文章圖片

文章圖片
文章圖片
一個月前 , 微軟為玩家帶來了AI游戲助理Gaming Copilot , 幫助玩家應對高難度任務、提升游戲技能 , 以及詳細講解游戲內容 。 就在大家喜迎微軟的這個“AI游戲搭子”時 , 有較真的玩家卻發現 , Gaming Copilot居然是“特洛伊木馬” 。
隨著最近一次更新 , 自動安裝在玩家電腦上的Gaming Copilot被海外游戲論壇ResetEra的用戶發現 , 會自動上傳游戲截圖和錄屏內容 。 在Gaming Copilot AI的隱私設置中 , “文本模型訓練”選項是默認開啟狀態 。 當然 , 這位用戶也欣慰地表示 , 微軟還沒有徹底喪心病狂 , 收集用戶對話語音的選項暫時處于未開啟狀態 。
這次消息一出 , 瞬間就讓玩家社區一片嘩然 。 原本以為Gaming Copilot的存在可以讓自己隨時召喚AI來解決游戲過程中遇到的問題 , 不再需要頻繁切出游戲查攻略 , 結果Gaming Copilot居然是一個隱藏的“間諜” , 目的居然是圖謀大家的隱私數據 。
只能說微軟在“坑”游戲玩家這件事上幾乎已經形成了習慣 , 此前的“Edge游戲助手”讓電腦變卡也就罷了 , 如今的Gaming Copilot更是將玩家當“人肉電池” 。 這一次Gaming Copilot悄悄收集數據并非微軟的無心之舉 , 而是有意為之 , 為的就是讓玩家在不經意間將數據交出去 。
關于微軟為何要“口蜜腹劍” , 看完接下來這個消息 , 許多朋友想必就會明白 。 就在Gaming Copilot被玩家發現會自動上傳數據的幾乎同一時間 , “美國貼吧”Reddit在紐約聯邦法院起訴了AI搜索獨角獸Perplexity AI , 指控后者通過“工業規模的非法抓取”行為 , 未經許可復制Reddit用戶的評論以牟取商業利益 。
數據如同化石燃料般正在枯竭、AI革命正“吸干”互聯網數據的海洋 , 這是AI專業人士自去年就開始不斷發出的警告 。 而在2025年 , AI業界更是出現了一個有趣的現狀 , 那就是各大AI廠商的大模型不約而同地放棄了通用化、開始追逐差異 , 諸如OpenAI的GPT-5長于搜索、谷歌的Gemini 2更擅長數學、Anthropic的Claude 4則精通代碼 。
事實上 , 不同廠商的AI大模型各有所長 , 是因為他們在RLHF(基于人類反饋的強化學習)上的差異 。 據OpenAI前首席科學家Ilya Sutskever的說法 , 決定RLHF階段性效果的除了算法之外 , 數據的質量更是一個決定性因素 。 這背后其實就反映出了這樣一個現實 , 即AI大模型的迭代從純粹的參數規模膨脹 , 已經轉向了萃取高質量數據 。
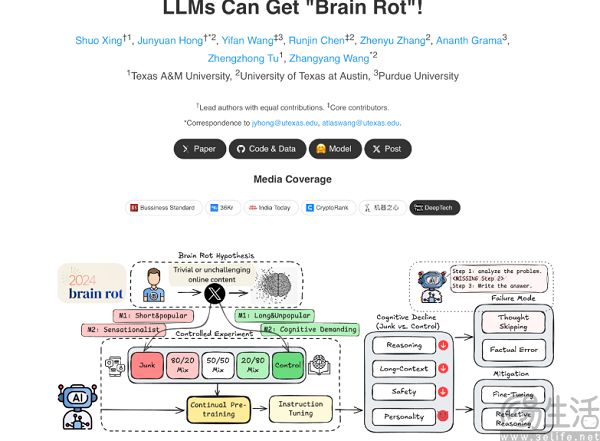
AI大模型的訓練本就依賴海量數據 , 可如果輸入的數據存在錯誤 , 訓練出來的模型自然也就會“學壞” , 輸出的結果同樣是“垃圾” 。 沒錯 , 與人類一樣 , 一旦接觸低質信息過多 , 大模型也會出現認知退化的“腦腐”(Brain Rot)現象 。
大模型持續暴露于垃圾數據的具體表現 , 就是推理能力下降、長上下文理解能力變差、倫理規范意識減弱等系統性的退化 , 并且這一趨勢是不可逆的 , 難以通過后期的微調修復 。 為了避免自家大模型不進反退 , 各大AI廠商自然也就開始千方百計地尋求高質量的數據 。
但遺憾的是 , 論文、書籍等高質量數據已經被消耗殆盡 。 由于AI廠商一口氣揮霍了過去三十年間互聯網世界積累的絕大部分知識 , 才造就了AI大模型在過去兩年迎來“寒武紀生命大爆發” 。 現在凝聚了人類智慧結晶的高質量數據斷供 , AI廠商就被迫在沙海淘金 , 盡管Reddit的社交數據、Gaming Copilot所收集的玩家行為數據確實質量堪憂 , 但好歹也是產出有保證的數據 。
如今矛盾之處 , 就在于不僅僅是AI廠商認識到了一切數據都有價值 , Reddit這樣的數據擁有者也一樣 。 從某種意義上來說 , AI初創企業的至暗時刻其實是2025年 , 因此在此之后 , 巨頭和初創企業獲取數據能力的差異 , 會讓后者再無彎道超車的機會 。
以微軟和Perplexity AI為例 , 在合法合規的情況下 , 前者獲取數據的能力顯然是碾壓后者 。 畢竟微軟旗下的產品極為豐富 , 諸如Office可以貢獻辦公數據、Gaming Copilot能帶來游戲數據 , 因此就是的微軟能收集大而全的數據 。
可反觀Perplexity AI , 盡管作為AI搜索獨角獸、并非AI賽道的無名之輩 , 甚至他們的AI搜索引擎還一度讓谷歌搜索左支右絀 。 可Perplexity AI只有AI搜索這一個產品 , 就注定了他們只能從1500萬活躍用戶身上取得數據 。 如果僅僅從自家用戶身上獲取數據 , Perplexity AI就注定將迎來“加拉帕戈斯化” , 指的就是在孤立的市場環境下獨自進行“最適化” , 從而喪失與區域外的互換性 , 進而導致產品與主流需求脫節 。
如果Perplexity AI不向外“掠奪”數據 , 他們的AI出現“腦腐”的概率自然就要遠高于微軟的Copilot 。 簡而言之 , AI賽道百舸爭流、千帆競逐的場面 , 很有可能會在未來一兩年內結束 。 因為擁有數據的內容平臺不會再讓AI廠商平白無故地拿走數據 , 這就會導致缺乏資金的初創企業失去了數據源 。
【“搞數據”這件事,已經成為了AI行業的頭等大事】畢竟當微軟等AI大廠能利用旗下各種產品悄悄獲取用戶數據 , 而Perplexity AI等初創企業只能去“搶”的情況下 , 長此以往 , 雙方的差距就只會越來越大 。
推薦閱讀












- 讓機器人指尖“看懂”觸感,全球最薄可商用仿生視觸覺傳感器亮相IROS!
- 黑鉆會員也“免費”,美團主動讓用戶薅羊毛
- 華為售價“大跳水”,16GB+512GB跌價1900元,高端旗艦“加速清倉”
- 榮耀“亂套了”,從3199元跌至1363元,頂配版也降成“千元機”
- 紅米打響“價格戰”,186萬分+6550mAh+2米防水,現已跌至1289元
- 一加“用力過猛”,16GB+1TB跳水1123元,頂配版旗艦跌至“冰點價”
- 2025機圈春晚上演:內卷洪流下,他們卻“四兩撥千斤”
- 阿里夸克“C計劃”再曝新動向:一款AI 瀏覽器或年底發布
- 美團AI,被“逼”到臺前
- OPPO回應“綠線門”事件:購機4年內免費更換屏幕