文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片
文章圖片

文章圖片

文章圖片
金磊 發自 凹非寺
量子位 | 公眾號 QbitAI
沒能等到GPT-5 , 但OpenAI在深夜卻很突然地open了一下——
開源兩個推理模型:gpt-oss-120b和gpt-oss-20b 。
要知道 , 上一次OpenAI開源模型還是6年前 , 也就是2019年的GPT-2 。
而這次的名字也是非常的直接 , gpt-oss , 即Open Source Series , 意思就是“開源系列” 。
它們的亮點如下:
gpt-oss-120b:1170億參數(MoE架構 , 激活參數約51億) , 可在單張80GB GPU上運行 , 性能接近閉源的o4-mini 。 gpt-oss-20b:210億參數(Moe架構 , 激活參數約36億) , 可在16GB內存的消費級設備上運行 , 性能接近o3-mini 。并且它倆均采用Apache 2.0許可證 , 允許商用無需付費或授權 。
從性能角度來看 , gpt-oss已經達到了開源模型里推理性能的第一梯隊 , 但在代碼生成和復雜推理任務中仍略遜于閉源模型(如GPT-o3和o4-mini) 。
在模型發布的第一時間 , Sam Altman在自己的社交平臺上也道出了這倆模型的“價值”:
可以在本地筆記本(20b的可以在手機上)運行;耗資數十億美元的研究成果 。
并且蘇媽(Lisa Su)也是幾乎同時出來為Altman站臺 , 表示“很榮幸成為第0天的合作伙伴” 。
不過有意思的是 , 在官方HuggingFace介紹中 , 提及的卻是英偉達的H100……
先看效果在開源動作一個小時后 , OpenAI官方還放出了一個實測效果的視頻 。
這次講解的人員 , 分別是在OpenAI負責開發者體驗的Dom和Zhaohan:
他倆是在一臺120G的Macbook Pro上進行的測試 , 借助Ollama在本地運行120B的gpt-oss(搭了2塊H100) 。
二人先小試牛刀 , 測試了一下gpt-oss在思維鏈中調用工具的能力 , 即搜索+Python解釋器 。
他們在開啟Browser Tool和Python Tool后 , 在本地提問:
舊金山天氣如何?
可以看到 , 本地的gpt-oss-120b穩穩地輸出了正確的結果 。
在第二個測試例子中 , 他們讓2個非常大的數字相乘 。
在這個過程中 , 可以看到gpt-oss一次又一次地調用Python工具 , 雖然中間有出錯的情況 , 但最終給到了正確的答案 。
接下來 , 二人把網直接斷掉 , 在本地搞了一個射擊類的小游戲:
同樣是在斷網的情況下 , 他倆又經過一番操作 , 將游戲中的圖標變成了草莓的樣式:
整體來看 , 實測的體感還是比較絲滑的 , 并且生成速度達到了40-50 tokens/s 。
完整體驗視頻如下:
視頻地址:https://mp.weixin.qq.com/s/bIaUXw9XWR2Sb4dy4i37_Q
再看性能除了實測效果之外 , OpenAI也一道發布了gpt-oss相關的技術博客 。
整體來看 , 這兩個模型在工具使用、少樣本函數調用、鏈式思考推理(如Tau-Bench智能評估套件的結果所示)以及HealthBench上表現強勁 , 甚至超越了包括OpenAI o1和GPT?4o在內的專有模型 。
預訓練與模型架構
gpt-oss模型使用的OpenAI最先進的預訓練和后訓練技術進行訓練 , 特別關注推理、效率和在廣泛部署環境中的實際可用性 。
雖然OpenAI已經公開了包括Whisper和CLIP在內的其他模型 , 但gpt-oss模型是自GPT?2以來的第一個開放權重語言模型 。
每個模型都是一個Transformer , 利用專家混合(MoE)來減少處理輸入所需的活躍參數數量 。
gpt-oss-120b每個token激活5.1B個參數 , 而gpt-oss-20b激活3.6B個參數 。 這些模型分別具有117b和21b的總參數 。
這些模型使用類似GPT?3的交替密集和局部帶狀稀疏注意力模式 。
為了提高推理和內存效率 , 模型還使用分組多查詢注意力 , 組大小為8 。 團隊使用旋轉位置嵌入(RoPE)進行位置編碼 , 并原生支持最長128k的上下文長度 。
團隊在主要由英語文本組成的數據集上訓練這些模型 , 重點關注STEM領域、編程和通用知識 。
OpenAI使用一個超集(superset)分詞器對數據進行分詞 , 該分詞器基于OpenAI o4-mini和GPT?4o使用的分詞器:o200k_harmony , 今天也將開源這一分詞器 。
后訓練階段
這些模型采用與o4-mini相似的流程進行了后訓練 , 包括有監督微調階段和高算力的強化學習階段 。
OpenAI的目標是使模型符合OpenAI 模型規范的要求 , 并在生成答案之前學會使用鏈式思維(CoT)和工具調用 。
在后訓練過程中 , 團隊采用了與OpenAI最先進專有推理模型相同的技術 , 使這些模型展現出了卓越的能力 。
與API中OpenAI o系列推理模型類似 , 這兩個開源權重模型支持三種推理強度——低、中、高——在延遲與性能之間實現權衡 。
開發者可以通過系統提示語中的一句話 , 輕松設定所需的推理強度 。
評估結果團隊對gpt-oss-120b和gpt-oss-20b進行了標準學術基準測試評估 , 衡量它們在編程、競賽數學、健康問答和Agent工具使用等方面的能力 , 并與OpenAI的其他推理模型(包括 o3、o3-mini 和 o4-mini)進行了對比 。
在競賽編程(Codeforces)、通用問題解決(MMLU和HLE)以及工具調用(TauBench)方面 , gpt-oss-120b的表現優于OpenAI的o3-mini , 并達到或超過了o4-mini的水平 。
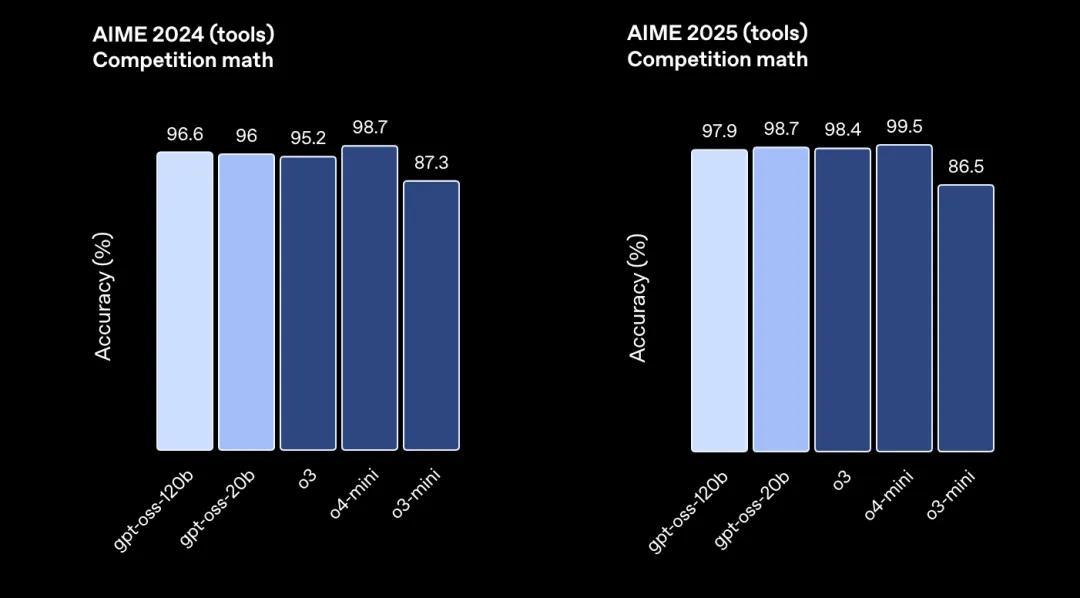
在健康相關問答(HealthBench)和競賽數學(AIME 2024 與 2025)上 , gpt-oss-120b的表現甚至超越了o4-mini 。
盡管體積較小 , gpt-oss-20b在同樣的評估中也達到了或超過了OpenAI o3-mini的水平 , 尤其在競賽數學和健康問答方面表現更加出色 。
思維鏈
OpenAI最近的研究表明 , 在模型的鏈式思維(CoT)未經過直接監督對齊訓練的前提下 , 監測其推理過程的CoT有助于識別不當行為 。
遵循自發布OpenAI o1-preview以來的一貫原則 , 團隊在gpt-oss模型上并未對CoT進行任何形式的直接監督 。
OpenAI認為 , 這一點對于監測模型的不當行為、欺騙行為及濫用情況至關重要 。
團隊希望 , 通過發布一個未經過監督對齊的開源模型 , 能夠為開發者和研究人員提供機會 , 自主研究并實現各自的 CoT 監測機制 。
開發者不應在其應用中將模型的鏈式思維內容直接展示給用戶 。
因為這些內容可能包含虛構或有害信息 , 其中的語言可能不符合OpenAI的安全標準 , 甚至可能泄露模型被明確指示不得在最終輸出中包含的信息 。
OpenAI為什么要開源?在技術博客的最后 , OpenAI也對今天開源的動作 , 做出了解釋 。
在OpenAI看來 , gpt-oss-120b和gpt-oss-20b的發布 , 是開源權重模型向前邁出的重要一步 。
以其體量 , 這兩款模型在推理能力和安全性方面都實現了實質性提升 。
開源模型是對OpenAI托管模型的重要補充 , 為開發者提供了更豐富的工具選項 , 加速前沿研究 , 推動創新 , 并支持更安全、透明的AI開發 , 適用于更廣泛的使用場景 。
這些開源模型還降低了新興市場、資源受限行業以及中小型組織進入AI的門檻——這些組織可能缺乏采用專有模型所需的預算或靈活性 。
如今 , 全球更多人可以借助這些強大、易獲取的工具進行建設、創新 , 并為自己和他人創造新的機會 。 開放獲取這些在美國開發的高能力模型 , 有助于推動AI發展走向更加民主化 。
一個健康的開源模型生態 , 是實現AI普及并惠及全人類的重要維度之一 。
One More Thing:雖然但是……網友們最最最最關心的似乎還是——
GPT-5呢????
【OpenAI開源2個推理模型:筆記本/手機就能跑,性能接近o4-mini】
技術博客地址:https://openai.com/index/introducing-gpt-oss/
HuggingFace地址:https://huggingface.co/openai/gpt-oss-120b
GtiHub地址:https://github.com/openai/gpt-oss
— 完 —
量子位 QbitAI · 頭條號
關注我們 , 第一時間獲知前沿科技動態
推薦閱讀













- 就是阻擊OpenAI,Claude搶先數十分鐘發布Claude Opus 4.1
- 華為重要官宣:全面開源!與英偉達上演“龍虎斗”?
- 手機也能跑,騰訊混元一口氣開源4款小模型
- 阿里開源兩款4B小模型:手機電腦都能用,比GPT-4.1-nano還強
- OpenAI或在周五凌晨發布GPT-5 有望較現有模型好得多
- 美國不甘落后!啟動ATOM計劃:直指中國“千問”開源AI領先地位
- OpenAI被“斷供”,AI圈也搞起了以鄰為壑
- 為更好與英偉達CUDA競爭,華為CANN全面開源
- 騰訊AI Lab開源可復現的深度研究智能體,最大限度降低外部依賴
- 剛剛,OpenAI發布2款開源模型!手機筆記本也能跑,北大校友扛大旗