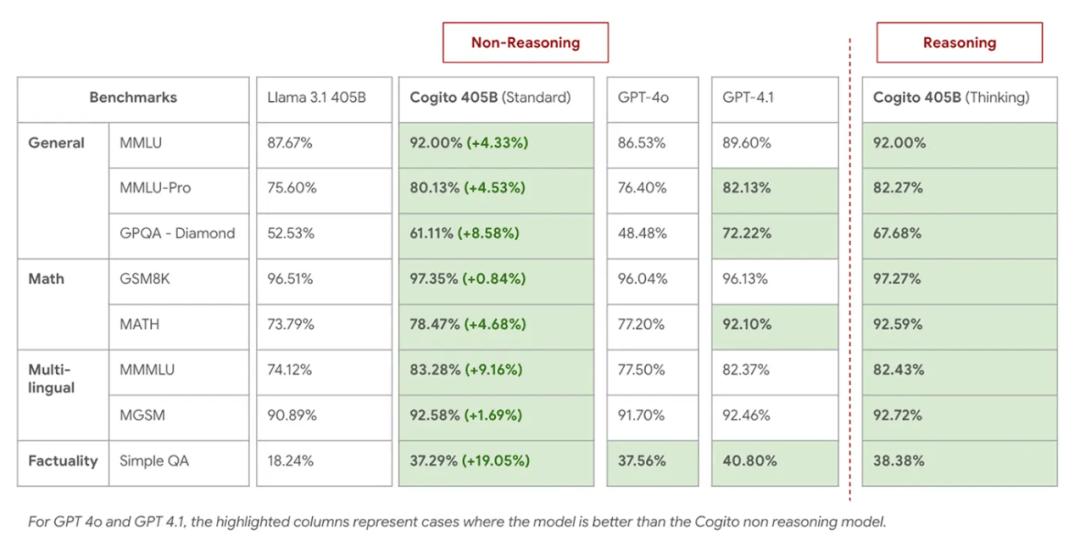
2 款中型 ——700 億參數稠密模型、1090 億 MoE 模型; 2 款大型 ——4050 億參數稠密模型、6710 億 MoE 模型 。每個模型都可以直接作答(標準 LLM 模式) , 也可以在作答前進行自我反思(類似推理模型) 。
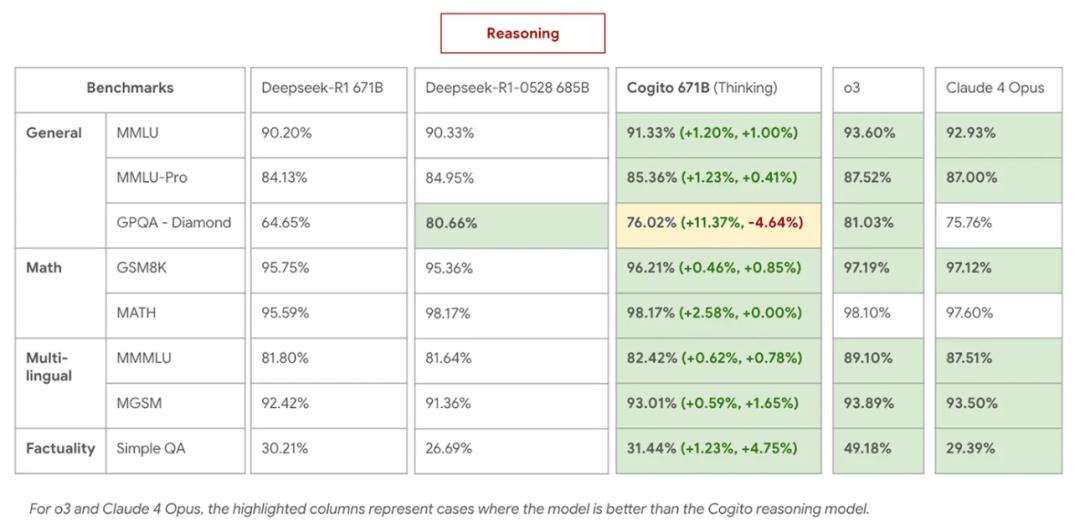
其中 , 最大規模的 671B MoE 模型是目前全球最強大的開源模型之一 , 其性能與最新的 DeepSeek v3 和 DeepSeek R1 模型相當甚至超越 , 且接近 o3 和 Claude 4 Opus 等閉源前沿模型 。
Deep Cogito 的核心方法是迭代蒸餾與增強(Iterated Distillation and Amplification , 簡稱 IDA) , 它不依賴手工設計的提示詞或靜態教師模型 , 而是利用模型自身不斷演化的洞察力來引導訓練 。
這一過程不是通過延長推理時間來提升性能 , 而是讓模型通過迭代式策略改進內化推理過程 。
這是一個全新的擴展范式 , 使模型逐漸形成更強的直覺 , 并成為 AI 自我提升(AI 系統自我改進)概念的有力驗證 。
由于 Cogito 模型在搜索過程中對推理路徑有更好的直覺 , 其推理鏈比 DeepSeek R1 縮短了 60% 。
【一個模型超了DeepSeek R1、V3,參數671B,成本不到350萬美元】與普遍認為技術創新需要大量基礎設施投入的觀點相反 , 這種方法效率極高 —— Cogito 系列模型(總共 8 個 , 本文是其中的 4 個)的訓練總成本不足 350 萬美元 , 其中已包含合成與人工數據生成、超過一千次訓練實驗的所有成本 。
現在 , 用戶可以在 Huggingface 上下載模型 , 或者直接通過 Together AI、Baseten 或 RunPod 上的 API 使用它們 , 或者使用 Unsloth 在本地運行它們 。
Huggingface 地址:https://huggingface.co/collections/deepcogito/cogito-v2-preview-6886b5450b897ea2a2389a6b
說到 Deep Cogito , 可能許多 AI 從業者近期才剛剛開始接觸這家公司 , Deep Cogito 實際上已經默默耕耘了一年多的時間 。
它于 2025 年 4 月正式走出隱身狀態 , 并發布了一系列基于 Meta 的 Llama 3.2 訓練的開源模型 。 那些早期發布的模型就已展現出頗具前景的表現 。
當時最小的 Cogito v1 模型(3B 和 8B)在多個評測基準上都超越了同尺寸的 Llama 3 模型 , 有時差距甚至相當明顯 。
Deep Cogito 的聯合創始人兼 CEO Drishan Arora , 此前是谷歌大語言模型核心工程師 。 他將公司的長期目標描述為:構建能夠像 AlphaGo 那樣通過每次迭代不斷進行推理和自我提升的模型 。
方法介紹
該研究最主要的目標是:將推理步驟蒸餾回模型的參數中 , 也就是把推理時的搜索過程轉化為模型的直覺 , 融入其內在能力中 。
今年早些時候 , Cogito v1 模型上線 , 該模型當時就使用了「迭代蒸餾與增強 」技術 。
今天發布的 Cogito v2 模型在這一研究路徑上進一步拓展到了更大規模的系統上 , 并將重點放在 IDA 的另一個關鍵部分上 —— 通過蒸餾實現自我改進 。
在多個特定領域(如國際象棋、圍棋和撲克) , AI 通過兩步循環(two-step loop)實現了超人類表現:
推理時計算:通過消耗算力來搜索解決方案; 策略迭代優化:將搜索發現的知識蒸餾到模型參數中 , 使得下次搜索更容易 。在這一模式下 , AlphaGo 是典型代表 , LLM 可視為同類系統 , 其推理時間計算雖比游戲系統更非結構化(通過生成答案前的「思考過程」實現) , 但要完成智能迭代提升的閉環 , 同樣需要關鍵的第二步驟 —— 策略迭代優化 。
也就是說 , 需要將推理過程蒸餾回模型參數中 , 使模型擁有更強的智能先驗 。 這意味著應當能夠以某種方式利用推理階段的思考過程 , 使模型本身變得更有能力或更聰明 。 模型應該能夠直接預測出推理的結果(而不是真的執行整個推理過程) , 并預判自身推理可能產生的結果 。
盡管近期的 LLM 在推理方面取得了一些進展 , 但這些進展大多是依賴于延長推理鏈條 , 而不是增強模型本身的智能先驗 。 因此 , LLM 性能的提升主要依賴于給模型更大的思考預算(即更多的推理 token) , 也就是多試幾種可能 , 而非模型對哪條搜索路徑更合適有真正的直覺 。 同樣地 , LLM 在非思考模式下的改進 , 也主要依賴于加入回溯等啟發式策略 , 其本質上與窮舉更多路徑沒有本質區別 。
提升模型本身的智能是一個更加困難的根本性問題 , 尤其是面對語言模型中那種非結構化的推理路徑 。 要解決這個問題 , 需要在迭代式策略改進方面取得技術性突破 。 Cogito v2 就是該研究在這個方向上邁出的下一步 。
該研究相信 , 在迭代式策略改進方向上持續研究 , 將有望實現遠超單純增加推理 token 所能帶來的模型能力躍升 。
評估
團隊公布了一些標準基準測試的評估結果 , 但特別強調 , 這些公開基準測試固然有其參考價值 , 但它們的結果與團隊的內部評估時常存在差異 。
在他們的內部評估中 , Cogito 模型的表現持續優于大多數開源模型 。 因此他們相信 , 自家模型在應對真實世界的應用和評估時會表現出色 。
此外 , 像 o3 和 Claude 4 Opus 這類前沿的閉源模型 , 它們的實力也早已超越了這些基準測試所能衡量的范疇 。
報告中還提到了一個有趣的「涌現能力」 。 盡管 Cogito v2 的訓練數據完全是文本 , 但由于其基座模型具備多模態能力 , 它似乎通過純粹的遷移學習 , 學會了對圖像進行復雜的邏輯推理 。
在一個示例中 , 模型在被要求對比兩張風馬牛不相及的圖片(一張鴨子和一頭獅子)時 , 其內部的「思考」過程清晰地展示了它如何分析圖像的構圖、色彩、主體、環境乃至情感氛圍 , 并最終給出了條理清晰的對比 。
這種未經專門訓練而自發產生的能力 , 為研究 AI 的泛化與學習機制提供了新的有趣視角 。 不過團隊尚未通過視覺基準測試評估此功能 。
基準測試結果
70B Dense
109B MoE
405B Dense
671B MoE(非推理)
671B MoE(推理)
參考鏈接:
https://www.deepcogito.com/research/cogito-v2-preview
推薦閱讀















- 光追破百幀有戲!聯發科天璣9500光追性能暴漲超40%
- 剛剛,小米又開源一大模型,22個公開測評SOTA
- 剛剛,谷歌「IMO金牌」模型上線Gemini,數學家第一時間證明猜想
- 實力超群的高端游戲本標桿——OMEN暗影精靈MAX
- 佳能燃動2025 ChinaJoy,超高人氣展臺引爆全場
- ARM:今年ARM芯片在超大規模數據中心市場份額接近50%
- AMD獨霸德國CPU市場!份額超90%、X3D爆款銷量32倍碾壓對手
- 別再入局大模型,除非你是馬斯克?OpenAI董事長90分鐘深度訪談
- 智譜發布新一代基座模型GLM-4.5:開源、高效、低價,專為智能體而生
- 具身智能實力派!十年多模態打底,世界模型開路,商湯悟能來了