
文章圖片

文章圖片
文章圖片
文章圖片
【小扎又開源了:7B實現自監督學習SOTA】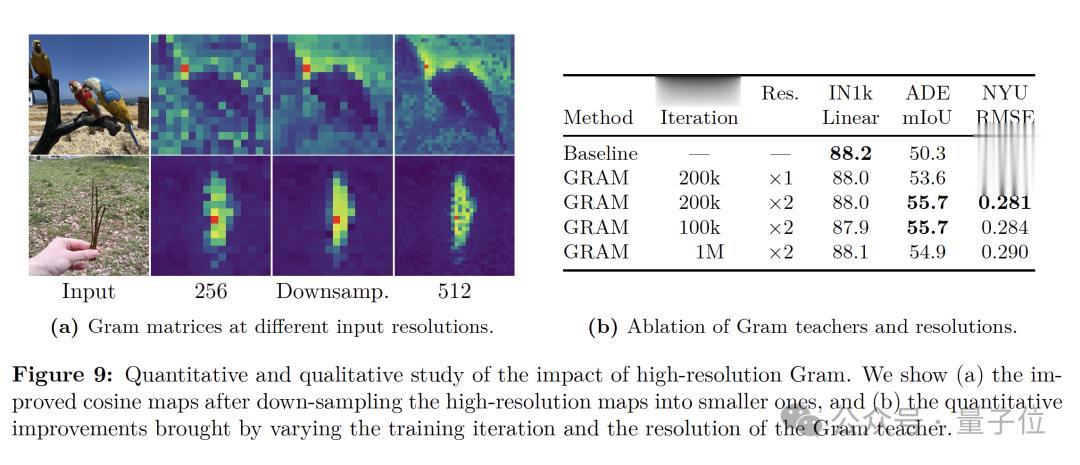
文章圖片
文章圖片

文章圖片
henry 發自 凹非寺
量子位 | 公眾號 QbitAI
剛剛 , Meta發布了全新開源視覺模型DINOv3——
首次證明了自監督學習模型能夠在廣泛任務中超越弱監督學習模型 。
DINOv3采用無標注方法 , 將數據規模擴展至17億張圖像、模型規模擴展至70億參數 , 并能高效支持數據標注稀缺、成本高昂或無法獲取的應用場景 。
DINOv3不僅在缺乏標注或跨領域的場景(網絡圖像與衛星影像)中表現出絕對的性能領先 , 還在計算機視覺三大核心任務(分類、檢測、分割)上實現了SOTA 。
網友表示:我還以為你們已經不行了 , 好在你們終于搞出點東西來了 。
計算機視覺的自監督學習說起計算機視覺 , 就繞不開李飛飛老師推動的ImageNet和大規模標注數據 。
然而 , 隨著數據量的激增以及應用場景不斷擴展 , 標注成本和可獲取性成為了制約視覺模型通用性的主要因素 。
基于這一思路 , DINOv3采用了創新的自監督學習方法 , 專注于生成高質量且高分辨率的視覺特征 , 為下游視覺任務提供強大的骨干模型(backbone)支持 。
通過這一方法 , DINOv3首次實現了單一凍結視覺骨干網絡(Single Frozen Vision Backbone)在多項密集預測任務(Dense Prediction Tasks)中超越專門化解決方案的性能 。
那么 , DINOv3是怎么做到的?
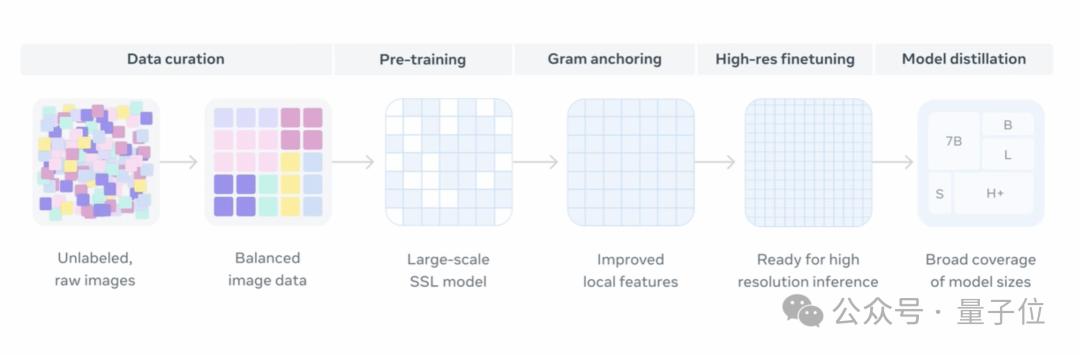
總的來說 , DINOv3的訓練過程分為兩個主要階段:
DINOv3在一個龐大且精心構建的數據集上進行大規模自監督訓練 , 從而學習到通用且高質量的視覺表示 引入名為“Gram anchoring”的新方法來解決訓練中密集特征圖的退化問題 , 在不影響全局特征的同時 , 顯著提升局部特征的質量
具體來說 , 研究者首先構建了一個包含約17億張圖片的預訓練數據集 。
這些圖片數據主要來自Instagram上的公開圖片 , 以及少量來自ImageNet的圖片 。
在對數據集進行分類、采樣后 , 研究者采用判別式自監督(Discriminative Self-supervised) , 通過Sinkhorn-Knopp算法和Koleo正則穩定特征分布 , 實現了細粒度又穩健的密集特征學習 。
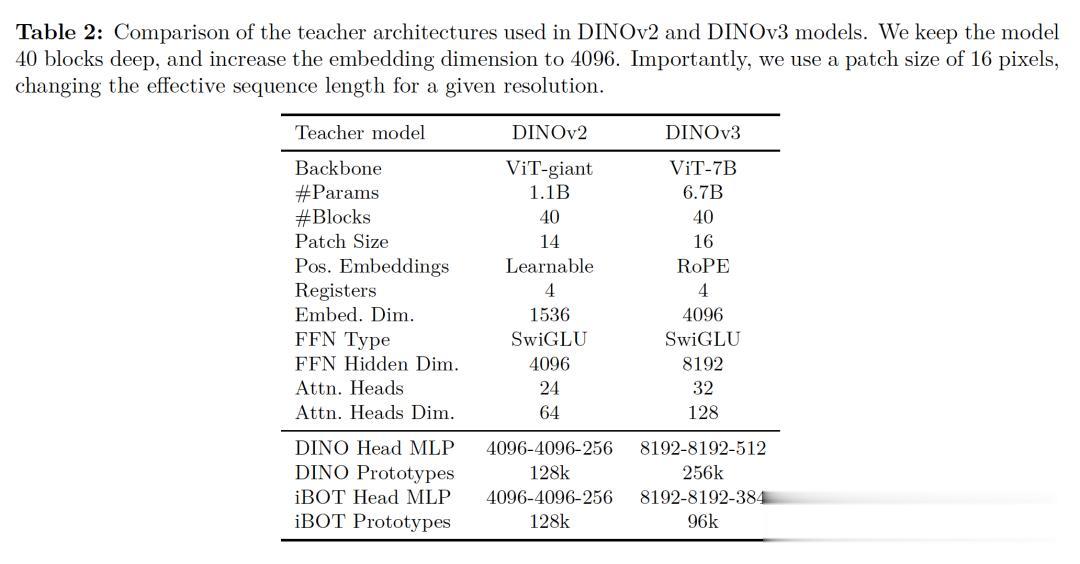
此外 , 在繼承DINOv2成功方法的基礎上 , DINOv3將模型參數從11億擴展至70億 , 以增強骨干網絡的表示能力 , 從而能夠從海量圖像中學習更豐富、細粒度的視覺特征 。
相比v2 , DINOv3在訓練策略上引入了RoPE-box jittering , 使模型對分辨率、尺度和長寬比變化更具魯棒性 , 同時保留多裁剪訓練和恒定學習率+EMA教師動量優化的做法 , 確保訓練穩定且高效 。
在大規模訓練中 , DINOv3的70億參數模型可以通過長時間訓練顯著提升全局任務性能 , 因此研究者在最初就寄希望于長時間訓練 。
然而 , 密集預測任務(如圖像分割)往往會隨著訓練迭代次數的增加而下降 , 而這種退化主要源于patch-level(補丁級別)特征的一致性喪失:
隨著訓練進行 , 原本定位良好的patch特征逐漸出現不相關patch與參考patch相似度過高的現象 , 從而削弱了模型在密集任務中的表現 。
為了應對這一問題 , 研究團隊提出了“Gram anchoring”方法 , 即通過將學生模型的patch Gram矩陣逼近早期訓練階段表現優異的教師模型的Gram矩陣 , 來保持patch間的相對相似性 , 而不限制特征本身的自由表達 。
實驗表明 , 在應用Gram anchoring后 , ADE20k分割任務有著顯著的提升 , 且訓練穩定性明顯增強 。
這表明保持patch-level一致性與學習判別性全局特征之間可以有效協調 , 而在有針對性的正則化下 , 長時間訓練也不再犧牲密集任務表現 。
此外 , 通過將高分辨率圖像輸入到Gram教師并下采樣至與學生輸出相同的尺寸 , 仍然獲得了平滑且一致的patch特征圖 。
實驗結果顯示 , 即便經過下采樣 , 高分辨率特征中優越的patch-level一致性仍得以保留 , 從而生成更加平滑、連貫的patch表示 。
最后 , 由于DINOv3在最初訓練時使用了相對較低的分辨率(256×256) , 為了讓模型適應高分辨率的圖像場景 , 研究團隊在訓練后增加了一個“高分辨率適應步驟” , 從而讓模型在學會處理更大尺寸圖像的同時 , 還能保持性能穩定 。
在這一適應步驟中 , DINOv3結合了“混合分辨率”(mixed resolutions)策略與Gram anchoring方法 , 使模型在處理更大、更復雜的圖像時仍能保持穩定且精細的特征表示 , 同時兼顧全局任務與密集預測任務的性能 。
最后 , 為了驗證DINOv3的性能 , 研究團隊在包含密集特征、全局特征任務在內的多個計算機視覺任務上對DINOv3 7B模型進行了評估 。
就像我們在開頭提到的 , DINOv3在語義分割、單目深度估計、非參數方法、3D對應估計等任務中實現了SOTA 。
值得一提的是 , 由于DINOv3強大的通用性 , 它還消除了研究人員與開發者為了特定任務而對模型進行微調的必要 。
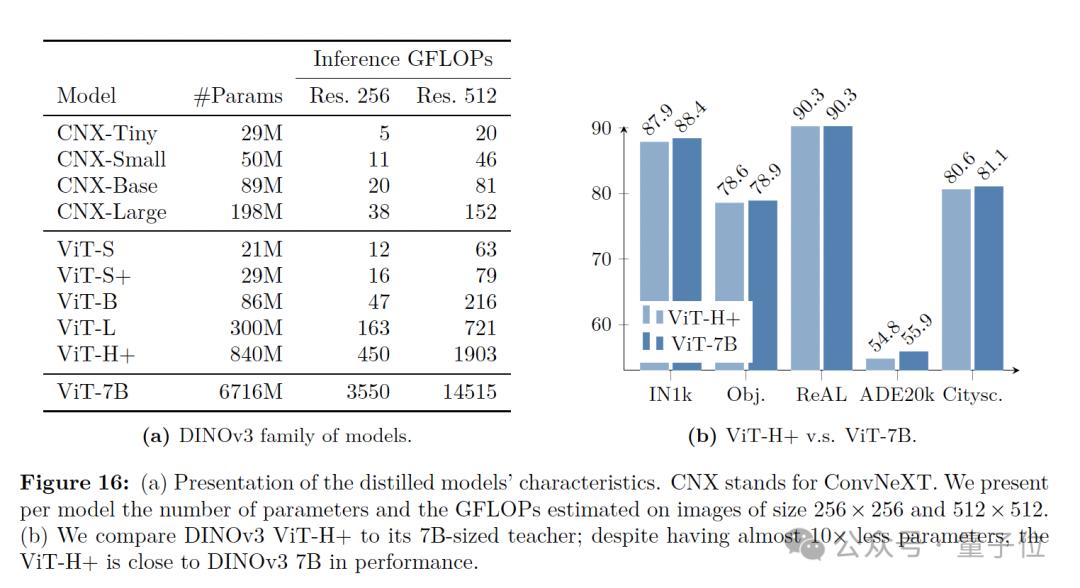
此外 , 為了方便社區部署 , Meta還通過蒸餾原生的70億參數模型DINOv3 , 構建了一個開發環境友好的v3模型矩陣:VisionTransformer(ViT)的Small、Base和Large版本 , 以及基于ConvNeXt的架構 。
其中 , ViT-H+模型在各種任務上取得了接近原始70億參數教師模型的性能 。
據悉 , Meta也透露將發布具體的蒸餾流程 , 以便社區能夠在此基礎上繼續構建與改進 。
DINO行動在實際應用中 , DINOv3也展現了強大的泛化能力 。
例如 , 在與世界資源研究所(WRI)合作中 , Meta利用DINOv3開發了一種算法 , 能夠利用DINOv3分析衛星影像 , 檢測受影響生態系統中的樹木損失與土地利用變化 。 為全球森林恢復和農業管理提供了強有力的技術支持 。
與DINOv2相比 , 在使用衛星與航空影像進行訓練的情況下 , DINOv3將肯尼亞某地區樹冠高度測量的平均誤差從4.1米降低至1.2米 。
除此此外 , DINOv3還在多個遙感任務(包括語義地理空間任務和高分辨率語義任務等)中取得了SOTA 。
最后 , DINO(Distillation With NO Labels)系列作為Meta對視覺領域自監督方法的探索 , 可以說是一脈相承 , 繼往開來 , 標志著視覺模型大規模自監督訓練的持續進步 。
從DINO的初步研究概念驗證 , 使用100萬張圖像訓練8000萬參數的模型 ,
到DINOv2中基于1.42億張圖像訓練的1B參數模型 , SSL算法的首次成功擴展 ,
再到如今DINOv3的70億參數和17億張圖片 ,
Meta的這套自監督訓練方法有望引領我們邁向更大規模、通用性更強 , 同時更加精準且高效的視覺理解 。
就像Meta在技術文檔中所描述的:
DINOv3不僅可以加速現有應用的發展 , 還可能解鎖全新的應用場景 , 推動醫療健康、環境監測、自動駕駛、零售以及制造業等行業的進步 , 從而實現大規模、更精準、更高效的視覺理解 。
參考鏈接[1
https://huggingface.co/docs/transformers/main/en/model_doc/dinov3[2
https://x.com/AIatMeta/status/1956027795051831584[3
https://github.com/facebookresearch/dinov3[4
https://ai.meta.com/blog/dinov3-self-supervised-vision-model/?utm_source=twitterutm_medium=organic_socialutm_content=videoutm_campaign=dinov3[5
https://ai.meta.com/research/publications/dinov3/
— 完 —
量子位 QbitAI · 頭條號簽約
關注我們 , 第一時間獲知前沿科技動態
推薦閱讀












- 百元價卻有旗艦體驗?南卡OE Nova:性價比開放式耳機,舒服又好聽
- 谷歌開源Gemma 3 270M,性能超越Qwen 2.5同級模型
- 谷歌版小鋼炮開源!0.27B大模型,4個注意力頭,專為終端而生
- 14英寸高顏筆記本怎么選?推薦華碩天選Air 2025,好看又好用
- Meta視覺基座DINOv3王者歸來:自監督首次全面超越弱監督,商用開源
- “隱語”開源社區升級!將覆蓋六大技術路線
- 又是北大校友!ChatGPT Agent華人研發主力被Meta挖走了
- AI圖像水印失守,開源工具5分鐘內抹除所有水印
- AI圖像水印失守!開源工具5分鐘內抹除所有水印
- 一年半改名3次!“董明珠健康家”公眾號又改叫“格力好物指南”